 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssouad, Fano, and Le Cam with Interaction: A Unifying Lower Bound Framework and Characterization for Bandit Learnability
Oct 07, 2024In this paper, we develop a unified framework for lower bound methods in statistical estimation and interactive decision making. Classical lower bound techniques -- such as Fano's inequality, Le Cam's method, and Assouad's lemma -- have been central to the study of minimax risk in statistical estimation, yet they are insufficient for the analysis of methods that collect data in an interactive manner. The recent minimax lower bounds for interactive decision making via the Decision-Estimation Coefficient (DEC) appear to be genuinely different from the classical methods. We propose a unified view of these distinct methodologies through a general algorithmic lower bound method. We further introduce a novel complexity measure, decision dimension, which facilitates the derivation of new lower bounds for interactive decision making. In particular, decision dimension provides a characterization of bandit learnability for any structured bandit model class. Further, we characterize the sample complexity of learning convex model class up to a polynomial gap with the decision dimension, addressing the remaining gap between upper and lower bounds in Foster et al. (2021, 2023).
Statistical Properties of Robust Satisficing
May 30, 2024
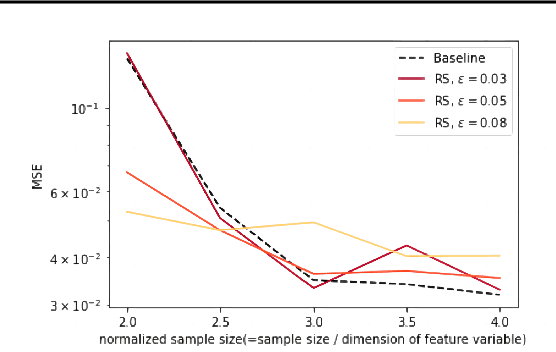
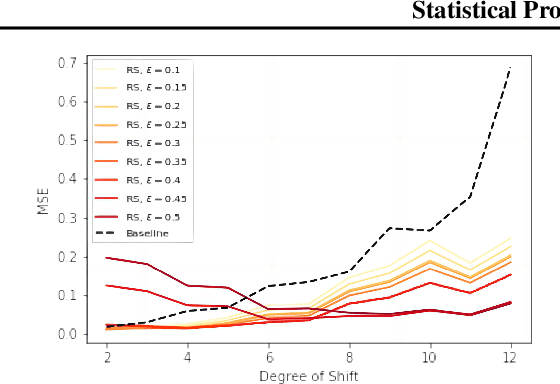

The Robust Satisficing (RS) model is an emerging approach to robust optimization, offering streamlined procedures and robust generalization across various applications. However, the statistical theory of RS remains unexplored in the literature. This paper fills in the gap by comprehensively analyzing the theoretical properties of the RS model. Notably, the RS structure offers a more straightforward path to deriving statistical guarantees compared to the seminal Distributionally Robust Optimization (DRO), resulting in a richer set of results. In particular, we establish two-sided confidence intervals for the optimal loss without the need to solve a minimax optimization problem explicitly. We further provide finite-sample generalization error bounds for the RS optimizer. Importantly, our results extend to scenarios involving distribution shifts, where discrepancies exist between the sampling and target distributions. Our numerical experiments show that the RS model consistently outperforms the baseline empirical risk minimization in small-sample regimes and under distribution shifts. Furthermore, compared to the DRO model, the RS model exhibits lower sensitivity to hyperparameter tuning, highlighting its practicability for robustness considerations.
Bayesian Design Principles for Frequentist Sequential Learning
Oct 01, 2023



We develop a general theory to optimize the frequentist regret for sequential learning problems, where efficient bandit and reinforcement learning algorithms can be derived from unified Bayesian principles. We propose a novel optimization approach to generate "algorithmic beliefs" at each round, and use Bayesian posteriors to make decisions. The optimization objective to create "algorithmic beliefs," which we term "Algorithmic Information Ratio," represents an intrinsic complexity measure that effectively characterizes the frequentist regret of any algorithm. To the best of our knowledge, this is the first systematical approach to make Bayesian-type algorithms prior-free and applicable to adversarial settings, in a generic and optimal manner. Moreover, the algorithms are simple and often efficient to implement. As a major application, we present a novel algorithm for multi-armed bandits that achieves the "best-of-all-worlds" empirical performance in the stochastic, adversarial, and non-stationary environments. And we illustrate how these principles can be used in linear bandits, bandit convex optimization, and reinforcement learning.
Towards Optimal Problem Dependent Generalization Error Bounds in Statistical Learning Theory
Dec 03, 2020We study problem-dependent rates, i.e., generalization errors that scale near-optimally with the variance, the effective loss, or the gradient norms evaluated at the "best hypothesis." We introduce a principled framework dubbed "uniform localized convergence," and characterize sharp problem-dependent rates for central statistical learning problems. From a methodological viewpoint, our framework resolves several fundamental limitations of existing uniform convergence and localization analysis approaches. It also provides improvements and some level of unification in the study of localized complexities, one-sided uniform inequalities, and sample-based iterative algorithms. In the so-called "slow rate" regime, we provides the first (moment-penalized) estimator that achieves the optimal variance-dependent rate for general "rich" classes; we also establish improved loss-dependent rate for standard empirical risk minimization. In the "fast rate" regime, we establish finite-sample problem-dependent bounds that are comparable to precise asymptotics. In addition, we show that efficient algorithms like gradient descent and first-order Expectation-Maximization can achieve optimal generalization error in several representative problems across the areas of non-convex learning, stochastic optimization, and learning with missing data.
Upper Counterfactual Confidence Bounds: a New Optimism Principle for Contextual Bandits
Jul 16, 2020The principle of optimism in the face of uncertainty is one of the most widely used and successful ideas in multi-armed bandits and reinforcement learning. However, existing optimistic algorithms (primarily UCB and its variants) are often unable to deal with large context spaces. Essentially all existing well performing algorithms for general contextual bandit problems rely on weighted action allocation schemes; and theoretical guarantees for optimism-based algorithms are only known for restricted formulations. In this paper we study general contextual bandits under the realizability condition, and propose a simple generic principle to design optimistic algorithms, dubbed "Upper Counterfactual Confidence Bounds" (UCCB). We show that these algorithms are provably optimal and efficient in the presence of large context spaces. Key components of UCCB include: 1) a systematic analysis of confidence bounds in policy space rather than in action space; and 2) the potential function perspective that is used to express the power of optimism in the contextual setting. We further show how the UCCB principle can be extended to infinite action spaces, by constructing confidence bounds via the newly introduced notion of "counterfactual action divergence."