 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReViT: Enhancing Vision Transformers with Attention Residual Connections for Visual Recognition
Feb 17, 2024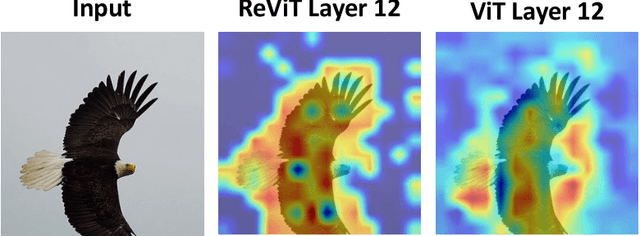
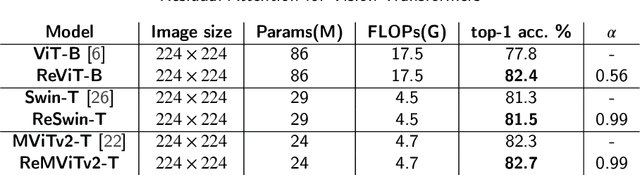
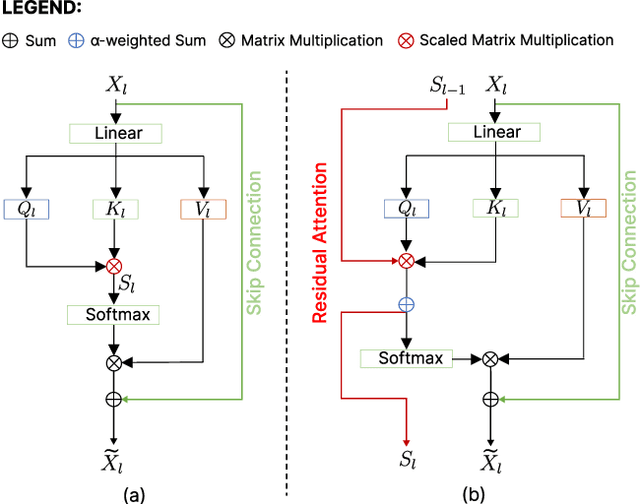
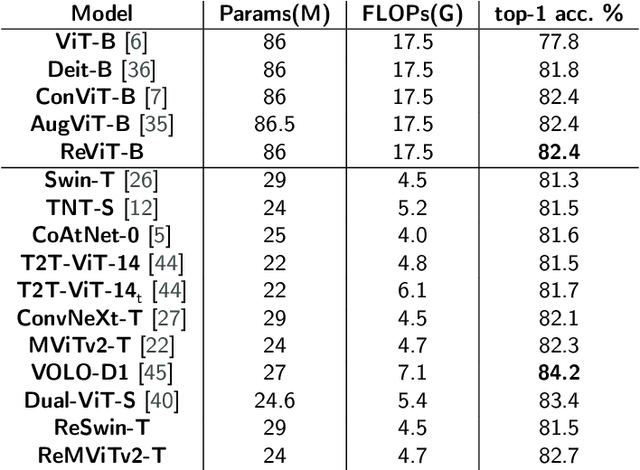
Vision Transformer (ViT) self-attention mechanism is characterized by feature collapse in deeper layers, resulting in the vanishing of low-level visual features. However, such features can be helpful to accurately represent and identify elements within an image and increase the accuracy and robustness of vision-based recognition systems. Following this rationale, we propose a novel residual attention learning method for improving ViT-based architectures, increasing their visual feature diversity and model robustness. In this way, the proposed network can capture and preserve significant low-level features, providing more details about the elements within the scene being analyzed. The effectiveness and robustness of the presented method are evaluated on five image classification benchmarks, including ImageNet1k, CIFAR10, CIFAR100, Oxford Flowers-102, and Oxford-IIIT Pet, achieving improved performances. Additionally, experiments on the COCO2017 dataset show that the devised approach discovers and incorporates semantic and spatial relationships for object detection and instance segmentation when implemented into spatial-aware transformer models.
Analyzing EEG Data with Machine and Deep Learning: A Benchmark
Mar 18, 2022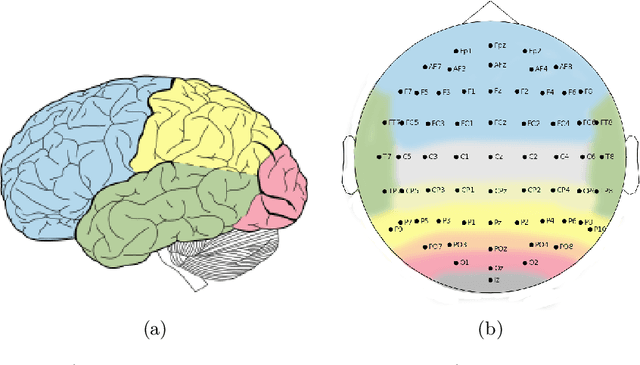

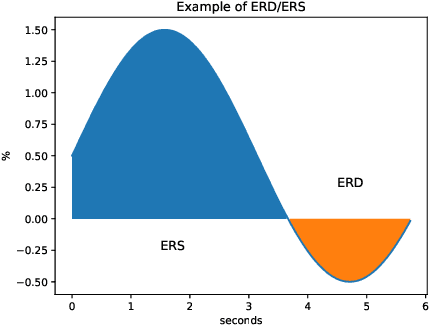

Nowadays, machine and deep learning techniques are widely used in different areas, ranging from economics to biology. In general, these techniques can be used in two ways: trying to adapt well-known models and architectures to the available data, or designing custom architectures. In both cases, to speed up the research process, it is useful to know which type of models work best for a specific problem and/or data type. By focusing on EEG signal analysis, and for the first time in literature, in this paper a benchmark of machine and deep learning for EEG signal classification is proposed. For our experiments we used the four most widespread models, i.e., multilayer perceptron, convolutional neural network, long short-term memory, and gated recurrent unit, highlighting which one can be a good starting point for developing EEG classification models.
Human Silhouette and Skeleton Video Synthesis through Wi-Fi signals
Mar 11, 2022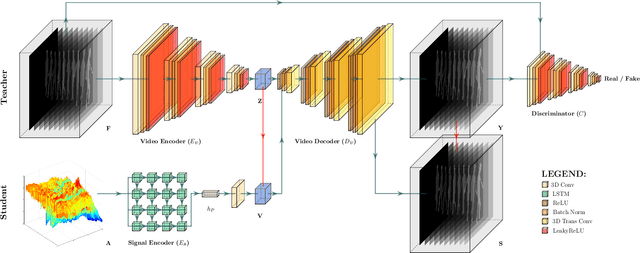
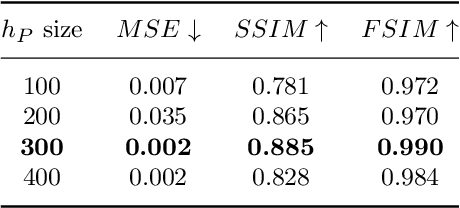
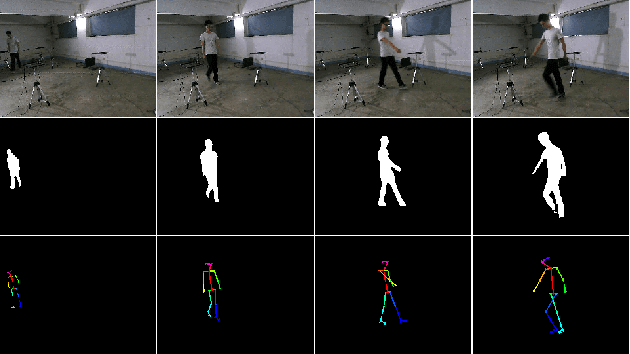
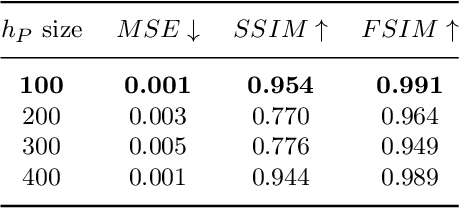
The increasing availability of wireless access points (APs) is leading towards human sensing applications based on Wi-Fi signals as support or alternative tools to the widespread visual sensors, where the signals enable to address well-known vision-related problems such as illumination changes or occlusions. Indeed, using image synthesis techniques to translate radio frequencies to the visible spectrum can become essential to obtain otherwise unavailable visual data. This domain-to-domain translation is feasible because both objects and people affect electromagnetic waves, causing radio and optical frequencies variations. In literature, models capable of inferring radio-to-visual features mappings have gained momentum in the last few years since frequency changes can be observed in the radio domain through the channel state information (CSI) of Wi-Fi APs, enabling signal-based feature extraction, e.g., amplitude. On this account, this paper presents a novel two-branch generative neural network that effectively maps radio data into visual features, following a teacher-student design that exploits a cross-modality supervision strategy. The latter conditions signal-based features in the visual domain to completely replace visual data. Once trained, the proposed method synthesizes human silhouette and skeleton videos using exclusively Wi-Fi signals. The approach is evaluated on publicly available data, where it obtains remarkable results for both silhouette and skeleton videos generation, demonstrating the effectiveness of the proposed cross-modality supervision strategy.