 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVoiceBench, KOpenAudioBench, and KMMAU: Agent-Driven Korean Speech Benchmarks for Evaluating SpeechLMs
May 27, 2026Speech language models (SpeechLMs) have achieved substantial progress by extending large language models (LLMs) to the speech modality. However, SpeechLM evaluation remains heavily centered on English, limiting reliable assessment of multilingual speech capabilities. Straightforward benchmark transfer through ASR, translation, normalization, and TTS can corrupt language-specific instructions, answer constraints, and spoken forms; for audio understanding, transferring source-language audio also fails to preserve target-language speaker attributes, accents, and paralinguistic properties. To address these limitations, we propose two human-agent benchmark-construction frameworks: one transfers source-language SpokenQA benchmarks into target-language SpokenQA benchmarks, and the other converts target-language ASR corpora into audio understanding benchmarks using transcriptions and speaker metadata. Using these frameworks, we construct and publicly release three Korean speech benchmarks: KVoiceBench and KOpenAudioBench for Korean SpokenQA, and KMMAU for Korean audio understanding, comprising 12,345 samples in total. We evaluate eight recent SpeechLMs and find that English-Korean performance gaps vary substantially across models and task families, and that SpokenQA and audio understanding rankings diverge, revealing complementary weaknesses invisible to English-only evaluation.
Simple Drop-in LoRA Conditioning on Attention Layers Will Improve Your Diffusion Model
May 07, 2024



Current state-of-the-art diffusion models employ U-Net architectures containing convolutional and (qkv) self-attention layers. The U-Net processes images while being conditioned on the time embedding input for each sampling step and the class or caption embedding input corresponding to the desired conditional generation. Such conditioning involves scale-and-shift operations to the convolutional layers but does not directly affect the attention layers. While these standard architectural choices are certainly effective, not conditioning the attention layers feels arbitrary and potentially suboptimal. In this work, we show that simply adding LoRA conditioning to the attention layers without changing or tuning the other parts of the U-Net architecture improves the image generation quality. For example, a drop-in addition of LoRA conditioning to EDM diffusion model yields FID scores of 1.91/1.75 for unconditional and class-conditional CIFAR-10 generation, improving upon the baseline of 1.97/1.79.
Efficient Neural Network Approximation of Robust PCA for Automated Analysis of Calcium Imaging Data
Jul 31, 2021

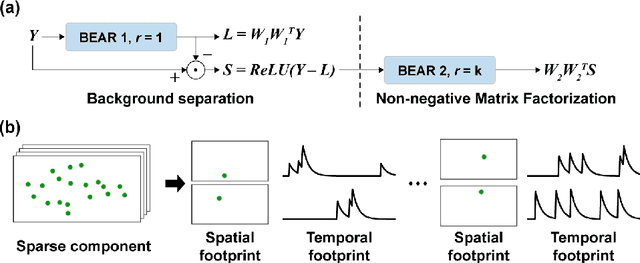

Calcium imaging is an essential tool to study the activity of neuronal populations. However, the high level of background fluorescence in images hinders the accurate identification of neurons and the extraction of neuronal activities. While robust principal component analysis (RPCA) is a promising method that can decompose the foreground and background in such images, its computational complexity and memory requirement are prohibitively high to process large-scale calcium imaging data. Here, we propose BEAR, a simple bilinear neural network for the efficient approximation of RPCA which achieves an order of magnitude speed improvement with GPU acceleration compared to the conventional RPCA algorithms. In addition, we show that BEAR can perform foreground-background separation of calcium imaging data as large as tens of gigabytes. We also demonstrate that two BEARs can be cascaded to perform simultaneous RPCA and non-negative matrix factorization for the automated extraction of spatial and temporal footprints from calcium imaging data. The source code used in the paper is available at https://github.com/NICALab/BEAR.
SliceNStitch: Continuous CP Decomposition of Sparse Tensor Streams
Mar 02, 2021

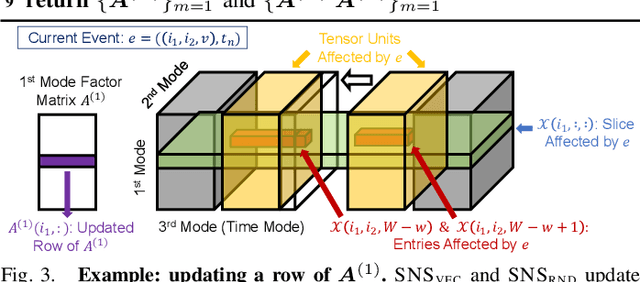
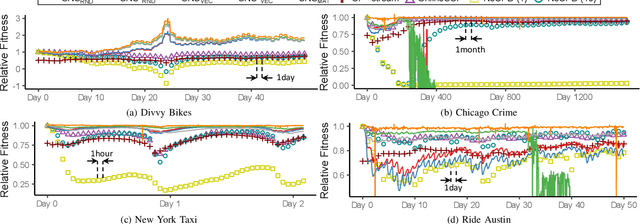
Consider traffic data (i.e., triplets in the form of source-destination-timestamp) that grow over time. Tensors (i.e., multi-dimensional arrays) with a time mode are widely used for modeling and analyzing such multi-aspect data streams. In such tensors, however, new entries are added only once per period, which is often an hour, a day, or even a year. This discreteness of tensors has limited their usage for real-time applications, where new data should be analyzed instantly as it arrives. How can we analyze time-evolving multi-aspect sparse data 'continuously' using tensors where time is'discrete'? We propose SLICENSTITCH for continuous CANDECOMP/PARAFAC (CP) decomposition, which has numerous time-critical applications, including anomaly detection, recommender systems, and stock market prediction. SLICENSTITCH changes the starting point of each period adaptively, based on the current time, and updates factor matrices (i.e., outputs of CP decomposition) instantly as new data arrives. We show, theoretically and experimentally, that SLICENSTITCH is (1) 'Any time': updating factor matrices immediately without having to wait until the current time period ends, (2) Fast: with constant-time updates up to 464x faster than online methods, and (3) Accurate: with fitness comparable (specifically, 72 ~ 100%) to offline methods.
Multi-Scale Distributed Representation for Deep Learning and its Application to b-Jet Tagging
Nov 29, 2018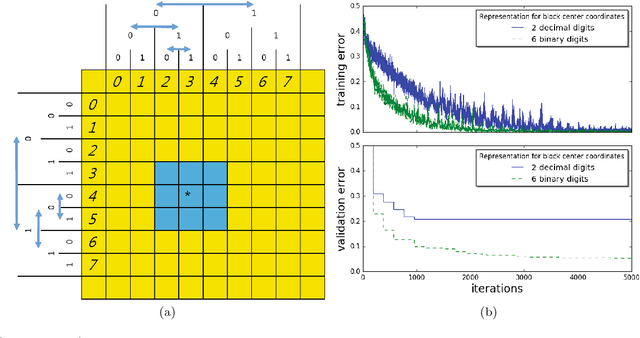
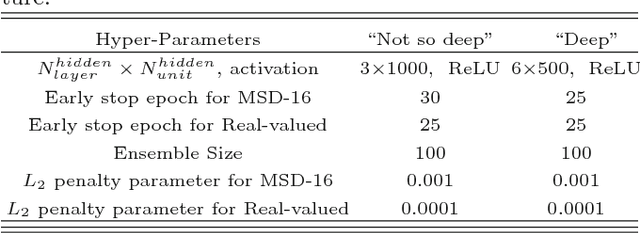
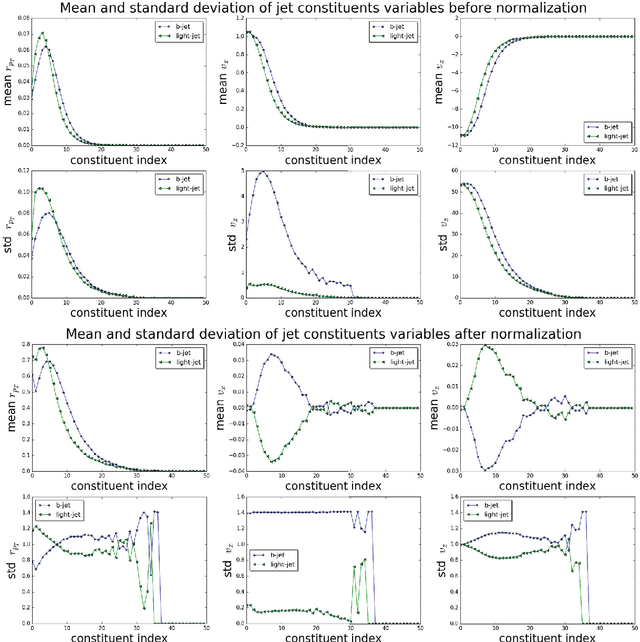

Recently machine learning algorithms based on deep layered artificial neural networks (DNNs) have been applied to a wide variety of high energy physics problems such as jet tagging or event classification. We explore a simple but effective preprocessing step which transforms each real-valued observational quantity or input feature into a binary number with a fixed number of digits. Each binary digit represents the quantity or magnitude in different scales. We have shown that this approach improves the performance of DNNs significantly for some specific tasks without any further complication in feature engineering. We apply this multi-scale distributed binary representation to deep learning on b-jet tagging using daughter particles' momenta and vertex information.
* 13 pages, 8 figures