 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Guided Contrastive Audio-Visual Masked Autoencoder with Automatically Generated Audio-Visual-Text Triplets from Videos
Jul 16, 2025
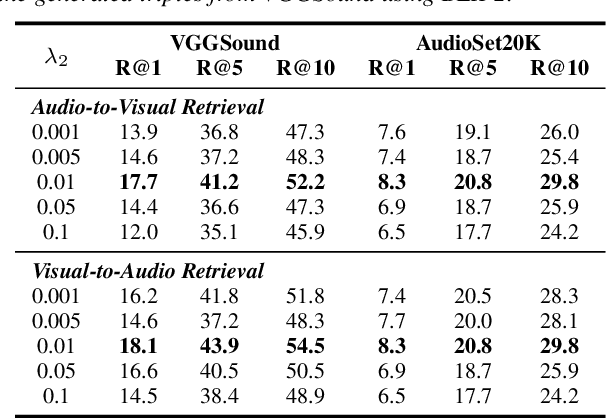
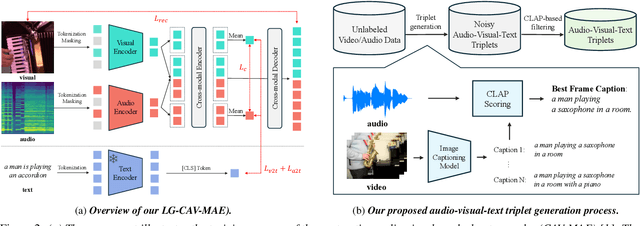

In this paper, we propose Language-Guided Contrastive Audio-Visual Masked Autoencoders (LG-CAV-MAE) to improve audio-visual representation learning. LG-CAV-MAE integrates a pretrained text encoder into contrastive audio-visual masked autoencoders, enabling the model to learn across audio, visual and text modalities. To train LG-CAV-MAE, we introduce an automatic method to generate audio-visual-text triplets from unlabeled videos. We first generate frame-level captions using an image captioning model and then apply CLAP-based filtering to ensure strong alignment between audio and captions. This approach yields high-quality audio-visual-text triplets without requiring manual annotations. We evaluate LG-CAV-MAE on audio-visual retrieval tasks, as well as an audio-visual classification task. Our method significantly outperforms existing approaches, achieving up to a 5.6% improvement in recall@10 for retrieval tasks and a 3.2% improvement for the classification task.
Pre-training with Synthetic Patterns for Audio
Oct 01, 2024
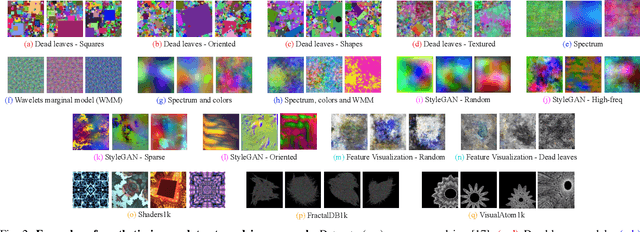

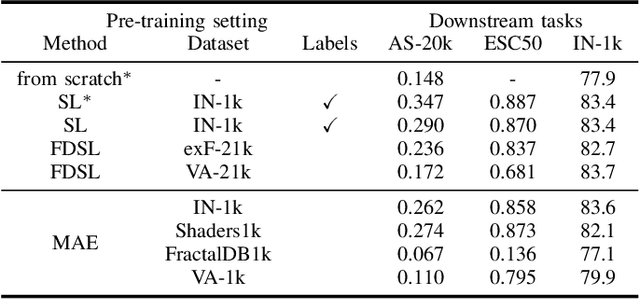
In this paper, we propose to pre-train audio encoders using synthetic patterns instead of real audio data. Our proposed framework consists of two key elements. The first one is Masked Autoencoder (MAE), a self-supervised learning framework that learns from reconstructing data from randomly masked counterparts. MAEs tend to focus on low-level information such as visual patterns and regularities within data. Therefore, it is unimportant what is portrayed in the input, whether it be images, audio mel-spectrograms, or even synthetic patterns. This leads to the second key element, which is synthetic data. Synthetic data, unlike real audio, is free from privacy and licensing infringement issues. By combining MAEs and synthetic patterns, our framework enables the model to learn generalized feature representations without real data, while addressing the issues related to real audio. To evaluate the efficacy of our framework, we conduct extensive experiments across a total of 13 audio tasks and 17 synthetic datasets. The experiments provide insights into which types of synthetic patterns are effective for audio. Our results demonstrate that our framework achieves performance comparable to models pre-trained on AudioSet-2M and partially outperforms image-based pre-training methods.
Data Collection-free Masked Video Modeling
Sep 10, 2024



Pre-training video transformers generally requires a large amount of data, presenting significant challenges in terms of data collection costs and concerns related to privacy, licensing, and inherent biases. Synthesizing data is one of the promising ways to solve these issues, yet pre-training solely on synthetic data has its own challenges. In this paper, we introduce an effective self-supervised learning framework for videos that leverages readily available and less costly static images. Specifically, we define the Pseudo Motion Generator (PMG) module that recursively applies image transformations to generate pseudo-motion videos from images. These pseudo-motion videos are then leveraged in masked video modeling. Our approach is applicable to synthetic images as well, thus entirely freeing video pre-training from data collection costs and other concerns in real data. Through experiments in action recognition tasks, we demonstrate that this framework allows effective learning of spatio-temporal features through pseudo-motion videos, significantly improving over existing methods which also use static images and partially outperforming those using both real and synthetic videos. These results uncover fragments of what video transformers learn through masked video modeling.
Leveraging Image-Text Similarity and Caption Modification for the DataComp Challenge: Filtering Track and BYOD Track
Oct 23, 2023Large web crawl datasets have already played an important role in learning multimodal features with high generalization capabilities. However, there are still very limited studies investigating the details or improvements of data design. Recently, a DataComp challenge has been designed to propose the best training data with the fixed models. This paper presents our solution to both filtering track and BYOD track of the DataComp challenge. Our solution adopts large multimodal models CLIP and BLIP-2 to filter and modify web crawl data, and utilize external datasets along with a bag of tricks to improve the data quality. Experiments show our solution significantly outperforms DataComp baselines (filtering track: 6.6% improvement, BYOD track: 48.5% improvement).
Alleviating Over-segmentation Errors by Detecting Action Boundaries
Jul 14, 2020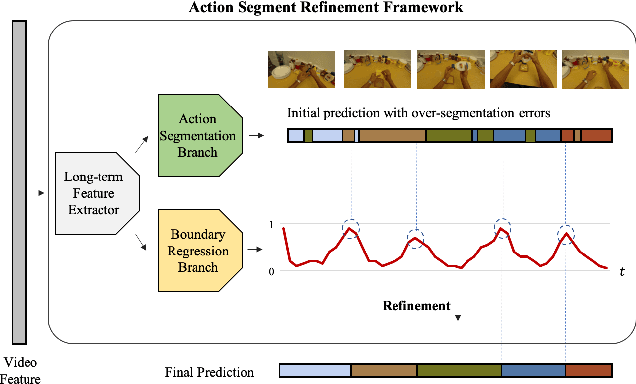
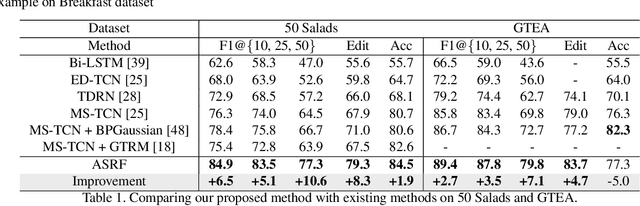

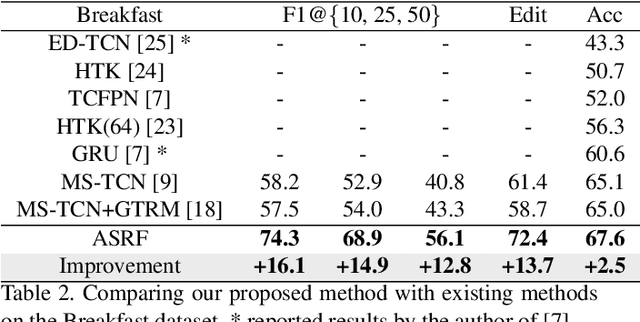
We propose an effective framework for the temporal action segmentation task, namely an Action Segment Refinement Framework (ASRF). Our model architecture consists of a long-term feature extractor and two branches: the Action Segmentation Branch (ASB) and the Boundary Regression Branch (BRB). The long-term feature extractor provides shared features for the two branches with a wide temporal receptive field. The ASB classifies video frames with action classes, while the BRB regresses the action boundary probabilities. The action boundaries predicted by the BRB refine the output from the ASB, which results in a significant performance improvement. Our contributions are three-fold: (i) We propose a framework for temporal action segmentation, the ASRF, which divides temporal action segmentation into frame-wise action classification and action boundary regression. Our framework refines frame-level hypotheses of action classes using predicted action boundaries. (ii) We propose a loss function for smoothing the transition of action probabilities, and analyze combinations of various loss functions for temporal action segmentation. (iii) Our framework outperforms state-of-the-art methods on three challenging datasets, offering an improvement of up to 13.7% in terms of segmental edit distance and up to 16.1% in terms of segmental F1 score. Our code will be publicly available soon.
Retrieving and Highlighting Action with Spatiotemporal Reference
May 19, 2020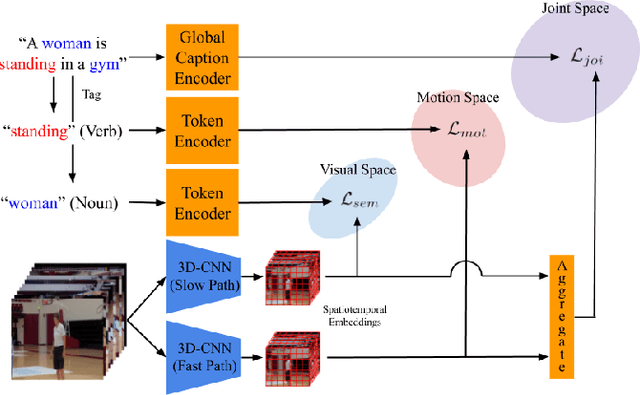
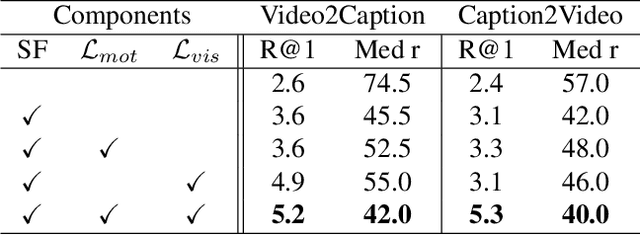
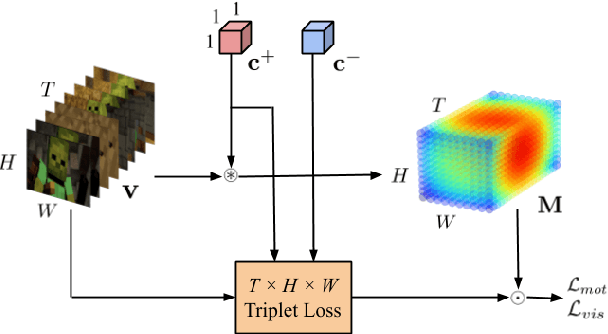

In this paper, we present a framework that jointly retrieves and spatiotemporally highlights actions in videos by enhancing current deep cross-modal retrieval methods. Our work takes on the novel task of action highlighting, which visualizes where and when actions occur in an untrimmed video setting. Action highlighting is a fine-grained task, compared to conventional action recognition tasks which focus on classification or window-based localization. Leveraging weak supervision from annotated captions, our framework acquires spatiotemporal relevance maps and generates local embeddings which relate to the nouns and verbs in captions. Through experiments, we show that our model generates various maps conditioned on different actions, in which conventional visual reasoning methods only go as far as to show a single deterministic saliency map. Also, our model improves retrieval recall over our baseline without alignment by 2-3% on the MSR-VTT dataset.