 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Doubly Robust Approach to Sparse Reinforcement Learning
Paper and Code
Oct 23, 2023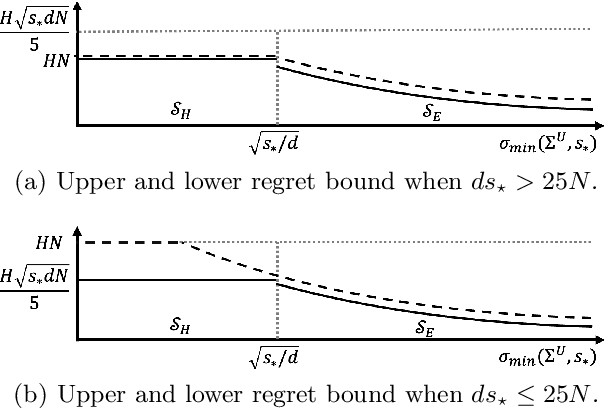
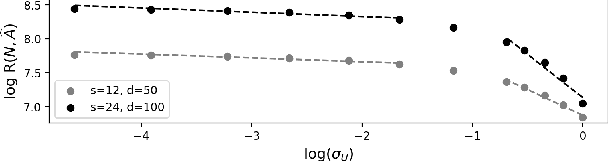
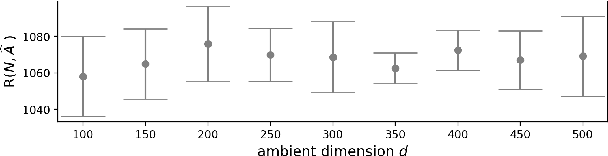
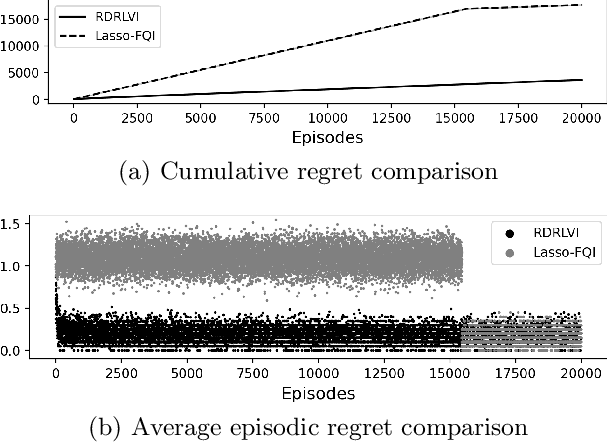
We propose a new regret minimization algorithm for episodic sparse linear Markov decision process (SMDP) where the state-transition distribution is a linear function of observed features. The only previously known algorithm for SMDP requires the knowledge of the sparsity parameter and oracle access to an unknown policy. We overcome these limitations by combining the doubly robust method that allows one to use feature vectors of \emph{all} actions with a novel analysis technique that enables the algorithm to use data from all periods in all episodes. The regret of the proposed algorithm is $\tilde{O}(\sigma^{-1}_{\min} s_{\star} H \sqrt{N})$, where $\sigma_{\min}$ denotes the restrictive the minimum eigenvalue of the average Gram matrix of feature vectors, $s_\star$ is the sparsity parameter, $H$ is the length of an episode, and $N$ is the number of rounds. We provide a lower regret bound that matches the upper bound up to logarithmic factors on a newly identified subclass of SMDPs. Our numerical experiments support our theoretical results and demonstrate the superior performance of our algorithm.