 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDETECLAP: Enhancing Audio-Visual Representation Learning with Object Information
Sep 18, 2024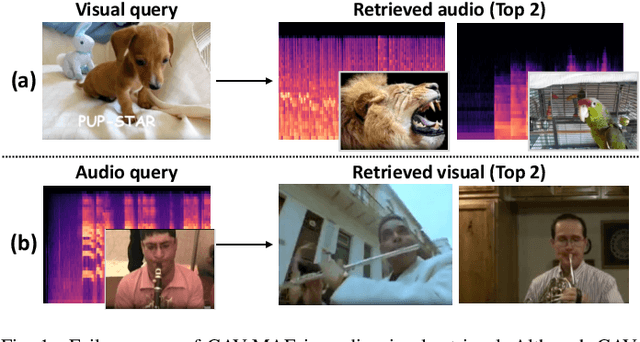
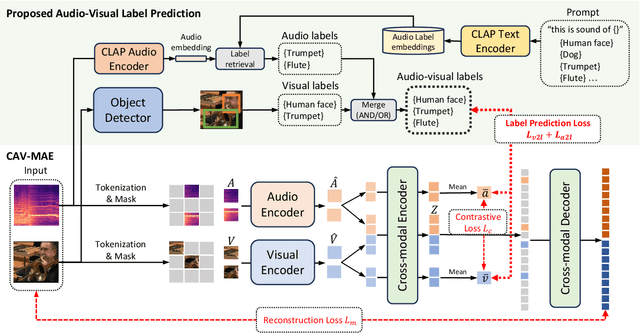
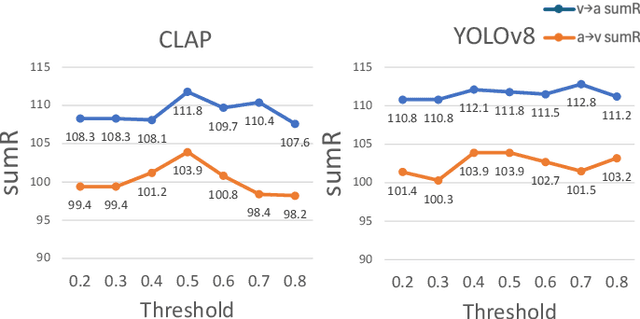

Current audio-visual representation learning can capture rough object categories (e.g., ``animals'' and ``instruments''), but it lacks the ability to recognize fine-grained details, such as specific categories like ``dogs'' and ``flutes'' within animals and instruments. To address this issue, we introduce DETECLAP, a method to enhance audio-visual representation learning with object information. Our key idea is to introduce an audio-visual label prediction loss to the existing Contrastive Audio-Visual Masked AutoEncoder to enhance its object awareness. To avoid costly manual annotations, we prepare object labels from both audio and visual inputs using state-of-the-art language-audio models and object detectors. We evaluate the method of audio-visual retrieval and classification using the VGGSound and AudioSet20K datasets. Our method achieves improvements in recall@10 of +1.5% and +1.2% for audio-to-visual and visual-to-audio retrieval, respectively, and an improvement in accuracy of +0.6% for audio-visual classification.
Data Collection-free Masked Video Modeling
Sep 10, 2024



Pre-training video transformers generally requires a large amount of data, presenting significant challenges in terms of data collection costs and concerns related to privacy, licensing, and inherent biases. Synthesizing data is one of the promising ways to solve these issues, yet pre-training solely on synthetic data has its own challenges. In this paper, we introduce an effective self-supervised learning framework for videos that leverages readily available and less costly static images. Specifically, we define the Pseudo Motion Generator (PMG) module that recursively applies image transformations to generate pseudo-motion videos from images. These pseudo-motion videos are then leveraged in masked video modeling. Our approach is applicable to synthetic images as well, thus entirely freeing video pre-training from data collection costs and other concerns in real data. Through experiments in action recognition tasks, we demonstrate that this framework allows effective learning of spatio-temporal features through pseudo-motion videos, significantly improving over existing methods which also use static images and partially outperforming those using both real and synthetic videos. These results uncover fragments of what video transformers learn through masked video modeling.
On the Audio Hallucinations in Large Audio-Video Language Models
Jan 18, 2024Large audio-video language models can generate descriptions for both video and audio. However, they sometimes ignore audio content, producing audio descriptions solely reliant on visual information. This paper refers to this as audio hallucinations and analyzes them in large audio-video language models. We gather 1,000 sentences by inquiring about audio information and annotate them whether they contain hallucinations. If a sentence is hallucinated, we also categorize the type of hallucination. The results reveal that 332 sentences are hallucinated with distinct trends observed in nouns and verbs for each hallucination type. Based on this, we tackle a task of audio hallucination classification using pre-trained audio-text models in the zero-shot and fine-tuning settings. Our experimental results reveal that the zero-shot models achieve higher performance (52.2% in F1) than the random (40.3%) and the fine-tuning models achieve 87.9%, outperforming the zero-shot models.
Large-scale Vision-Language Models Learn Super Images for Efficient and High-Performance Partially Relevant Video Retrieval
Dec 01, 2023



In this paper, we propose an efficient and high-performance method for partially relevant video retrieval (PRVR), which aims to retrieve untrimmed long videos that contain at least one relevant moment to the input text query. In terms of both efficiency and performance, the overlooked bottleneck of previous studies is the visual encoding of dense frames. This guides researchers to choose lightweight visual backbones, yielding sub-optimal retrieval performance due to their limited capabilities of learned visual representations. However, it is undesirable to simply replace them with high-performance large-scale vision-and-language models (VLMs) due to their low efficiency. To address these issues, instead of dense frames, we focus on super images, which are created by rearranging the video frames in a $N \times N$ grid layout. This reduces the number of visual encodings to $\frac{1}{N^2}$ and compensates for the low efficiency of large-scale VLMs, allowing us to adopt them as powerful encoders. Surprisingly, we discover that with a simple query-image attention trick, VLMs generalize well to super images effectively and demonstrate promising zero-shot performance against SOTA methods efficiently. In addition, we propose a fine-tuning approach by incorporating a few trainable modules into the VLM backbones. The experimental results demonstrate that our approaches efficiently achieve the best performance on ActivityNet Captions and TVR.
Leveraging Image-Text Similarity and Caption Modification for the DataComp Challenge: Filtering Track and BYOD Track
Oct 23, 2023Large web crawl datasets have already played an important role in learning multimodal features with high generalization capabilities. However, there are still very limited studies investigating the details or improvements of data design. Recently, a DataComp challenge has been designed to propose the best training data with the fixed models. This paper presents our solution to both filtering track and BYOD track of the DataComp challenge. Our solution adopts large multimodal models CLIP and BLIP-2 to filter and modify web crawl data, and utilize external datasets along with a bag of tricks to improve the data quality. Experiments show our solution significantly outperforms DataComp baselines (filtering track: 6.6% improvement, BYOD track: 48.5% improvement).