 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperpixel Tokenization for Vision Transformers: Preserving Semantic Integrity in Visual Tokens
Dec 06, 2024



Transformers, a groundbreaking architecture proposed for Natural Language Processing (NLP), have also achieved remarkable success in Computer Vision. A cornerstone of their success lies in the attention mechanism, which models relationships among tokens. While the tokenization process in NLP inherently ensures that a single token does not contain multiple semantics, the tokenization of Vision Transformer (ViT) utilizes tokens from uniformly partitioned square image patches, which may result in an arbitrary mixing of visual concepts in a token. In this work, we propose to substitute the grid-based tokenization in ViT with superpixel tokenization, which employs superpixels to generate a token that encapsulates a sole visual concept. Unfortunately, the diverse shapes, sizes, and locations of superpixels make integrating superpixels into ViT tokenization rather challenging. Our tokenization pipeline, comprised of pre-aggregate extraction and superpixel-aware aggregation, overcomes the challenges that arise in superpixel tokenization. Extensive experiments demonstrate that our approach, which exhibits strong compatibility with existing frameworks, enhances the accuracy and robustness of ViT on various downstream tasks.
FedRN: Exploiting k-Reliable Neighbors Towards Robust Federated Learning
May 03, 2022
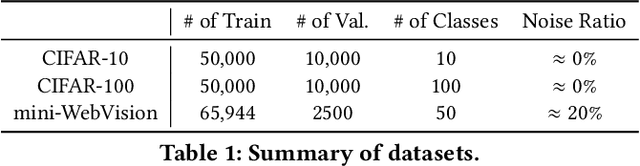
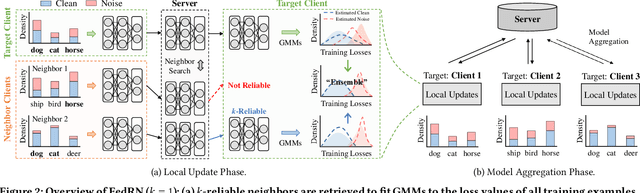
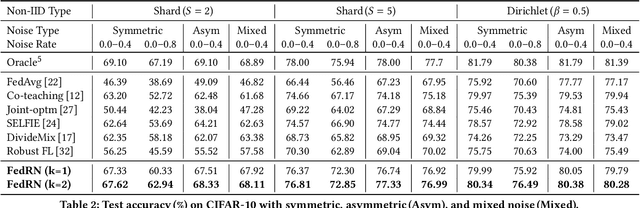
Robustness is becoming another important challenge of federated learning in that the data collection process in each client is naturally accompanied by noisy labels. However, it is far more complex and challenging owing to varying levels of data heterogeneity and noise over clients, which exacerbates the client-to-client performance discrepancy. In this work, we propose a robust federated learning method called FedRN, which exploits k-reliable neighbors with high data expertise or similarity. Our method helps mitigate the gap between low- and high-performance clients by training only with a selected set of clean examples, identified by their ensembled mixture models. We demonstrate the superiority of FedRN via extensive evaluations on three real-world or synthetic benchmark datasets. Compared with existing robust training methods, the results show that FedRN significantly improves the test accuracy in the presence of noisy labels.