 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity Analysis of a Countable-armed Bandit Problem
Paper and Code
Jan 18, 2023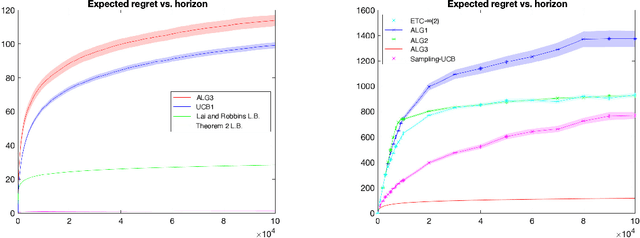
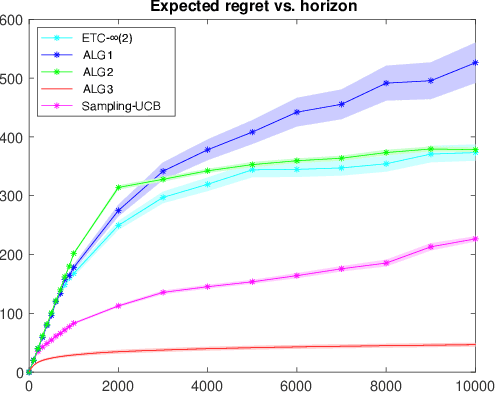
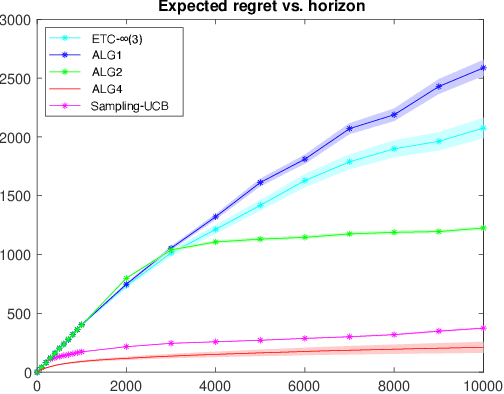
We consider a stochastic multi-armed bandit (MAB) problem motivated by ``large'' action spaces, and endowed with a population of arms containing exactly $K$ arm-types, each characterized by a distinct mean reward. The decision maker is oblivious to the statistical properties of reward distributions as well as the population-level distribution of different arm-types, and is precluded also from observing the type of an arm after play. We study the classical problem of minimizing the expected cumulative regret over a horizon of play $n$, and propose algorithms that achieve a rate-optimal finite-time instance-dependent regret of $\mathcal{O}\left( \log n \right)$. We also show that the instance-independent (minimax) regret is $\tilde{\mathcal{O}}\left( \sqrt{n} \right)$ when $K=2$. While the order of regret and complexity of the problem suggests a great degree of similarity to the classical MAB problem, properties of the performance bounds and salient aspects of algorithm design are quite distinct from the latter, as are the key primitives that determine complexity along with the analysis tools needed to study them.