 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCoHead: Audio-and-Video-Driven Talking Head Generation by Disentangled Control of Head Pose and Facial Expressions
Mar 14, 2023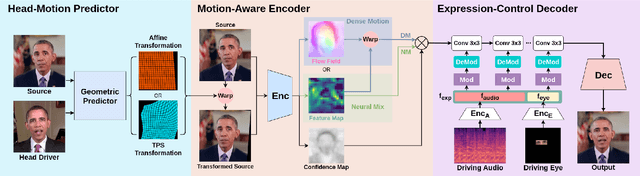
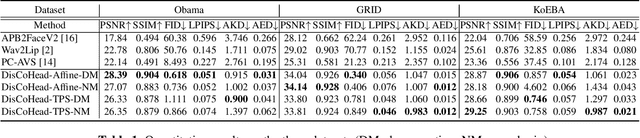


For realistic talking head generation, creating natural head motion while maintaining accurate lip synchronization is essential. To fulfill this challenging task, we propose DisCoHead, a novel method to disentangle and control head pose and facial expressions without supervision. DisCoHead uses a single geometric transformation as a bottleneck to isolate and extract head motion from a head-driving video. Either an affine or a thin-plate spline transformation can be used and both work well as geometric bottlenecks. We enhance the efficiency of DisCoHead by integrating a dense motion estimator and the encoder of a generator which are originally separate modules. Taking a step further, we also propose a neural mix approach where dense motion is estimated and applied implicitly by the encoder. After applying the disentangled head motion to a source identity, DisCoHead controls the mouth region according to speech audio, and it blinks eyes and moves eyebrows following a separate driving video of the eye region, via the weight modulation of convolutional neural networks. The experiments using multiple datasets show that DisCoHead successfully generates realistic audio-and-video-driven talking heads and outperforms state-of-the-art methods. Project page: https://deepbrainai-research.github.io/discohead/
New Insights for the Stability-Plasticity Dilemma in Online Continual Learning
Feb 17, 2023The aim of continual learning is to learn new tasks continuously (i.e., plasticity) without forgetting previously learned knowledge from old tasks (i.e., stability). In the scenario of online continual learning, wherein data comes strictly in a streaming manner, the plasticity of online continual learning is more vulnerable than offline continual learning because the training signal that can be obtained from a single data point is limited. To overcome the stability-plasticity dilemma in online continual learning, we propose an online continual learning framework named multi-scale feature adaptation network (MuFAN) that utilizes a richer context encoding extracted from different levels of a pre-trained network. Additionally, we introduce a novel structure-wise distillation loss and replace the commonly used batch normalization layer with a newly proposed stability-plasticity normalization module to train MuFAN that simultaneously maintains high plasticity and stability. MuFAN outperforms other state-of-the-art continual learning methods on the SVHN, CIFAR100, miniImageNet, and CORe50 datasets. Extensive experiments and ablation studies validate the significance and scalability of each proposed component: 1) multi-scale feature maps from a pre-trained encoder, 2) the structure-wise distillation loss, and 3) the stability-plasticity normalization module in MuFAN. Code is publicly available at https://github.com/whitesnowdrop/MuFAN.