 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Payload Optimization Method for Federated Recommender Systems
Jul 27, 2021



We introduce the payload optimization method for federated recommender systems (FRS). In federated learning (FL), the global model payload that is moved between the server and users depends on the number of items to recommend. The model payload grows when there is an increasing number of items. This becomes challenging for an FRS if it is running in production mode. To tackle the payload challenge, we formulated a multi-arm bandit solution that selected part of the global model and transmitted it to all users. The selection process was guided by a novel reward function suitable for FL systems. So far as we are aware, this is the first optimization method that seeks to address item dependent payloads. The method was evaluated using three benchmark recommendation datasets. The empirical validation confirmed that the proposed method outperforms the simpler methods that do not benefit from the bandits for the purpose of item selection. In addition, we have demonstrated the usefulness of our proposed method by rigorously evaluating the effects of a payload reduction on the recommendation performance degradation. Our method achieved up to a 90\% reduction in model payload, yielding only a $\sim$4\% - 8\% loss in the recommendation performance for highly sparse datasets
* 15 pages, 3 figures, 4 tables
Achieving Security and Privacy in Federated Learning Systems: Survey, Research Challenges and Future Directions
Dec 12, 2020

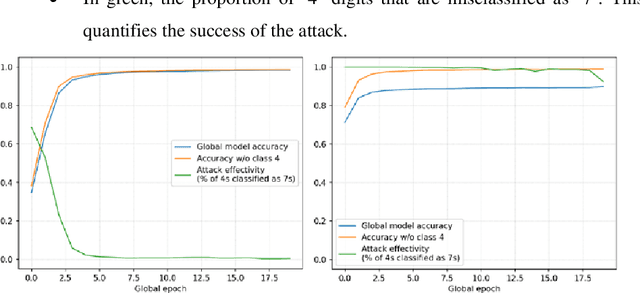
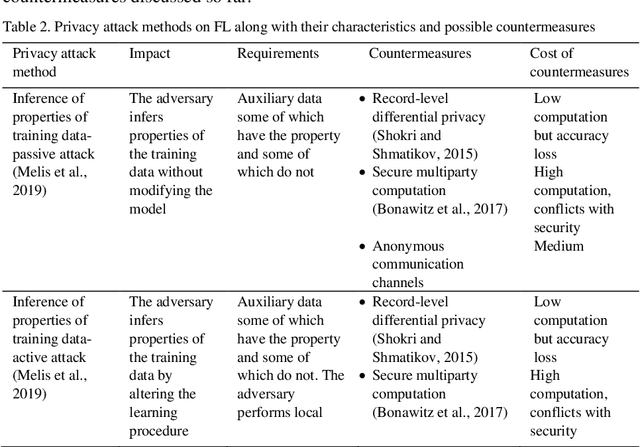
Federated learning (FL) allows a server to learn a machine learning (ML) model across multiple decentralized clients that privately store their own training data. In contrast with centralized ML approaches, FL saves computation to the server and does not require the clients to outsource their private data to the server. However, FL is not free of issues. On the one hand, the model updates sent by the clients at each training epoch might leak information on the clients' private data. On the other hand, the model learnt by the server may be subjected to attacks by malicious clients; these security attacks might poison the model or prevent it from converging. In this paper, we first examine security and privacy attacks to FL and critically survey solutions proposed in the literature to mitigate each attack. Afterwards, we discuss the difficulty of simultaneously achieving security and privacy protection. Finally, we sketch ways to tackle this open problem and attain both security and privacy.
A little goes a long way: Improving toxic language classification despite data scarcity
Sep 25, 2020

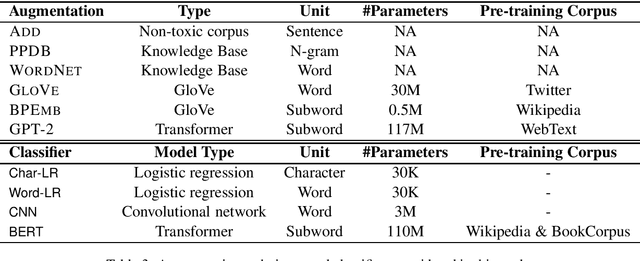
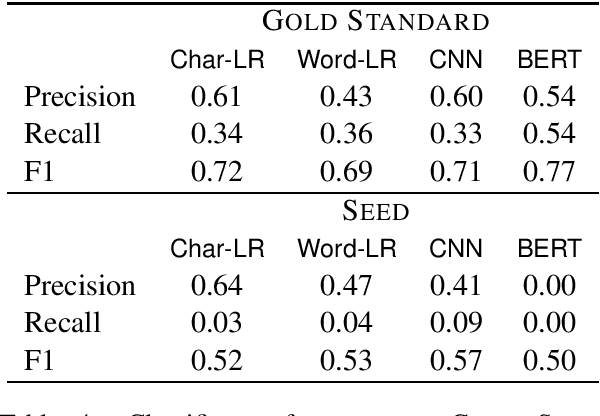
Detection of some types of toxic language is hampered by extreme scarcity of labeled training data. Data augmentation - generating new synthetic data from a labeled seed dataset - can help. The efficacy of data augmentation on toxic language classification has not been fully explored. We present the first systematic study on how data augmentation techniques impact performance across toxic language classifiers, ranging from shallow logistic regression architectures to BERT - a state-of-the-art pre-trained Transformer network. We compare the performance of eight techniques on very scarce seed datasets. We show that while BERT performed the best, shallow classifiers performed comparably when trained on data augmented with a combination of three techniques, including GPT-2-generated sentences. We discuss the interplay of performance and computational overhead, which can inform the choice of techniques under different constraints.
Federated Multi-view Matrix Factorization for Personalized Recommendations
Apr 08, 2020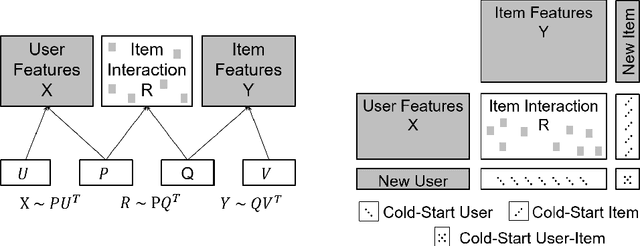

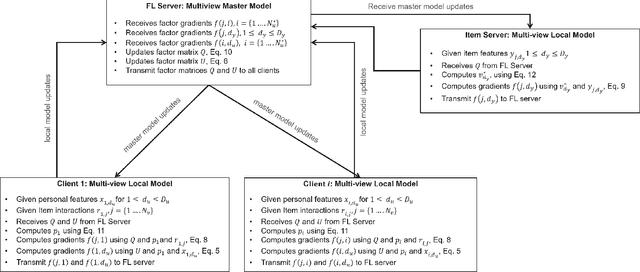
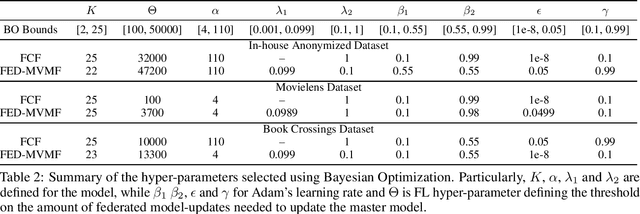
We introduce the federated multi-view matrix factorization method that extends the federated learning framework to matrix factorization with multiple data sources. Our method is able to learn the multi-view model without transferring the user's personal data to a central server. As far as we are aware this is the first federated model to provide recommendations using multi-view matrix factorization. The model is rigorously evaluated on three datasets on production settings. Empirical validation confirms that federated multi-view matrix factorization outperforms simpler methods that do not take into account the multi-view structure of the data, in addition, it demonstrates the usefulness of the proposed method for the challenging prediction tasks of cold-start federated recommendations.
Federated Collaborative Filtering for Privacy-Preserving Personalized Recommendation System
Jan 29, 2019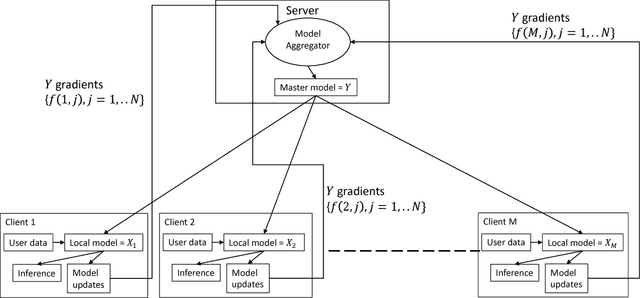
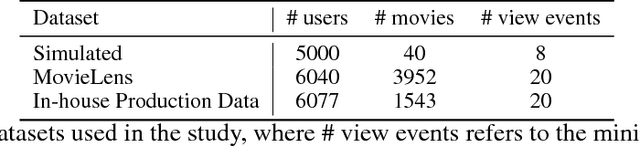
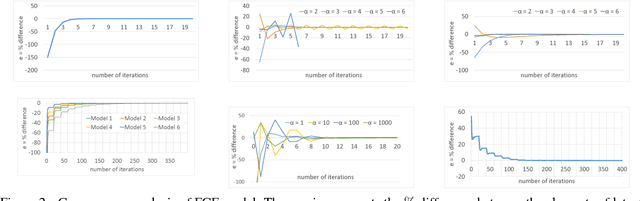
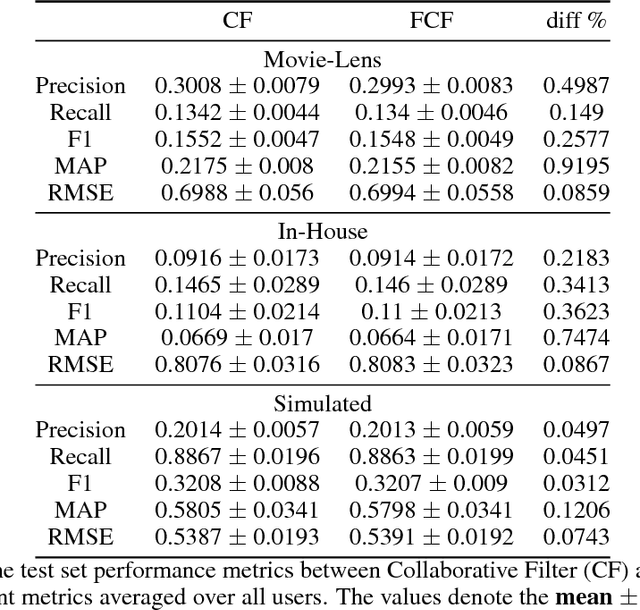
The increasing interest in user privacy is leading to new privacy preserving machine learning paradigms. In the Federated Learning paradigm, a master machine learning model is distributed to user clients, the clients use their locally stored data and model for both inference and calculating model updates. The model updates are sent back and aggregated on the server to update the master model then redistributed to the clients. In this paradigm, the user data never leaves the client, greatly enhancing the user' privacy, in contrast to the traditional paradigm of collecting, storing and processing user data on a backend server beyond the user's control. In this paper we introduce, as far as we are aware, the first federated implementation of a Collaborative Filter. The federated updates to the model are based on a stochastic gradient approach. As a classical case study in machine learning, we explore a personalized recommendation system based on users' implicit feedback and demonstrate the method's applicability to both the MovieLens and an in-house dataset. Empirical validation confirms a collaborative filter can be federated without a loss of accuracy compared to a standard implementation, hence enhancing the user's privacy in a widely used recommender application while maintaining recommender performance.