 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPOSS: Label Propagation Over Patches and Pixels for Open-vocabulary Semantic Segmentation
Mar 25, 2025We propose a training-free method for open-vocabulary semantic segmentation using Vision-and-Language Models (VLMs). Our approach enhances the initial per-patch predictions of VLMs through label propagation, which jointly optimizes predictions by incorporating patch-to-patch relationships. Since VLMs are primarily optimized for cross-modal alignment and not for intra-modal similarity, we use a Vision Model (VM) that is observed to better capture these relationships. We address resolution limitations inherent to patch-based encoders by applying label propagation at the pixel level as a refinement step, significantly improving segmentation accuracy near class boundaries. Our method, called LPOSS+, performs inference over the entire image, avoiding window-based processing and thereby capturing contextual interactions across the full image. LPOSS+ achieves state-of-the-art performance among training-free methods, across a diverse set of datasets. Code: https://github.com/vladan-stojnic/LPOSS
ILIAS: Instance-Level Image retrieval At Scale
Feb 17, 2025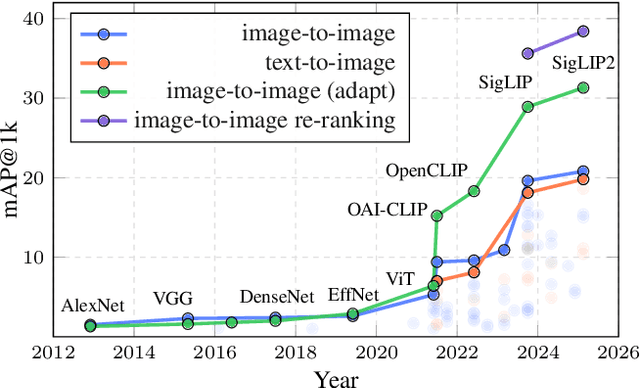
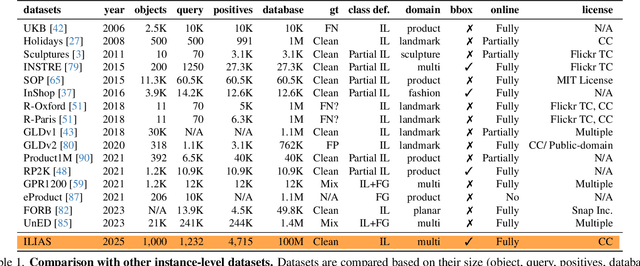

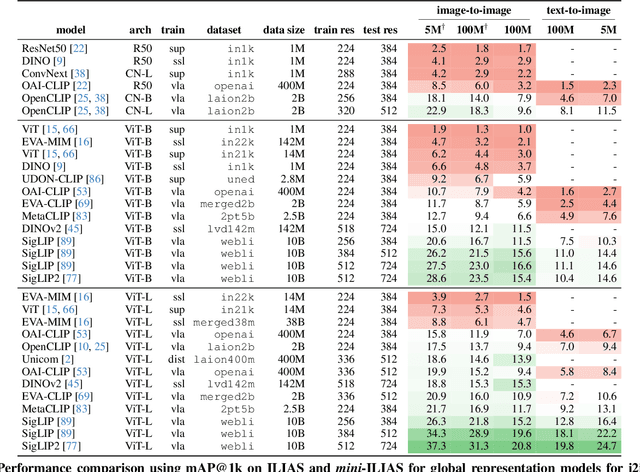
This work introduces ILIAS, a new test dataset for Instance-Level Image retrieval At Scale. It is designed to evaluate the ability of current and future foundation models and retrieval techniques to recognize particular objects. The key benefits over existing datasets include large scale, domain diversity, accurate ground truth, and a performance that is far from saturated. ILIAS includes query and positive images for 1,000 object instances, manually collected to capture challenging conditions and diverse domains. Large-scale retrieval is conducted against 100 million distractor images from YFCC100M. To avoid false negatives without extra annotation effort, we include only query objects confirmed to have emerged after 2014, i.e. the compilation date of YFCC100M. An extensive benchmarking is performed with the following observations: i) models fine-tuned on specific domains, such as landmarks or products, excel in that domain but fail on ILIAS ii) learning a linear adaptation layer using multi-domain class supervision results in performance improvements, especially for vision-language models iii) local descriptors in retrieval re-ranking are still a key ingredient, especially in the presence of severe background clutter iv) the text-to-image performance of the vision-language foundation models is surprisingly close to the corresponding image-to-image case. website: https://vrg.fel.cvut.cz/ilias/
Label Propagation for Zero-shot Classification with Vision-Language Models
Apr 05, 2024



Vision-Language Models (VLMs) have demonstrated impressive performance on zero-shot classification, i.e. classification when provided merely with a list of class names. In this paper, we tackle the case of zero-shot classification in the presence of unlabeled data. We leverage the graph structure of the unlabeled data and introduce ZLaP, a method based on label propagation (LP) that utilizes geodesic distances for classification. We tailor LP to graphs containing both text and image features and further propose an efficient method for performing inductive inference based on a dual solution and a sparsification step. We perform extensive experiments to evaluate the effectiveness of our method on 14 common datasets and show that ZLaP outperforms the latest related works. Code: https://github.com/vladan-stojnic/ZLaP
Training Ensembles with Inliers and Outliers for Semi-supervised Active Learning
Jul 07, 2023
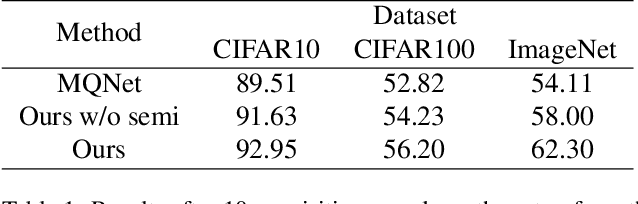


Deep active learning in the presence of outlier examples poses a realistic yet challenging scenario. Acquiring unlabeled data for annotation requires a delicate balance between avoiding outliers to conserve the annotation budget and prioritizing useful inlier examples for effective training. In this work, we present an approach that leverages three highly synergistic components, which are identified as key ingredients: joint classifier training with inliers and outliers, semi-supervised learning through pseudo-labeling, and model ensembling. Our work demonstrates that ensembling significantly enhances the accuracy of pseudo-labeling and improves the quality of data acquisition. By enabling semi-supervision through the joint training process, where outliers are properly handled, we observe a substantial boost in classifier accuracy through the use of all available unlabeled examples. Notably, we reveal that the integration of joint training renders explicit outlier detection unnecessary; a conventional component for acquisition in prior work. The three key components align seamlessly with numerous existing approaches. Through empirical evaluations, we showcase that their combined use leads to a performance increase. Remarkably, despite its simplicity, our proposed approach outperforms all other methods in terms of performance. Code: https://github.com/vladan-stojnic/active-outliers
The Role of Pre-Training in High-Resolution Remote Sensing Scene Classification
Nov 05, 2021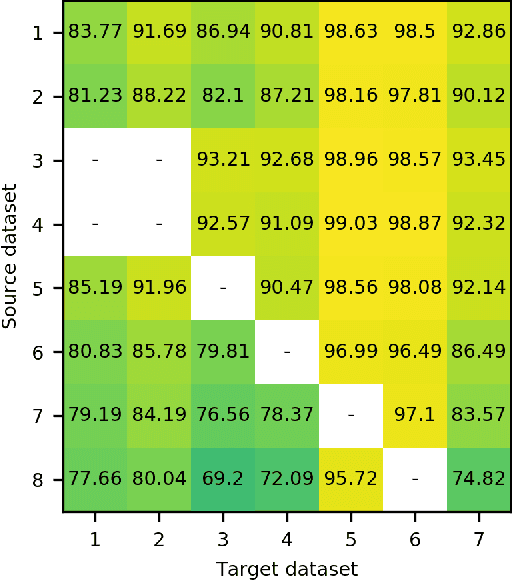
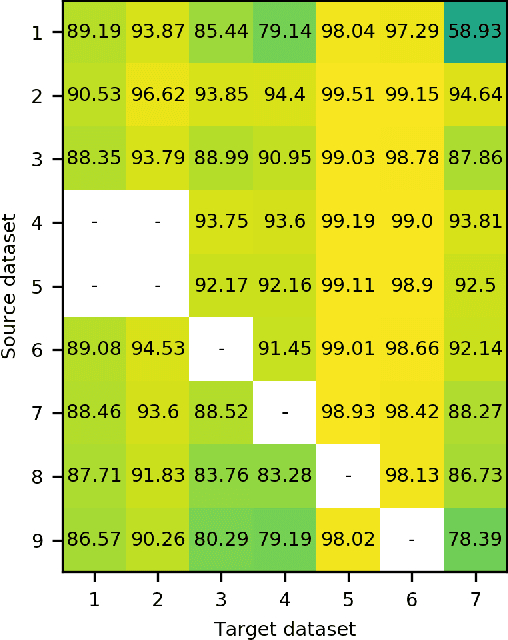

Due to the scarcity of labeled data, using models pre-trained on ImageNet is a de facto standard in remote sensing scene classification. Although, recently, several larger high resolution remote sensing (HRRS) datasets have appeared with a goal of establishing new benchmarks, attempts at training models from scratch on these datasets are sporadic. In this paper, we show that training models from scratch on several newer datasets yields comparable results to fine-tuning the models pre-trained on ImageNet. Furthermore, the representations learned on HRRS datasets transfer to other HRRS scene classification tasks better or at least similarly as those learned on ImageNet. Finally, we show that in many cases the best representations are obtained by using a second round of pre-training using in-domain data, i.e. domain-adaptive pre-training. The source code and pre-trained models are available at \url{https://github.com/risojevicv/RSSC-transfer.}
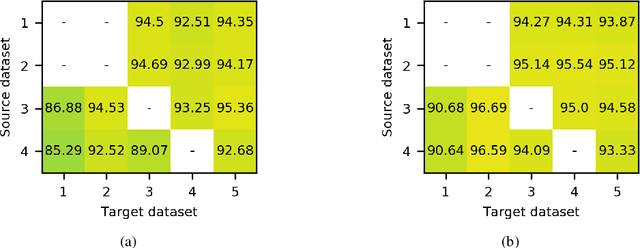
Self-Supervised Learning of Remote Sensing Scene Representations Using Contrastive Multiview Coding
Apr 14, 2021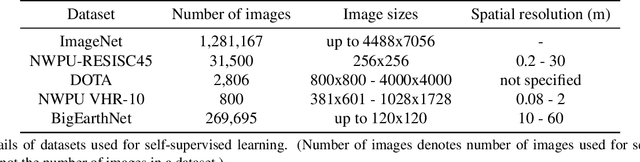
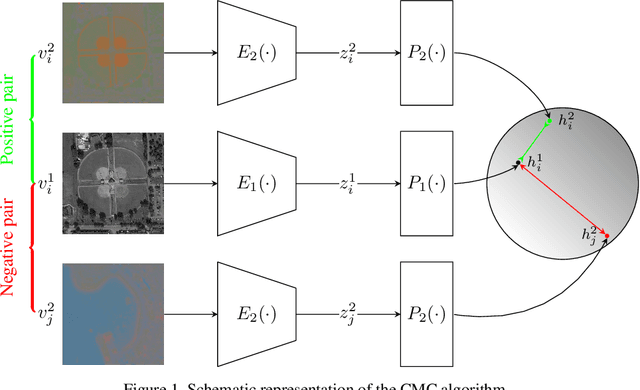

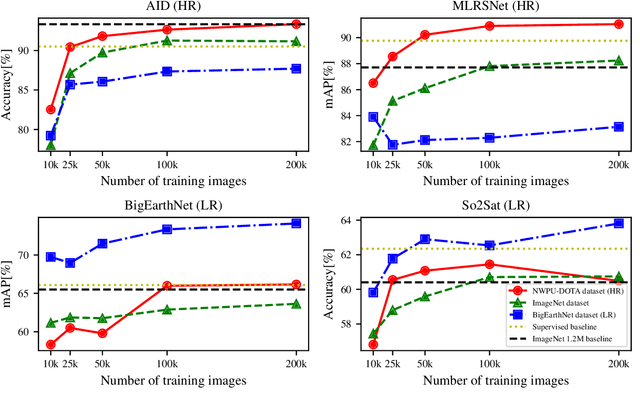
In recent years self-supervised learning has emerged as a promising candidate for unsupervised representation learning. In the visual domain its applications are mostly studied in the context of images of natural scenes. However, its applicability is especially interesting in specific areas, like remote sensing and medicine, where it is hard to obtain huge amounts of labeled data. In this work, we conduct an extensive analysis of the applicability of self-supervised learning in remote sensing image classification. We analyze the influence of the number and domain of images used for self-supervised pre-training on the performance on downstream tasks. We show that, for the downstream task of remote sensing image classification, using self-supervised pre-training on remote sensing images can give better results than using supervised pre-training on images of natural scenes. Besides, we also show that self-supervised pre-training can be easily extended to multispectral images producing even better results on our downstream tasks.