 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Large-Scale 0-1 Knapsack Problems and its Application to Point Cloud Resampling
Jun 11, 2019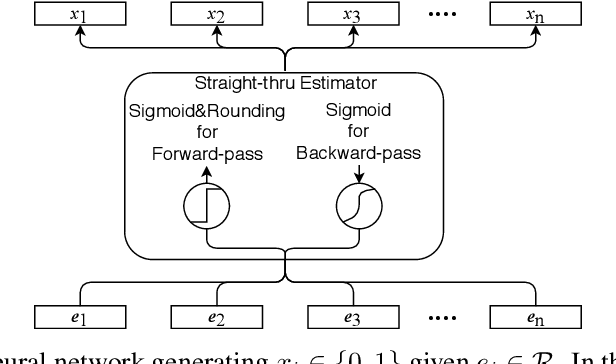
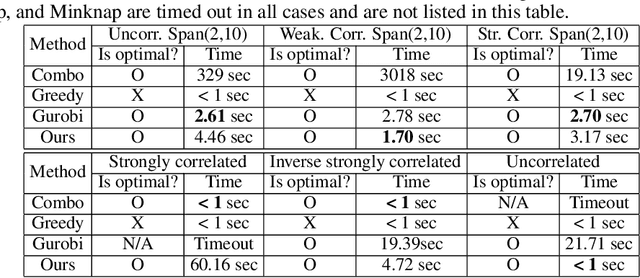
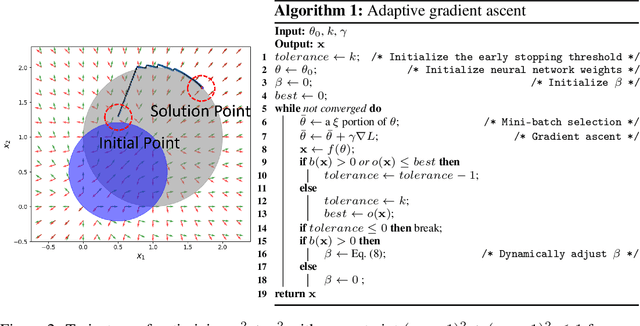

0-1 knapsack is of fundamental importance in computer science, business, operations research, etc. In this paper, we present a deep learning technique-based method to solve large-scale 0-1 knapsack problems where the number of products (items) is large and/or the values of products are not necessarily predetermined but decided by an external value assignment function during the optimization process. Our solution is greatly inspired by the method of Lagrange multiplier and some recent adoptions of game theory to deep learning. After formally defining our proposed method based on them, we develop an adaptive gradient ascent method to stabilize its optimization process. In our experiments, the presented method solves all the large-scale benchmark KP instances in a minute whereas existing methods show fluctuating runtime. We also show that our method can be used for other applications, including but not limited to the point cloud resampling.