 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCoHead: Audio-and-Video-Driven Talking Head Generation by Disentangled Control of Head Pose and Facial Expressions
Paper and Code
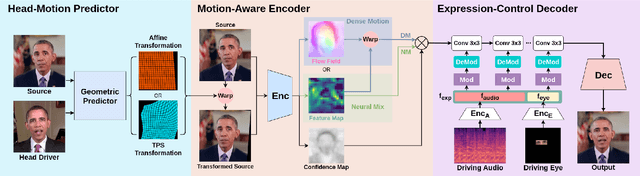
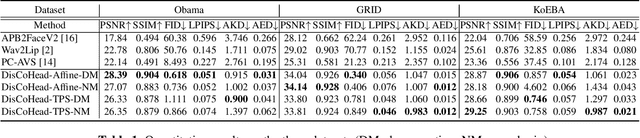


For realistic talking head generation, creating natural head motion while maintaining accurate lip synchronization is essential. To fulfill this challenging task, we propose DisCoHead, a novel method to disentangle and control head pose and facial expressions without supervision. DisCoHead uses a single geometric transformation as a bottleneck to isolate and extract head motion from a head-driving video. Either an affine or a thin-plate spline transformation can be used and both work well as geometric bottlenecks. We enhance the efficiency of DisCoHead by integrating a dense motion estimator and the encoder of a generator which are originally separate modules. Taking a step further, we also propose a neural mix approach where dense motion is estimated and applied implicitly by the encoder. After applying the disentangled head motion to a source identity, DisCoHead controls the mouth region according to speech audio, and it blinks eyes and moves eyebrows following a separate driving video of the eye region, via the weight modulation of convolutional neural networks. The experiments using multiple datasets show that DisCoHead successfully generates realistic audio-and-video-driven talking heads and outperforms state-of-the-art methods. Project page: https://deepbrainai-research.github.io/discohead/