 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenFighter: A Generative and Evolutive Textual Attack Removal
Apr 17, 2024Adversarial attacks pose significant challenges to deep neural networks (DNNs) such as Transformer models in natural language processing (NLP). This paper introduces a novel defense strategy, called GenFighter, which enhances adversarial robustness by learning and reasoning on the training classification distribution. GenFighter identifies potentially malicious instances deviating from the distribution, transforms them into semantically equivalent instances aligned with the training data, and employs ensemble techniques for a unified and robust response. By conducting extensive experiments, we show that GenFighter outperforms state-of-the-art defenses in accuracy under attack and attack success rate metrics. Additionally, it requires a high number of queries per attack, making the attack more challenging in real scenarios. The ablation study shows that our approach integrates transfer learning, a generative/evolutive procedure, and an ensemble method, providing an effective defense against NLP adversarial attacks.
An Empirical Study on the Membership Inference Attack against Tabular Data Synthesis Models
Aug 25, 2022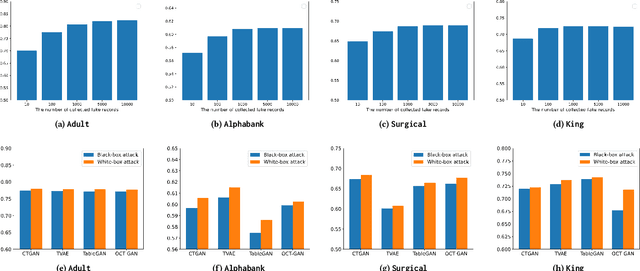
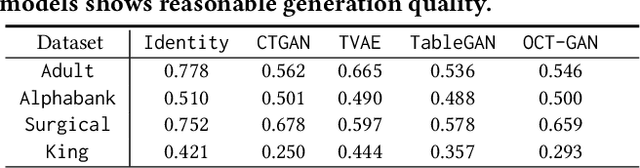

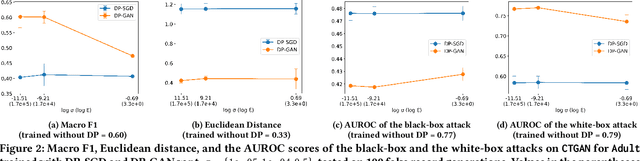
Tabular data typically contains private and important information; thus, precautions must be taken before they are shared with others. Although several methods (e.g., differential privacy and k-anonymity) have been proposed to prevent information leakage, in recent years, tabular data synthesis models have become popular because they can well trade-off between data utility and privacy. However, recent research has shown that generative models for image data are susceptible to the membership inference attack, which can determine whether a given record was used to train a victim synthesis model. In this paper, we investigate the membership inference attack in the context of tabular data synthesis. We conduct experiments on 4 state-of-the-art tabular data synthesis models under two attack scenarios (i.e., one black-box and one white-box attack), and find that the membership inference attack can seriously jeopardize these models. We next conduct experiments to evaluate how well two popular differentially-private deep learning training algorithms, DP-SGD and DP-GAN, can protect the models against the attack. Our key finding is that both algorithms can largely alleviate this threat by sacrificing the generation quality.
Capture the Bot: Using Adversarial Examples to Improve CAPTCHA Robustness to Bot Attacks
Nov 04, 2020



To this date, CAPTCHAs have served as the first line of defense preventing unauthorized access by (malicious) bots to web-based services, while at the same time maintaining a trouble-free experience for human visitors. However, recent work in the literature has provided evidence of sophisticated bots that make use of advancements in machine learning (ML) to easily bypass existing CAPTCHA-based defenses. In this work, we take the first step to address this problem. We introduce CAPTURE, a novel CAPTCHA scheme based on adversarial examples. While typically adversarial examples are used to lead an ML model astray, with CAPTURE, we attempt to make a "good use" of such mechanisms. Our empirical evaluations show that CAPTURE can produce CAPTCHAs that are easy to solve by humans while at the same time, effectively thwarting ML-based bot solvers.
Two Can Play That Game: An Adversarial Evaluation of a Cyber-alert Inspection System
Oct 13, 2018
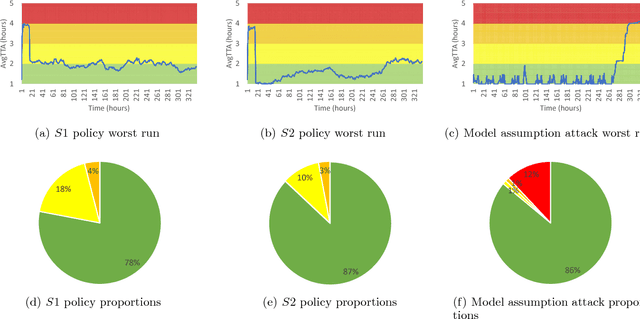

Cyber-security is an important societal concern. Cyber-attacks have increased in numbers as well as in the extent of damage caused in every attack. Large organizations operate a Cyber Security Operation Center (CSOC), which form the first line of cyber-defense. The inspection of cyber-alerts is a critical part of CSOC operations. A recent work, in collaboration with Army Research Lab, USA proposed a reinforcement learning (RL) based approach to prevent the cyber-alert queue length from growing large and overwhelming the defender. Given the potential deployment of this approach to CSOCs run by US defense agencies, we perform a red team (adversarial) evaluation of this approach. Further, with the recent attacks on learning systems, it is even more important to test the limits of this RL approach. Towards that end, we learn an adversarial alert generation policy that is a best response to the defender inspection policy. Surprisingly, we find the defender policy to be quite robust to the best response of the attacker. In order to explain this observation, we extend the earlier RL model to a game model and show that there exists defender policies that can be robust against any adversarial policy. We also derive a competitive baseline from the game theory model and compare it to the RL approach. However, we go further to exploit assumptions made in the MDP in the RL model and discover an attacker policy that overwhelms the defender. We use a double oracle approach to retrain the defender with episodes from this discovered attacker policy. This made the defender robust to the discovered attacker policy and no further harmful attacker policies were discovered. Overall, the adversarial RL and double oracle approach in RL are general techniques that are applicable to other RL usage in adversarial environments.