 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Subgoal Representations for Hierarchical Reinforcement learning
Jun 24, 2024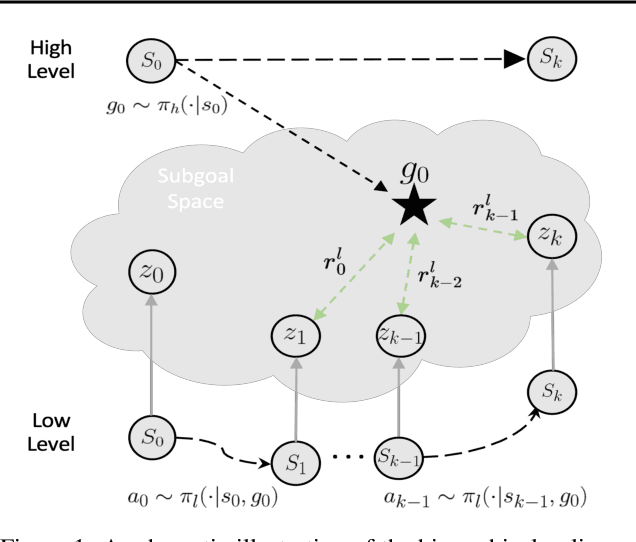
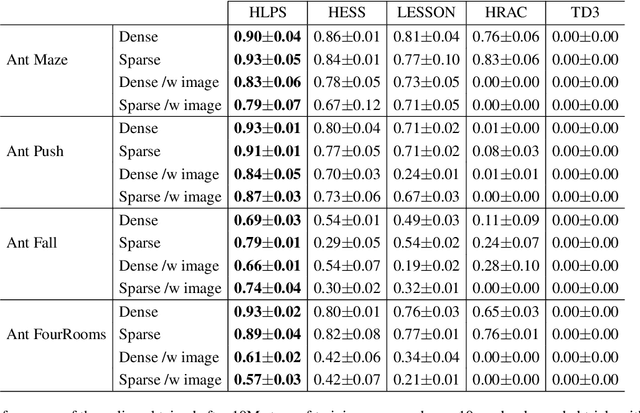
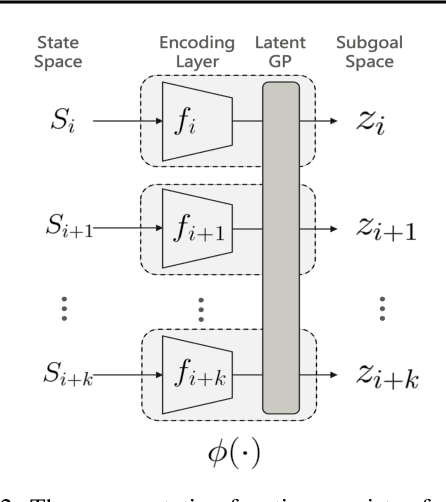
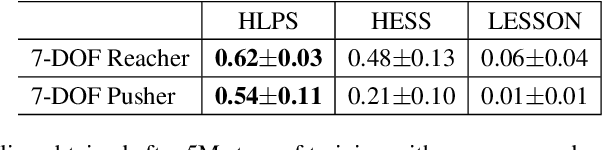
In goal-conditioned hierarchical reinforcement learning (HRL), a high-level policy specifies a subgoal for the low-level policy to reach. Effective HRL hinges on a suitable subgoal represen tation function, abstracting state space into latent subgoal space and inducing varied low-level behaviors. Existing methods adopt a subgoal representation that provides a deterministic mapping from state space to latent subgoal space. Instead, this paper utilizes Gaussian Processes (GPs) for the first probabilistic subgoal representation. Our method employs a GP prior on the latent subgoal space to learn a posterior distribution over the subgoal representation functions while exploiting the long-range correlation in the state space through learnable kernels. This enables an adaptive memory that integrates long-range subgoal information from prior planning steps allowing to cope with stochastic uncertainties. Furthermore, we propose a novel learning objective to facilitate the simultaneous learning of probabilistic subgoal representations and policies within a unified framework. In experiments, our approach outperforms state-of-the-art baselines in standard benchmarks but also in environments with stochastic elements and under diverse reward conditions. Additionally, our model shows promising capabilities in transferring low-level policies across different tasks.
Hierarchical Reinforcement Learning with Adversarially Guided Subgoals
Jan 31, 2022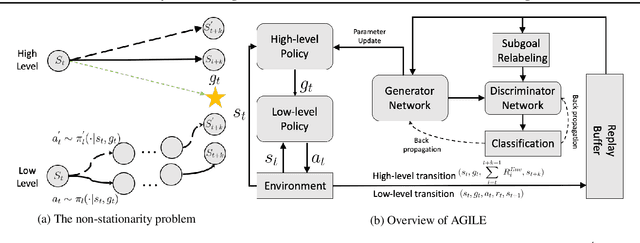
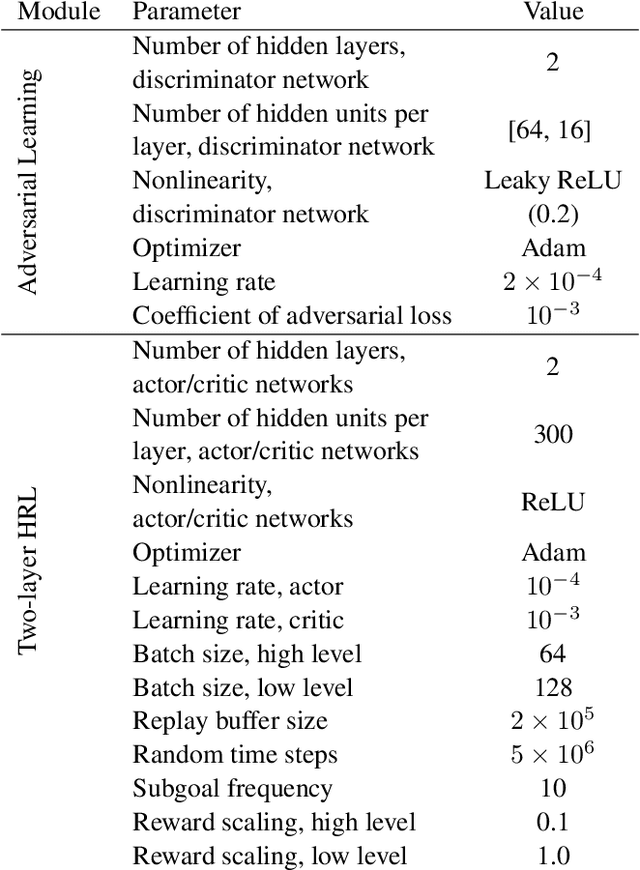

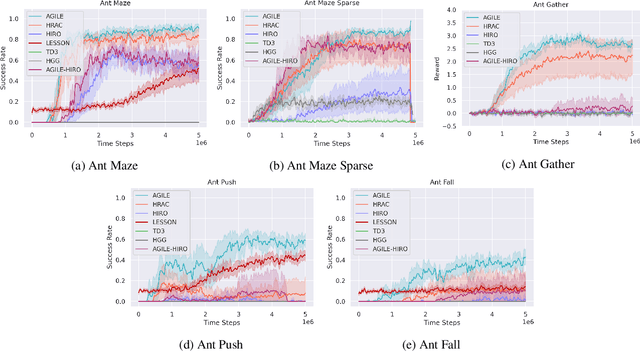
Hierarchical reinforcement learning (HRL) proposes to solve difficult tasks by performing decision-making and control at successively higher levels of temporal abstraction. However, off-policy HRL often suffers from the problem of non-stationary high-level policy since the low-level policy is constantly changing. In this paper, we propose a novel HRL approach for mitigating the non-stationarity by adversarially enforcing the high-level policy to generate subgoals compatible with the current instantiation of the low-level policy. In practice, the adversarial learning is implemented by training a simple discriminator network concurrently with the high-level policy which determines the compatibility level of subgoals. Experiments with state-of-the-art algorithms show that our approach improves both HRL learning efficiency and overall performance in various challenging continuous control tasks.