 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on the Membership Inference Attack against Tabular Data Synthesis Models
Aug 25, 2022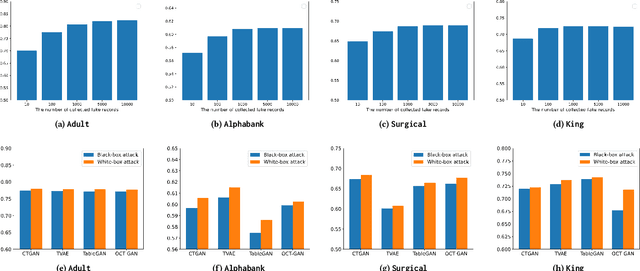
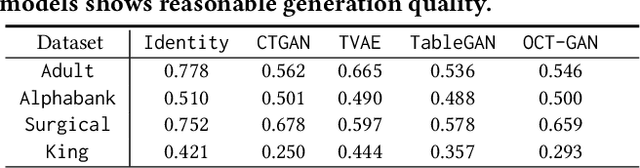

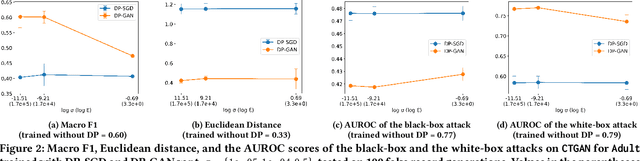
Tabular data typically contains private and important information; thus, precautions must be taken before they are shared with others. Although several methods (e.g., differential privacy and k-anonymity) have been proposed to prevent information leakage, in recent years, tabular data synthesis models have become popular because they can well trade-off between data utility and privacy. However, recent research has shown that generative models for image data are susceptible to the membership inference attack, which can determine whether a given record was used to train a victim synthesis model. In this paper, we investigate the membership inference attack in the context of tabular data synthesis. We conduct experiments on 4 state-of-the-art tabular data synthesis models under two attack scenarios (i.e., one black-box and one white-box attack), and find that the membership inference attack can seriously jeopardize these models. We next conduct experiments to evaluate how well two popular differentially-private deep learning training algorithms, DP-SGD and DP-GAN, can protect the models against the attack. Our key finding is that both algorithms can largely alleviate this threat by sacrificing the generation quality.
LORD: Lower-Dimensional Embedding of Log-Signature in Neural Rough Differential Equations
Apr 19, 2022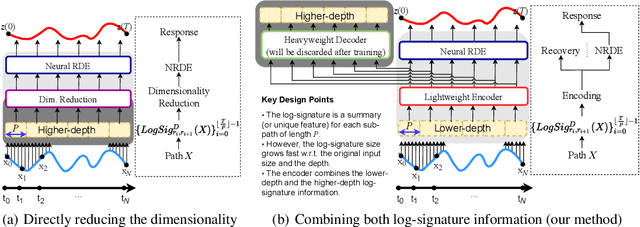

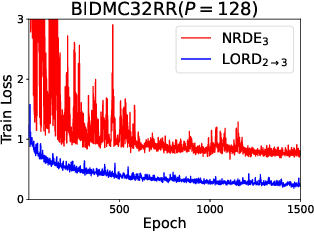
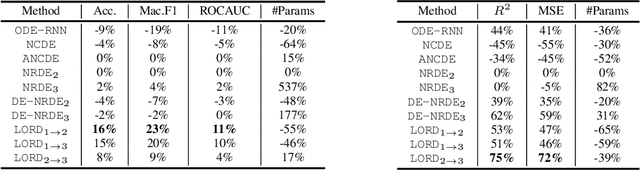
The problem of processing very long time-series data (e.g., a length of more than 10,000) is a long-standing research problem in machine learning. Recently, one breakthrough, called neural rough differential equations (NRDEs), has been proposed and has shown that it is able to process such data. Their main concept is to use the log-signature transform, which is known to be more efficient than the Fourier transform for irregular long time-series, to convert a very long time-series sample into a relatively shorter series of feature vectors. However, the log-signature transform causes non-trivial spatial overheads. To this end, we present the method of LOweR-Dimensional embedding of log-signature (LORD), where we define an NRDE-based autoencoder to implant the higher-depth log-signature knowledge into the lower-depth log-signature. We show that the encoder successfully combines the higher-depth and the lower-depth log-signature knowledge, which greatly stabilizes the training process and increases the model accuracy. In our experiments with benchmark datasets, the improvement ratio by our method is up to 75\% in terms of various classification and forecasting evaluation metrics.
EXIT: Extrapolation and Interpolation-based Neural Controlled Differential Equations for Time-series Classification and Forecasting
Apr 19, 2022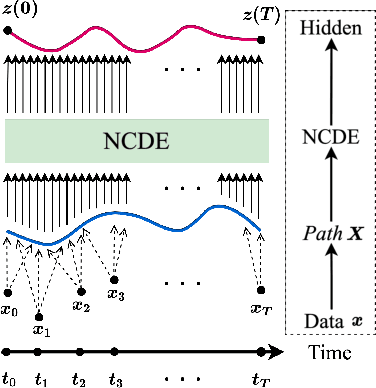
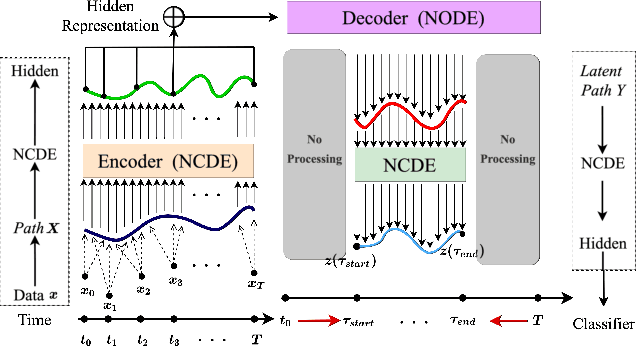
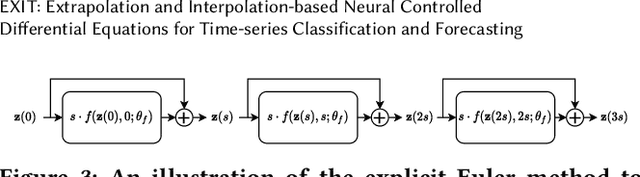
Deep learning inspired by differential equations is a recent research trend and has marked the state of the art performance for many machine learning tasks. Among them, time-series modeling with neural controlled differential equations (NCDEs) is considered as a breakthrough. In many cases, NCDE-based models not only provide better accuracy than recurrent neural networks (RNNs) but also make it possible to process irregular time-series. In this work, we enhance NCDEs by redesigning their core part, i.e., generating a continuous path from a discrete time-series input. NCDEs typically use interpolation algorithms to convert discrete time-series samples to continuous paths. However, we propose to i) generate another latent continuous path using an encoder-decoder architecture, which corresponds to the interpolation process of NCDEs, i.e., our neural network-based interpolation vs. the existing explicit interpolation, and ii) exploit the generative characteristic of the decoder, i.e., extrapolation beyond the time domain of original data if needed. Therefore, our NCDE design can use both the interpolated and the extrapolated information for downstream machine learning tasks. In our experiments with 5 real-world datasets and 12 baselines, our extrapolation and interpolation-based NCDEs outperform existing baselines by non-trivial margins.
Invertible Tabular GANs: Killing Two Birds with OneStone for Tabular Data Synthesis
Feb 08, 2022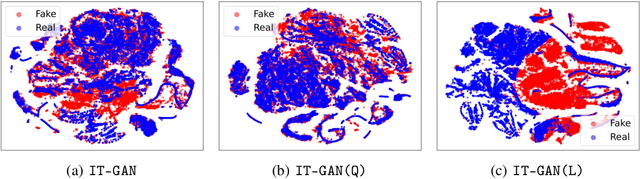
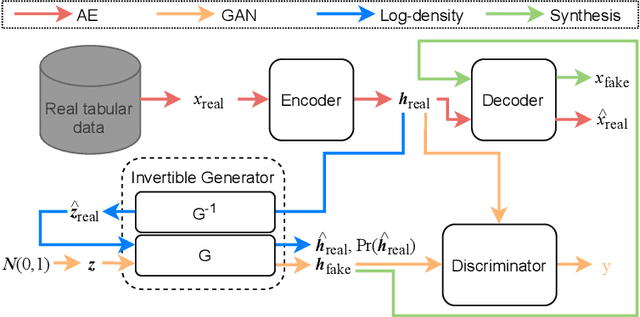
Tabular data synthesis has received wide attention in the literature. This is because available data is often limited, incomplete, or cannot be obtained easily, and data privacy is becoming increasingly important. In this work, we present a generalized GAN framework for tabular synthesis, which combines the adversarial training of GANs and the negative log-density regularization of invertible neural networks. The proposed framework can be used for two distinctive objectives. First, we can further improve the synthesis quality, by decreasing the negative log-density of real records in the process of adversarial training. On the other hand, by increasing the negative log-density of real records, realistic fake records can be synthesized in a way that they are not too much close to real records and reduce the chance of potential information leakage. We conduct experiments with real-world datasets for classification, regression, and privacy attacks. In general, the proposed method demonstrates the best synthesis quality (in terms of task-oriented evaluation metrics, e.g., F1) when decreasing the negative log-density during the adversarial training. If increasing the negative log-density, our experimental results show that the distance between real and fake records increases, enhancing robustness against privacy attacks.
OCT-GAN: Neural ODE-based Conditional Tabular GANs
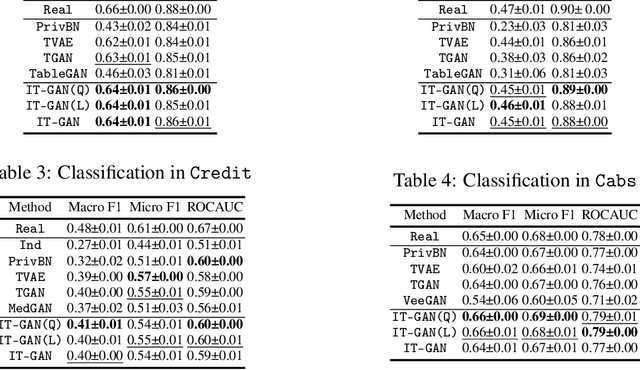
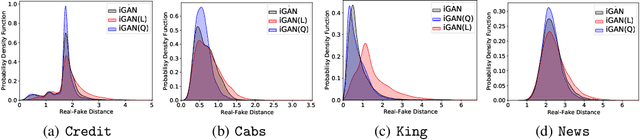
May 31, 2021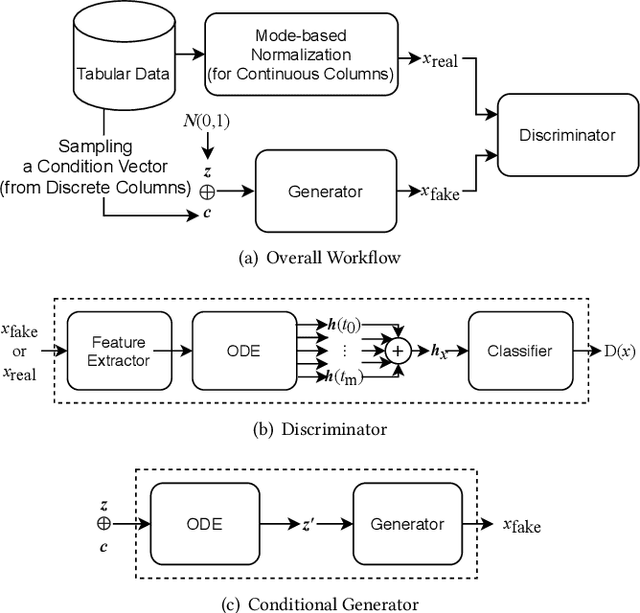

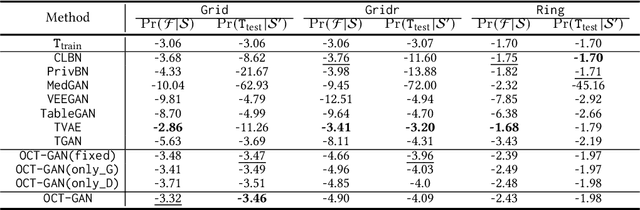
Synthesizing tabular data is attracting much attention these days for various purposes. With sophisticate synthetic data, for instance, one can augment its training data. For the past couple of years, tabular data synthesis techniques have been greatly improved. Recent work made progress to address many problems in synthesizing tabular data, such as the imbalanced distribution and multimodality problems. However, the data utility of state-of-the-art methods is not satisfactory yet. In this work, we significantly improve the utility by designing our generator and discriminator based on neural ordinary differential equations (NODEs). After showing that NODEs have theoretically preferred characteristics for generating tabular data, we introduce our designs. The NODE-based discriminator performs a hidden vector evolution trajectory-based classification rather than classifying with a hidden vector at the last layer only. Our generator also adopts an ODE layer at the very beginning of its architecture to transform its initial input vector (i.e., the concatenation of a noisy vector and a condition vector in our case) onto another latent vector space suitable for the generation process. We conduct experiments with 13 datasets, including but not limited to insurance fraud detection, online news article prediction, and so on, and our presented method outperforms other state-of-the-art tabular data synthesis methods in many cases of our classification, regression, and clustering experiments.