 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Localization of Body and Finger Animation Skeleton Joints on Three-Dimensional Models of Human Bodies
Jul 11, 2024



Contemporary approaches to solving various problems that require analyzing three-dimensional (3D) meshes and point clouds have adopted the use of deep learning algorithms that directly process 3D data such as point coordinates, normal vectors and vertex connectivity information. Our work proposes one such solution to the problem of positioning body and finger animation skeleton joints within 3D models of human bodies. Due to scarcity of annotated real human scans, we resort to generating synthetic samples while varying their shape and pose parameters. Similarly to the state-of-the-art approach, our method computes each joint location as a convex combination of input points. Given only a list of point coordinates and normal vector estimates as input, a dynamic graph convolutional neural network is used to predict the coefficients of the convex combinations. By comparing our method with the state-of-the-art, we show that it is possible to achieve significantly better results with a simpler architecture, especially for finger joints. Since our solution requires fewer precomputed features, it also allows for shorter processing times.
* 6 pages, 5 figures, final published version is available at: https://ieeexplore.ieee.org/abstract/document/10579426, research code is available at: https://github.com/sznov/joint-localization
Nearest Neighbor Based Out-of-Distribution Detection in Remote Sensing Scene Classification
Mar 29, 2023Deep learning models for image classification are typically trained under the "closed-world" assumption with a predefined set of image classes. However, when the models are deployed they may be faced with input images not belonging to the classes encountered during training. This type of scenario is common in remote sensing image classification where images come from different geographic areas, sensors, and imaging conditions. In this paper we deal with the problem of detecting remote sensing images coming from a different distribution compared to the training data - out of distribution images. We propose a benchmark for out of distribution detection in remote sensing scene classification and evaluate detectors based on maximum softmax probability and nearest neighbors. The experimental results show convincing advantages of the method based on nearest neighbors.
The Role of Pre-Training in High-Resolution Remote Sensing Scene Classification
Nov 05, 2021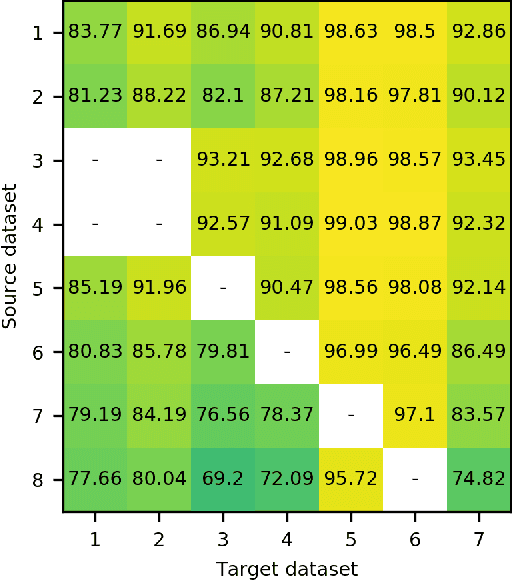
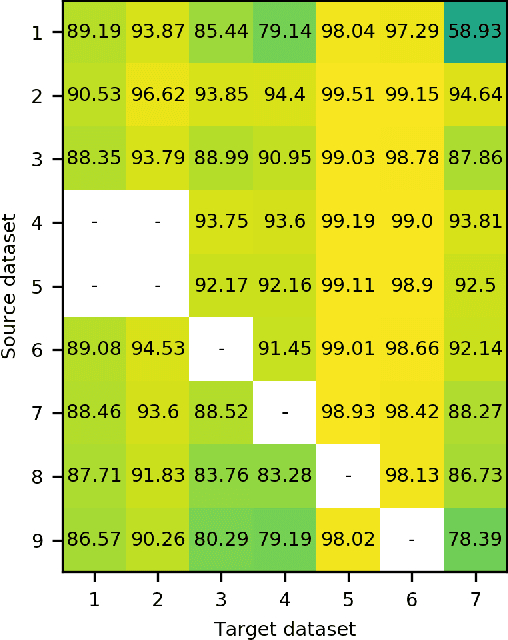

Due to the scarcity of labeled data, using models pre-trained on ImageNet is a de facto standard in remote sensing scene classification. Although, recently, several larger high resolution remote sensing (HRRS) datasets have appeared with a goal of establishing new benchmarks, attempts at training models from scratch on these datasets are sporadic. In this paper, we show that training models from scratch on several newer datasets yields comparable results to fine-tuning the models pre-trained on ImageNet. Furthermore, the representations learned on HRRS datasets transfer to other HRRS scene classification tasks better or at least similarly as those learned on ImageNet. Finally, we show that in many cases the best representations are obtained by using a second round of pre-training using in-domain data, i.e. domain-adaptive pre-training. The source code and pre-trained models are available at \url{https://github.com/risojevicv/RSSC-transfer.}
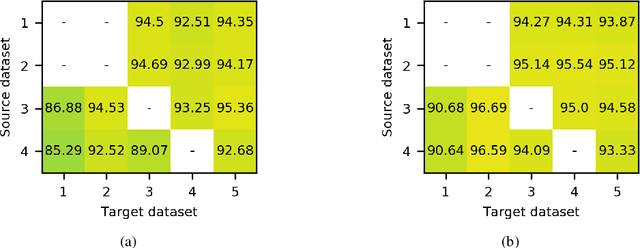
Self-Supervised Learning of Remote Sensing Scene Representations Using Contrastive Multiview Coding
Apr 14, 2021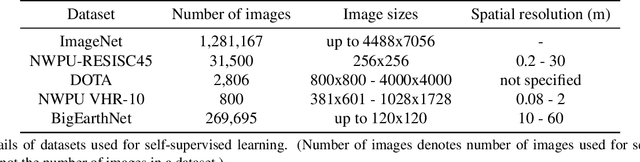
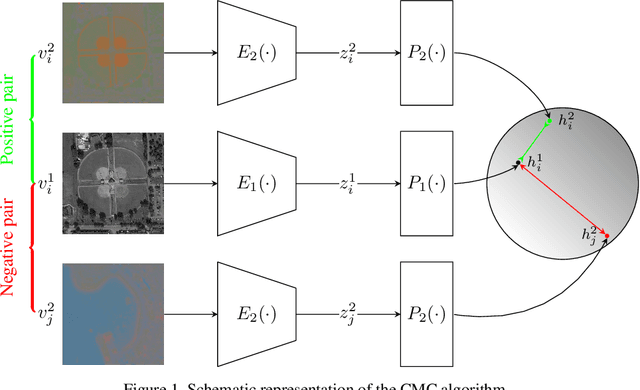

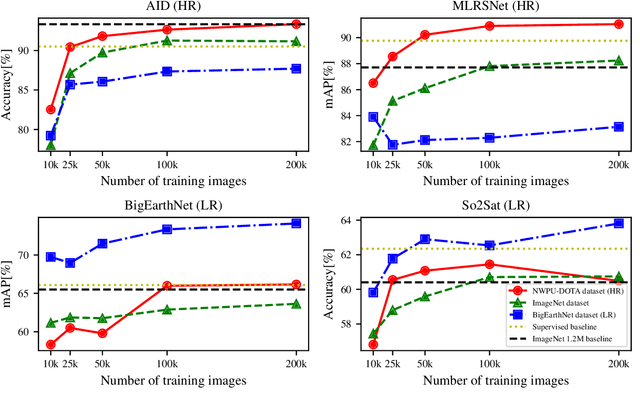
In recent years self-supervised learning has emerged as a promising candidate for unsupervised representation learning. In the visual domain its applications are mostly studied in the context of images of natural scenes. However, its applicability is especially interesting in specific areas, like remote sensing and medicine, where it is hard to obtain huge amounts of labeled data. In this work, we conduct an extensive analysis of the applicability of self-supervised learning in remote sensing image classification. We analyze the influence of the number and domain of images used for self-supervised pre-training on the performance on downstream tasks. We show that, for the downstream task of remote sensing image classification, using self-supervised pre-training on remote sensing images can give better results than using supervised pre-training on images of natural scenes. Besides, we also show that self-supervised pre-training can be easily extended to multispectral images producing even better results on our downstream tasks.