 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree Things to Know about Deep Metric Learning
Paper and Code
Dec 17, 2024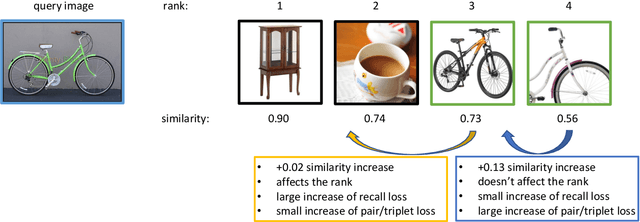
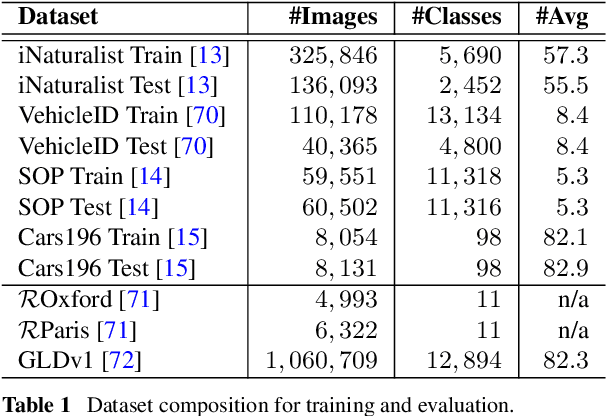
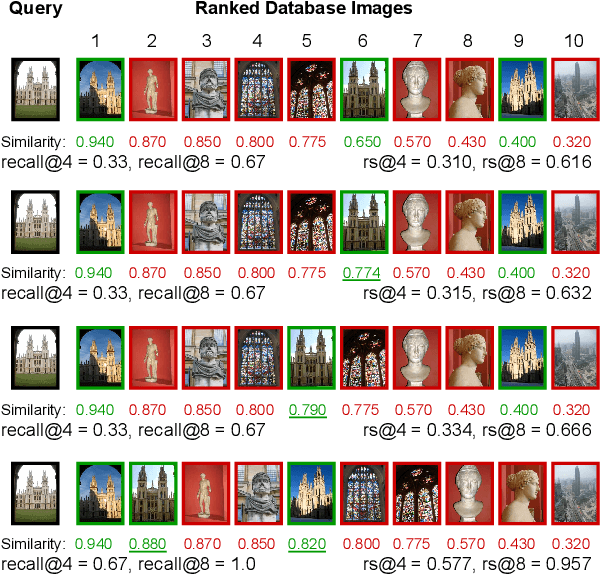

This paper addresses supervised deep metric learning for open-set image retrieval, focusing on three key aspects: the loss function, mixup regularization, and model initialization. In deep metric learning, optimizing the retrieval evaluation metric, recall@k, via gradient descent is desirable but challenging due to its non-differentiable nature. To overcome this, we propose a differentiable surrogate loss that is computed on large batches, nearly equivalent to the entire training set. This computationally intensive process is made feasible through an implementation that bypasses the GPU memory limitations. Additionally, we introduce an efficient mixup regularization technique that operates on pairwise scalar similarities, effectively increasing the batch size even further. The training process is further enhanced by initializing the vision encoder using foundational models, which are pre-trained on large-scale datasets. Through a systematic study of these components, we demonstrate that their synergy enables large models to nearly solve popular benchmarks.