 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Large-Scale 0-1 Knapsack Problems and its Application to Point Cloud Resampling
Jun 11, 2019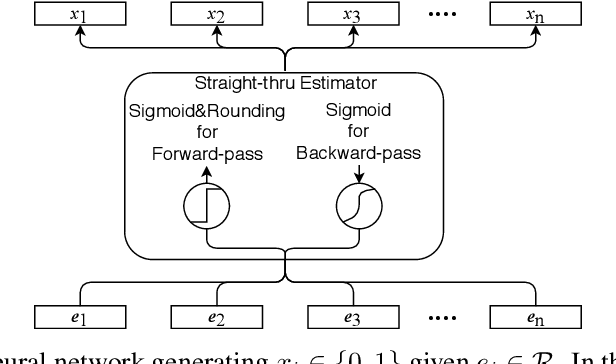
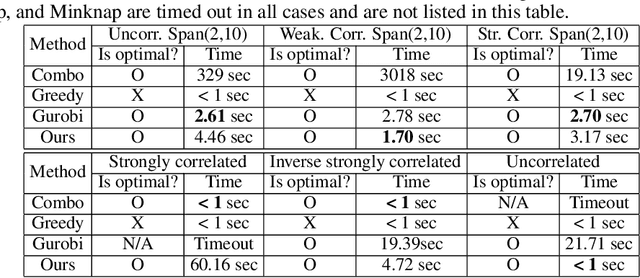
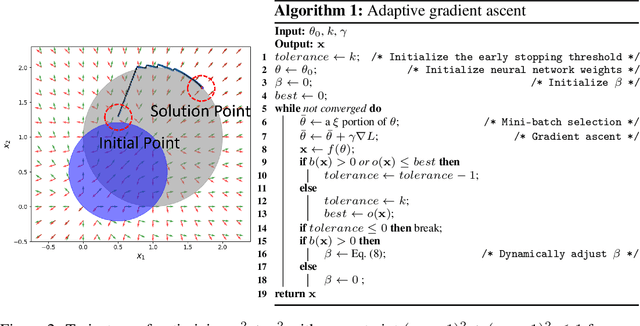

0-1 knapsack is of fundamental importance in computer science, business, operations research, etc. In this paper, we present a deep learning technique-based method to solve large-scale 0-1 knapsack problems where the number of products (items) is large and/or the values of products are not necessarily predetermined but decided by an external value assignment function during the optimization process. Our solution is greatly inspired by the method of Lagrange multiplier and some recent adoptions of game theory to deep learning. After formally defining our proposed method based on them, we develop an adaptive gradient ascent method to stabilize its optimization process. In our experiments, the presented method solves all the large-scale benchmark KP instances in a minute whereas existing methods show fluctuating runtime. We also show that our method can be used for other applications, including but not limited to the point cloud resampling.
Two Can Play That Game: An Adversarial Evaluation of a Cyber-alert Inspection System
Oct 13, 2018
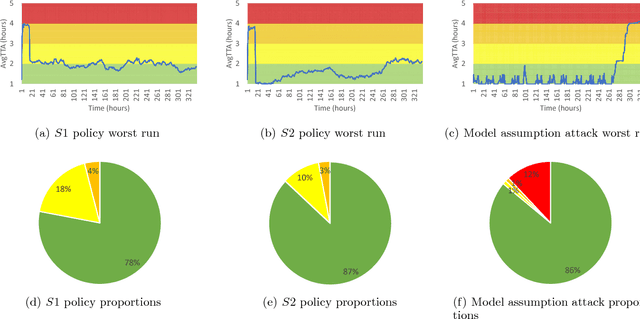

Cyber-security is an important societal concern. Cyber-attacks have increased in numbers as well as in the extent of damage caused in every attack. Large organizations operate a Cyber Security Operation Center (CSOC), which form the first line of cyber-defense. The inspection of cyber-alerts is a critical part of CSOC operations. A recent work, in collaboration with Army Research Lab, USA proposed a reinforcement learning (RL) based approach to prevent the cyber-alert queue length from growing large and overwhelming the defender. Given the potential deployment of this approach to CSOCs run by US defense agencies, we perform a red team (adversarial) evaluation of this approach. Further, with the recent attacks on learning systems, it is even more important to test the limits of this RL approach. Towards that end, we learn an adversarial alert generation policy that is a best response to the defender inspection policy. Surprisingly, we find the defender policy to be quite robust to the best response of the attacker. In order to explain this observation, we extend the earlier RL model to a game model and show that there exists defender policies that can be robust against any adversarial policy. We also derive a competitive baseline from the game theory model and compare it to the RL approach. However, we go further to exploit assumptions made in the MDP in the RL model and discover an attacker policy that overwhelms the defender. We use a double oracle approach to retrain the defender with episodes from this discovered attacker policy. This made the defender robust to the discovered attacker policy and no further harmful attacker policies were discovered. Overall, the adversarial RL and double oracle approach in RL are general techniques that are applicable to other RL usage in adversarial environments.