 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpline Dimensional Decomposition with Interpolation-based Optimal Knot Selection for Stochastic Dynamic Analysis
May 19, 2025



Forward uncertainty quantification in dynamic systems is challenging due to non-smooth or locally oscillating nonlinear behaviors. Spline dimensional decomposition (SDD) effectively addresses such nonlinearity by partitioning input coordinates via knot placement, yet its accuracy is highly sensitive to the location of internal knots. Optimizing knots through sequential quadratic programming can be effective, yet the optimization process becomes computationally intense. We propose a computationally efficient, interpolation-based method for optimal knot selection in SDD. The method involves three steps: (1) interpolating input-output profiles, (2) defining subinterval-based reference regions, and (3) selecting optimal knot locations at maximum gradient points within each region. The resulting knot vector is then applied to SDD for accurate approximation of non-smooth and locally oscillating responses. A modal analysis of a lower control arm demonstrates that SDD with the proposed knot selection achieves higher accuracy than SDD with uniformly or randomly spaced knots, and also a Gaussian process surrogate model. The proposed SDD exhibits the lowest relative variance error (2.89%), compared to SDD with uniformly spaced knots (12.310%), randomly spaced knots (15.274%), and Gaussian process (5.319%) in the first natural frequency distribution. All surrogate models are constructed using the same 401 simulation datasets, and the relative errors are evaluated against a 2000-sample Monte Carlo simulation. The scalability and applicability of proposed method are demonstrated through stochastic and reliability analyses of mathematical functions (N=1, 3) and a lower control arm system (N=10). The results confirm that both second-moment statistics and reliability estimates can be accurately achieved with only a few hundred function evaluations or finite element simulations.
A third-order finite difference weighted essentially non-oscillatory scheme with shallow neural network
Jul 10, 2024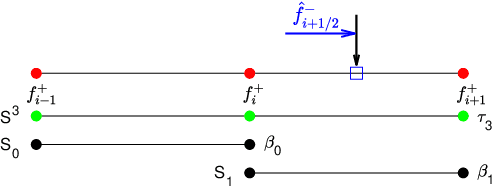

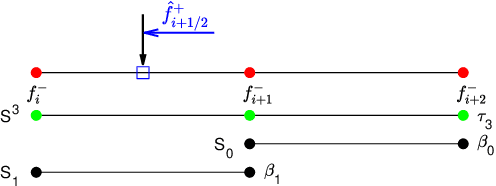

In this paper, we introduce the finite difference weighted essentially non-oscillatory (WENO) scheme based on the neural network for hyperbolic conservation laws. We employ the supervised learning and design two loss functions, one with the mean squared error and the other with the mean squared logarithmic error, where the WENO3-JS weights are computed as the labels. Each loss function consists of two components where the first component compares the difference between the weights from the neural network and WENO3-JS weights, while the second component matches the output weights of the neural network and the linear weights. The former of the loss function enforces the neural network to follow the WENO properties, implying that there is no need for the post-processing layer. Additionally the latter leads to better performance around discontinuities. As a neural network structure, we choose the shallow neural network (SNN) for computational efficiency with the Delta layer consisting of the normalized undivided differences. These constructed WENO3-SNN schemes show the outperformed results in one-dimensional examples and improved behavior in two-dimensional examples, compared with the simulations from WENO3-JS and WENO3-Z.
Spear and Shield: Adversarial Attacks and Defense Methods for Model-Based Link Prediction on Continuous-Time Dynamic Graphs
Aug 21, 2023



Real-world graphs are dynamic, constantly evolving with new interactions, such as financial transactions in financial networks. Temporal Graph Neural Networks (TGNNs) have been developed to effectively capture the evolving patterns in dynamic graphs. While these models have demonstrated their superiority, being widely adopted in various important fields, their vulnerabilities against adversarial attacks remain largely unexplored. In this paper, we propose T-SPEAR, a simple and effective adversarial attack method for link prediction on continuous-time dynamic graphs, focusing on investigating the vulnerabilities of TGNNs. Specifically, before the training procedure of a victim model, which is a TGNN for link prediction, we inject edge perturbations to the data that are unnoticeable in terms of the four constraints we propose, and yet effective enough to cause malfunction of the victim model. Moreover, we propose a robust training approach T-SHIELD to mitigate the impact of adversarial attacks. By using edge filtering and enforcing temporal smoothness to node embeddings, we enhance the robustness of the victim model. Our experimental study shows that T-SPEAR significantly degrades the victim model's performance on link prediction tasks, and even more, our attacks are transferable to other TGNNs, which differ from the victim model assumed by the attacker. Moreover, we demonstrate that T-SHIELD effectively filters out adversarial edges and exhibits robustness against adversarial attacks, surpassing the link prediction performance of the naive TGNN by up to 11.2% under T-SPEAR.
New Insights for the Stability-Plasticity Dilemma in Online Continual Learning
Feb 17, 2023The aim of continual learning is to learn new tasks continuously (i.e., plasticity) without forgetting previously learned knowledge from old tasks (i.e., stability). In the scenario of online continual learning, wherein data comes strictly in a streaming manner, the plasticity of online continual learning is more vulnerable than offline continual learning because the training signal that can be obtained from a single data point is limited. To overcome the stability-plasticity dilemma in online continual learning, we propose an online continual learning framework named multi-scale feature adaptation network (MuFAN) that utilizes a richer context encoding extracted from different levels of a pre-trained network. Additionally, we introduce a novel structure-wise distillation loss and replace the commonly used batch normalization layer with a newly proposed stability-plasticity normalization module to train MuFAN that simultaneously maintains high plasticity and stability. MuFAN outperforms other state-of-the-art continual learning methods on the SVHN, CIFAR100, miniImageNet, and CORe50 datasets. Extensive experiments and ablation studies validate the significance and scalability of each proposed component: 1) multi-scale feature maps from a pre-trained encoder, 2) the structure-wise distillation loss, and 3) the stability-plasticity normalization module in MuFAN. Code is publicly available at https://github.com/whitesnowdrop/MuFAN.
I'm Me, We're Us, and I'm Us: Tri-directional Contrastive Learning on Hypergraphs
Jun 09, 2022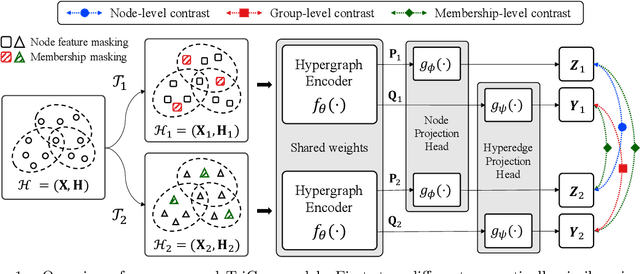
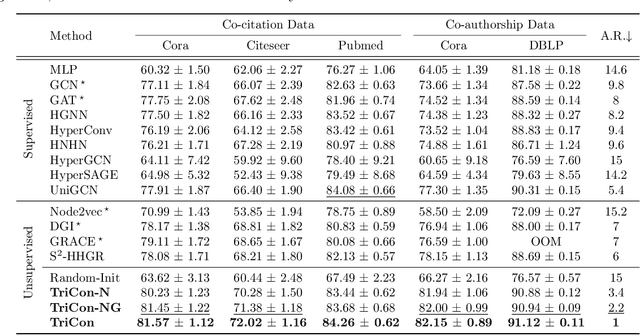
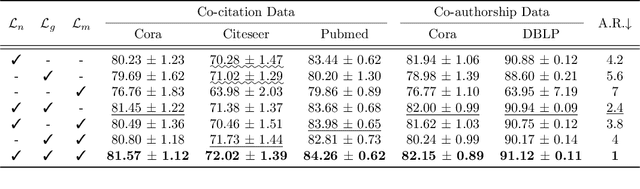
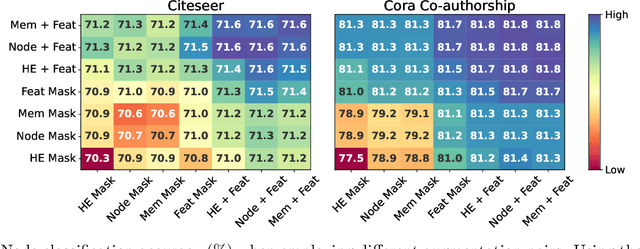
Although machine learning on hypergraphs has attracted considerable attention, most of the works have focused on (semi-)supervised learning, which may cause heavy labeling costs and poor generalization. Recently, contrastive learning has emerged as a successful unsupervised representation learning method. Despite the prosperous development of contrastive learning in other domains, contrastive learning on hypergraphs remains little explored. In this paper, we propose TriCon (Tri-directional Contrastive learning), a general framework for contrastive learning on hypergraphs. Its main idea is tri-directional contrast, and specifically, it aims to maximize in two augmented views the agreement (a) between the same node, (b) between the same group of nodes, and (c) between each group and its members. Together with simple but surprisingly effective data augmentation and negative sampling schemes, these three forms of contrast enable TriCon to capture both microscopic and mesoscopic structural information in node embeddings. Our extensive experiments using 13 baseline approaches, five datasets, and two tasks demonstrate the effectiveness of TriCon, and most noticeably, TriCon consistently outperforms not just unsupervised competitors but also (semi-)supervised competitors mostly by significant margins for node classification.
Machine Composition of Korean Music via Topological Data Analysis and Artificial Neural Network
Mar 29, 2022


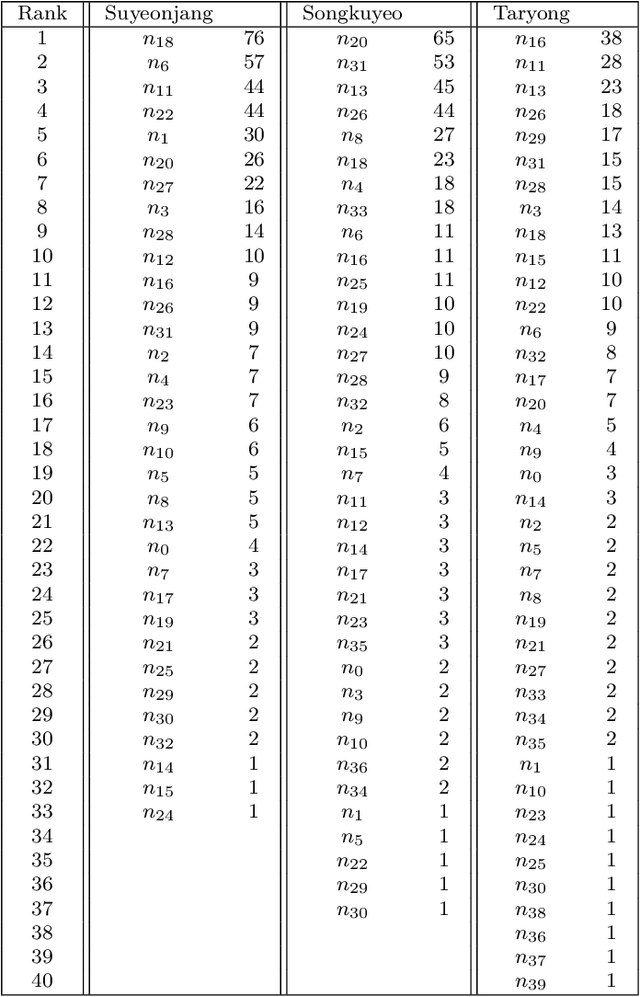
Common AI music composition algorithms based on artificial neural networks are to train a machine by feeding a large number of music pieces and create artificial neural networks that can produce music similar to the input music data. This approach is a blackbox optimization, that is, the underlying composition algorithm is, in general, not known to users. In this paper, we present a way of machine composition that trains a machine the composition principle embedded in the given music data instead of directly feeding music pieces. We propose this approach by using the concept of {\color{black}{Overlap}} matrix proposed in \cite{TPJ}. In \cite{TPJ}, a type of Korean music, so-called the {\it Dodeuri} music such as Suyeonjangjigok has been analyzed using topological data analysis (TDA), particularly using persistent homology. As the raw music data is not suitable for TDA analysis, the music data is first reconstructed as a graph. The node of the graph is defined as a two-dimensional vector composed of the pitch and duration of each music note. The edge between two nodes is created when those nodes appear consecutively in the music flow. Distance is defined based on the frequency of such appearances. Through TDA on the constructed graph, a unique set of cycles is found for the given music. In \cite{TPJ}, the new concept of the {\it {\color{black}{Overlap}} matrix} has been proposed, which visualizes how those cycles are interconnected over the music flow, in a matrix form. In this paper, we explain how we use the {\color{black}{Overlap}} matrix for machine composition. The {\color{black}{Overlap}} matrix makes it possible to compose a new music piece algorithmically and also provide a seed music towards the desired artificial neural network. In this paper, we use the {\it Dodeuri} music and explain detailed steps.
AutoSNN: Towards Energy-Efficient Spiking Neural Networks
Feb 16, 2022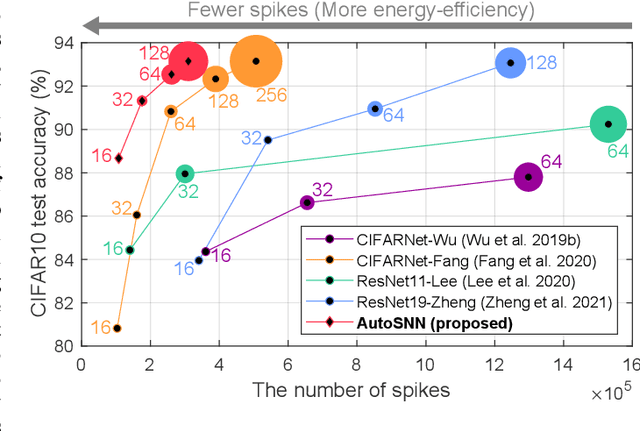
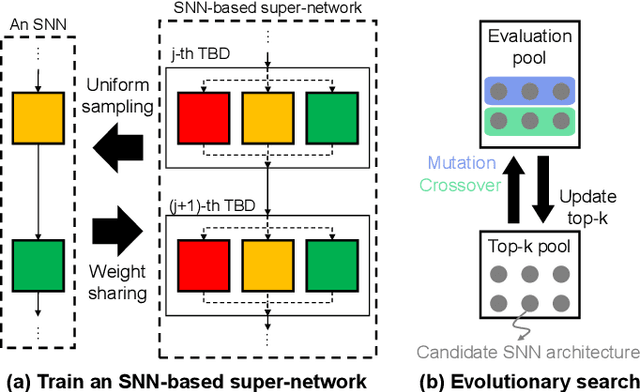
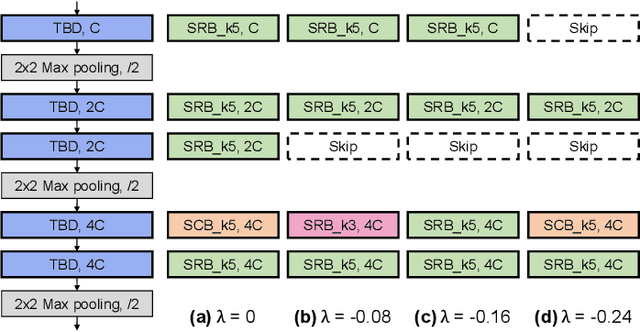
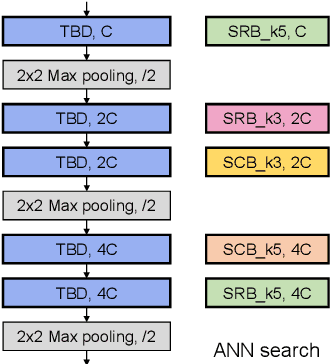
Spiking neural networks (SNNs) that mimic information transmission in the brain can energy-efficiently process spatio-temporal information through discrete and sparse spikes, thereby receiving considerable attention. To improve accuracy and energy efficiency of SNNs, most previous studies have focused solely on training methods, and the effect of architecture has rarely been studied. We investigate the design choices used in the previous studies in terms of the accuracy and number of spikes and figure out that they are not best-suited for SNNs. To further improve the accuracy and reduce the spikes generated by SNNs, we propose a spike-aware neural architecture search framework called AutoSNN. We define a search space consisting of architectures without undesirable design choices. To enable the spike-aware architecture search, we introduce a fitness that considers both the accuracy and number of spikes. AutoSNN successfully searches for SNN architectures that outperform hand-crafted SNNs in accuracy and energy efficiency. We thoroughly demonstrate the effectiveness of AutoSNN on various datasets including neuromorphic datasets.
Energy-efficient Knowledge Distillation for Spiking Neural Networks
Jun 14, 2021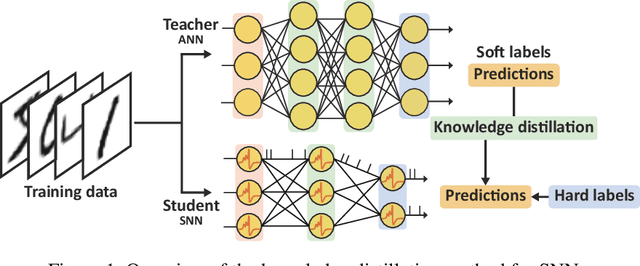
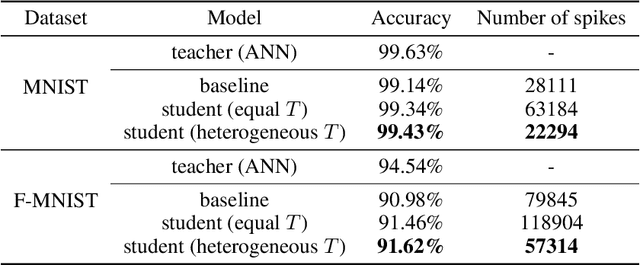
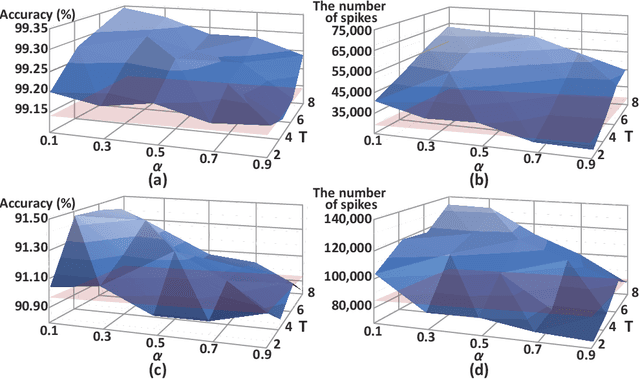
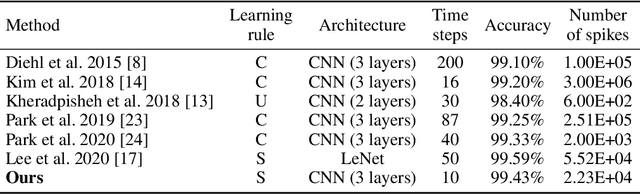
Spiking neural networks (SNNs) have been gaining interest as energy-efficient alternatives of conventional artificial neural networks (ANNs) due to their event-driven computation. Considering the future deployment of SNN models to constrained neuromorphic devices, many studies have applied techniques originally used for ANN model compression, such as network quantization, pruning, and knowledge distillation, to SNNs. Among them, existing works on knowledge distillation reported accuracy improvements of student SNN model. However, analysis on energy efficiency, which is also an important feature of SNN, was absent. In this paper, we thoroughly analyze the performance of the distilled SNN model in terms of accuracy and energy efficiency. In the process, we observe a substantial increase in the number of spikes, leading to energy inefficiency, when using the conventional knowledge distillation methods. Based on this analysis, to achieve energy efficiency, we propose a novel knowledge distillation method with heterogeneous temperature parameters. We evaluate our method on two different datasets and show that the resulting SNN student satisfies both accuracy improvement and reduction of the number of spikes. On MNIST dataset, our proposed student SNN achieves up to 0.09% higher accuracy and produces 65% less spikes compared to the student SNN trained with conventional knowledge distillation method. We also compare the results with other SNN compression techniques and training methods.
Noise-Robust Deep Spiking Neural Networks with Temporal Information
Apr 22, 2021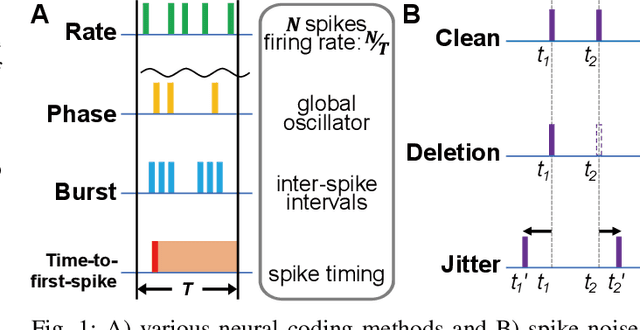
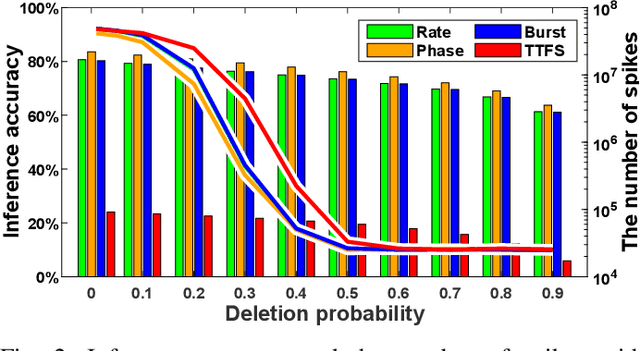
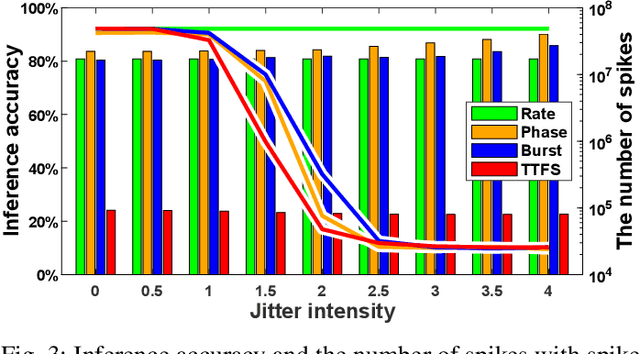
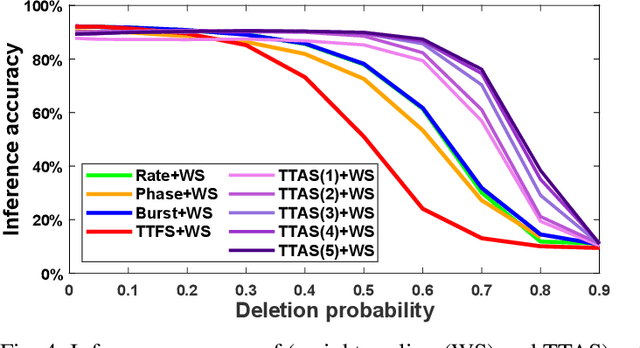
Spiking neural networks (SNNs) have emerged as energy-efficient neural networks with temporal information. SNNs have shown a superior efficiency on neuromorphic devices, but the devices are susceptible to noise, which hinders them from being applied in real-world applications. Several studies have increased noise robustness, but most of them considered neither deep SNNs nor temporal information. In this paper, we investigate the effect of noise on deep SNNs with various neural coding methods and present a noise-robust deep SNN with temporal information. With the proposed methods, we have achieved a deep SNN that is efficient and robust to spike deletion and jitter.
SliceNStitch: Continuous CP Decomposition of Sparse Tensor Streams
Mar 02, 2021

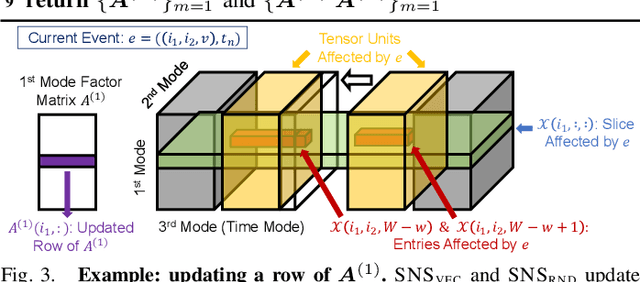
Consider traffic data (i.e., triplets in the form of source-destination-timestamp) that grow over time. Tensors (i.e., multi-dimensional arrays) with a time mode are widely used for modeling and analyzing such multi-aspect data streams. In such tensors, however, new entries are added only once per period, which is often an hour, a day, or even a year. This discreteness of tensors has limited their usage for real-time applications, where new data should be analyzed instantly as it arrives. How can we analyze time-evolving multi-aspect sparse data 'continuously' using tensors where time is'discrete'? We propose SLICENSTITCH for continuous CANDECOMP/PARAFAC (CP) decomposition, which has numerous time-critical applications, including anomaly detection, recommender systems, and stock market prediction. SLICENSTITCH changes the starting point of each period adaptively, based on the current time, and updates factor matrices (i.e., outputs of CP decomposition) instantly as new data arrives. We show, theoretically and experimentally, that SLICENSTITCH is (1) 'Any time': updating factor matrices immediately without having to wait until the current time period ends, (2) Fast: with constant-time updates up to 464x faster than online methods, and (3) Accurate: with fitness comparable (specifically, 72 ~ 100%) to offline methods.