 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneously Learning Architectures and Features of Deep Neural Networks
Paper and Code
Jun 11, 2019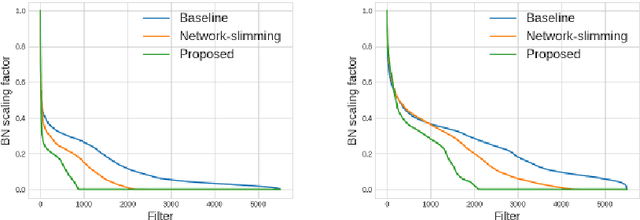
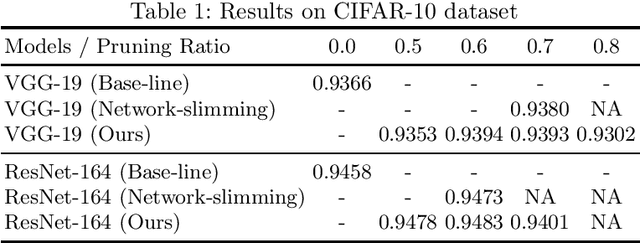
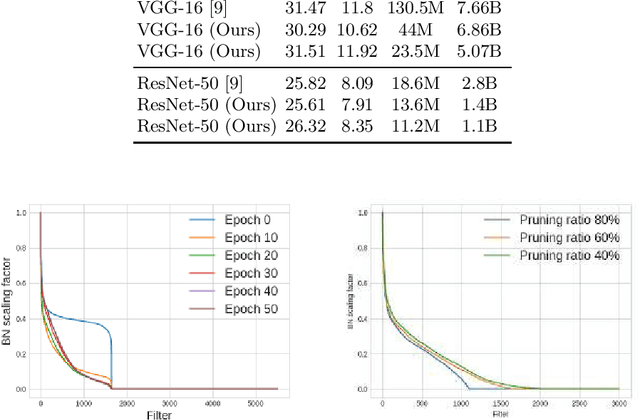
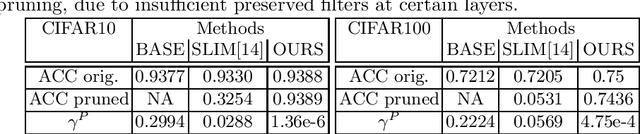
This paper presents a novel method which simultaneously learns the number of filters and network features repeatedly over multiple epochs. We propose a novel pruning loss to explicitly enforces the optimizer to focus on promising candidate filters while suppressing contributions of less relevant ones. In the meanwhile, we further propose to enforce the diversities between filters and this diversity-based regularization term improves the trade-off between model sizes and accuracies. It turns out the interplay between architecture and feature optimizations improves the final compressed models, and the proposed method is compared favorably to existing methods, in terms of both models sizes and accuracies for a wide range of applications including image classification, image compression and audio classification.