 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating Over-segmentation Errors by Detecting Action Boundaries
Jul 14, 2020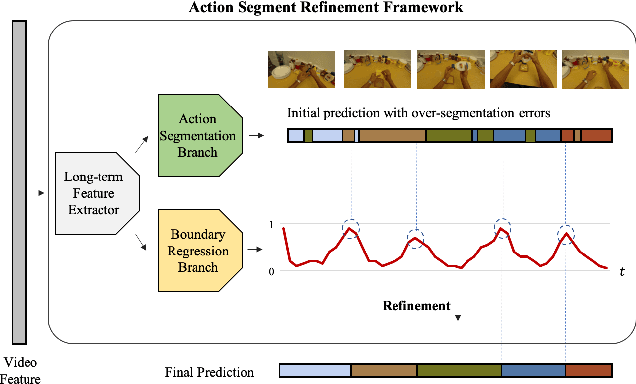
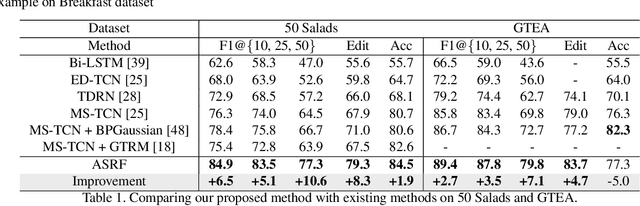

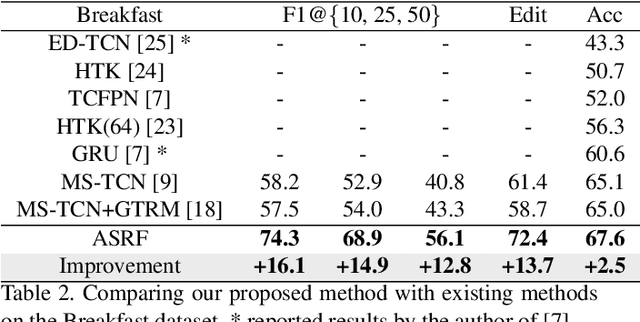
We propose an effective framework for the temporal action segmentation task, namely an Action Segment Refinement Framework (ASRF). Our model architecture consists of a long-term feature extractor and two branches: the Action Segmentation Branch (ASB) and the Boundary Regression Branch (BRB). The long-term feature extractor provides shared features for the two branches with a wide temporal receptive field. The ASB classifies video frames with action classes, while the BRB regresses the action boundary probabilities. The action boundaries predicted by the BRB refine the output from the ASB, which results in a significant performance improvement. Our contributions are three-fold: (i) We propose a framework for temporal action segmentation, the ASRF, which divides temporal action segmentation into frame-wise action classification and action boundary regression. Our framework refines frame-level hypotheses of action classes using predicted action boundaries. (ii) We propose a loss function for smoothing the transition of action probabilities, and analyze combinations of various loss functions for temporal action segmentation. (iii) Our framework outperforms state-of-the-art methods on three challenging datasets, offering an improvement of up to 13.7% in terms of segmental edit distance and up to 16.1% in terms of segmental F1 score. Our code will be publicly available soon.
Retrieving and Highlighting Action with Spatiotemporal Reference
May 19, 2020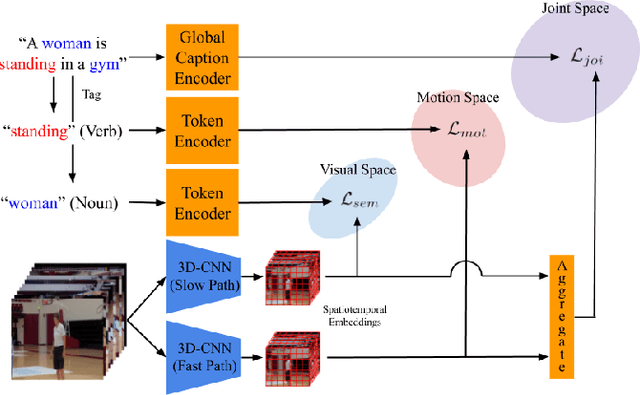
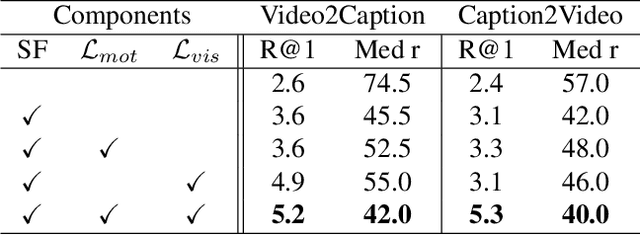
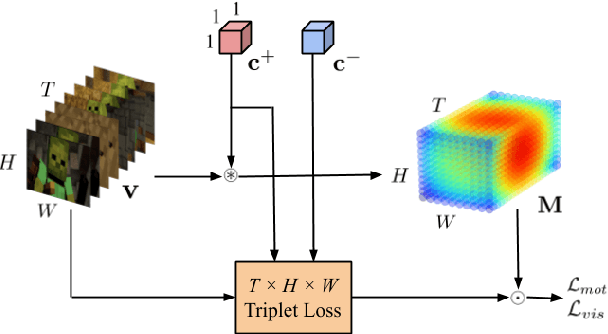

In this paper, we present a framework that jointly retrieves and spatiotemporally highlights actions in videos by enhancing current deep cross-modal retrieval methods. Our work takes on the novel task of action highlighting, which visualizes where and when actions occur in an untrimmed video setting. Action highlighting is a fine-grained task, compared to conventional action recognition tasks which focus on classification or window-based localization. Leveraging weak supervision from annotated captions, our framework acquires spatiotemporal relevance maps and generates local embeddings which relate to the nouns and verbs in captions. Through experiments, we show that our model generates various maps conditioned on different actions, in which conventional visual reasoning methods only go as far as to show a single deterministic saliency map. Also, our model improves retrieval recall over our baseline without alignment by 2-3% on the MSR-VTT dataset.