 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAGUNA: LAnguage Guided UNsupervised Adaptation with structured spaces
Nov 23, 2024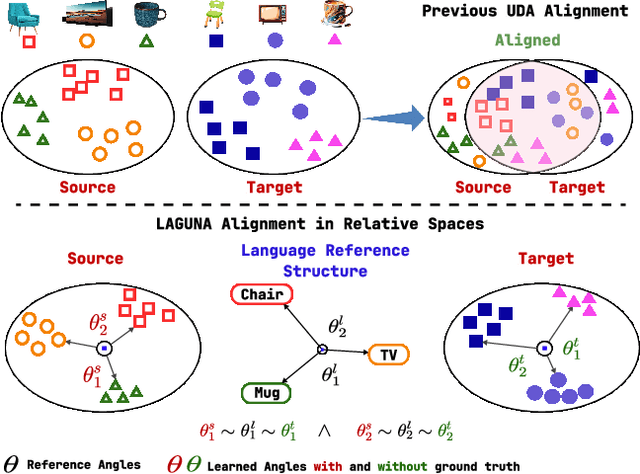
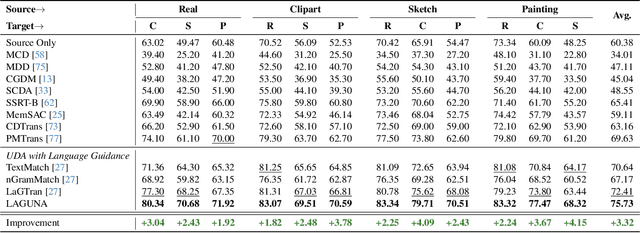
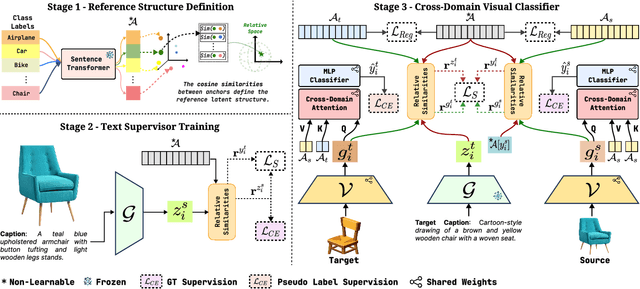
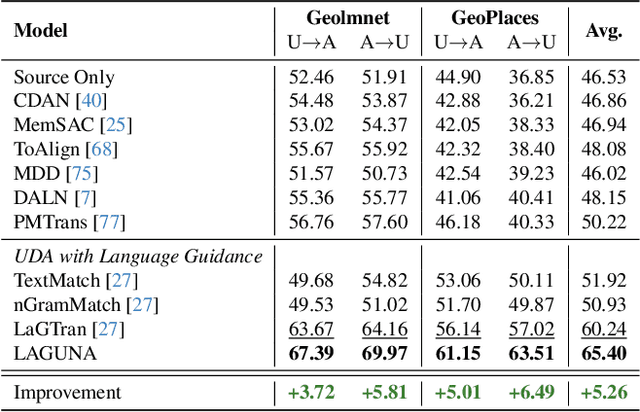
Unsupervised domain adaptation remains a critical challenge in enabling the knowledge transfer of models across unseen domains. Existing methods struggle to balance the need for domain-invariant representations with preserving domain-specific features, which is often due to alignment approaches that impose the projection of samples with similar semantics close in the latent space despite their drastic domain differences. We introduce \mnamelong, a novel approach that shifts the focus from aligning representations in absolute coordinates to aligning the relative positioning of equivalent concepts in latent spaces. \mname defines a domain-agnostic structure upon the semantic/geometric relationships between class labels in language space and guides adaptation, ensuring that the organization of samples in visual space reflects reference inter-class relationships while preserving domain-specific characteristics. %We empirically demonstrate \mname's superiority in domain adaptation tasks across four diverse images and video datasets. Remarkably, \mname surpasses previous works in 18 different adaptation scenarios across four diverse image and video datasets with average accuracy improvements of +3.32% on DomainNet, +5.75% in GeoPlaces, +4.77% on GeoImnet, and +1.94% mean class accuracy improvement on EgoExo4D.
ReWind: Understanding Long Videos with Instructed Learnable Memory
Nov 23, 2024Vision-Language Models (VLMs) are crucial for applications requiring integrated understanding textual and visual information. However, existing VLMs struggle with long videos due to computational inefficiency, memory limitations, and difficulties in maintaining coherent understanding across extended sequences. To address these challenges, we introduce ReWind, a novel memory-based VLM designed for efficient long video understanding while preserving temporal fidelity. ReWind operates in a two-stage framework. In the first stage, ReWind maintains a dynamic learnable memory module with a novel \textbf{read-perceive-write} cycle that stores and updates instruction-relevant visual information as the video unfolds. This module utilizes learnable queries and cross-attentions between memory contents and the input stream, ensuring low memory requirements by scaling linearly with the number of tokens. In the second stage, we propose an adaptive frame selection mechanism guided by the memory content to identify instruction-relevant key moments. It enriches the memory representations with detailed spatial information by selecting a few high-resolution frames, which are then combined with the memory contents and fed into a Large Language Model (LLM) to generate the final answer. We empirically demonstrate ReWind's superior performance in visual question answering (VQA) and temporal grounding tasks, surpassing previous methods on long video benchmarks. Notably, ReWind achieves a +13\% score gain and a +12\% accuracy improvement on the MovieChat-1K VQA dataset and an +8\% mIoU increase on Charades-STA for temporal grounding.
ReViT: Enhancing Vision Transformers with Attention Residual Connections for Visual Recognition
Feb 17, 2024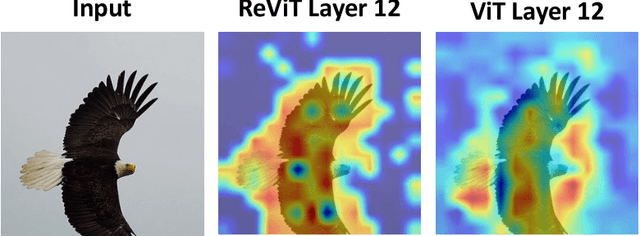
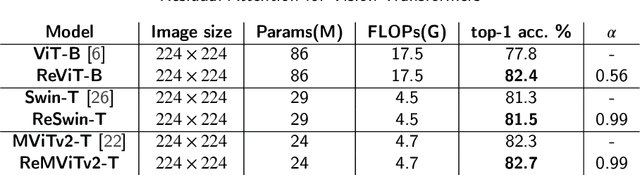
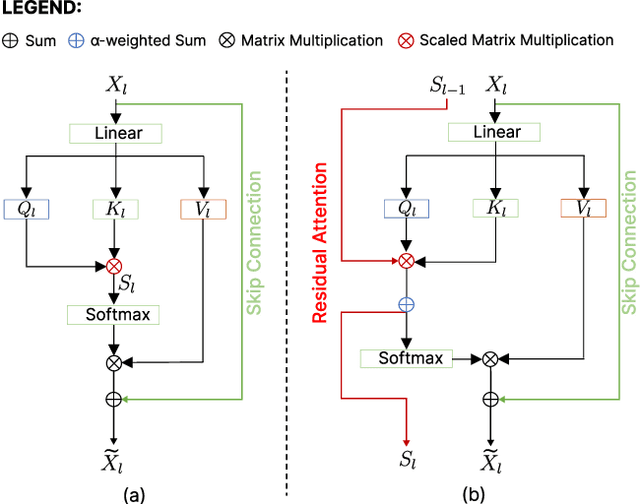
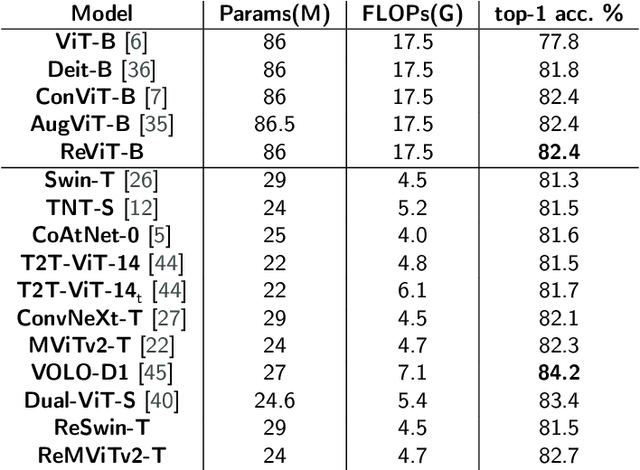
Vision Transformer (ViT) self-attention mechanism is characterized by feature collapse in deeper layers, resulting in the vanishing of low-level visual features. However, such features can be helpful to accurately represent and identify elements within an image and increase the accuracy and robustness of vision-based recognition systems. Following this rationale, we propose a novel residual attention learning method for improving ViT-based architectures, increasing their visual feature diversity and model robustness. In this way, the proposed network can capture and preserve significant low-level features, providing more details about the elements within the scene being analyzed. The effectiveness and robustness of the presented method are evaluated on five image classification benchmarks, including ImageNet1k, CIFAR10, CIFAR100, Oxford Flowers-102, and Oxford-IIIT Pet, achieving improved performances. Additionally, experiments on the COCO2017 dataset show that the devised approach discovers and incorporates semantic and spatial relationships for object detection and instance segmentation when implemented into spatial-aware transformer models.