 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Transformers use variable binding?
Feb 19, 2022
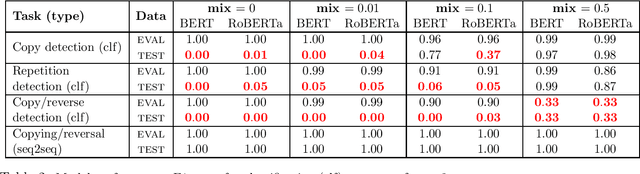

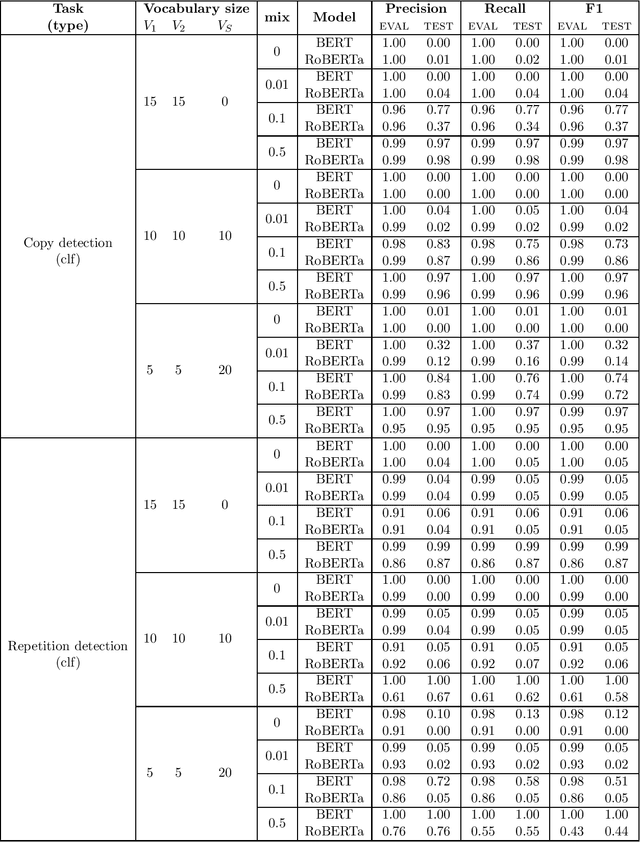
Increasing the explainability of deep neural networks (DNNs) requires evaluating whether they implement symbolic computation. One central symbolic capacity is variable binding: linking an input value to an abstract variable held in system-internal memory. Prior work on the computational abilities of DNNs has not resolved the question of whether their internal processes involve variable binding. We argue that the reason for this is fundamental, inherent in the way experiments in prior work were designed. We provide the first systematic evaluation of the variable binding capacities of the state-of-the-art Transformer networks BERT and RoBERTa. Our experiments are designed such that the model must generalize a rule across disjoint subsets of the input vocabulary, and cannot rely on associative pattern matching alone. The results show a clear discrepancy between classification and sequence-to-sequence tasks: BERT and RoBERTa can easily learn to copy or reverse strings even when trained on task-specific vocabularies that are switched in the test set; but both models completely fail to generalize across vocabularies in similar sequence classification tasks. These findings indicate that the effectiveness of Transformers in sequence modelling may lie in their extensive use of the input itself as an external "memory" rather than network-internal symbolic operations involving variable binding. Therefore, we propose a novel direction for future work: augmenting the inputs available to circumvent the lack of network-internal variable binding.
Good Artists Copy, Great Artists Steal: Model Extraction Attacks Against Image Translation Generative Adversarial Networks
Apr 26, 2021


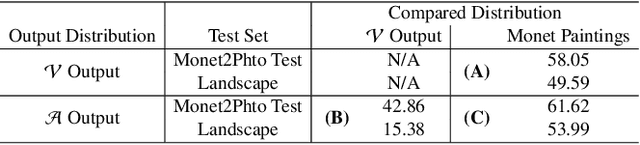
Machine learning models are typically made available to potential client users via inference APIs. Model extraction attacks occur when a malicious client uses information gleaned from queries to the inference API of a victim model $F_V$ to build a surrogate model $F_A$ that has comparable functionality. Recent research has shown successful model extraction attacks against image classification, and NLP models. In this paper, we show the first model extraction attack against real-world generative adversarial network (GAN) image translation models. We present a framework for conducting model extraction attacks against image translation models, and show that the adversary can successfully extract functional surrogate models. The adversary is not required to know $F_V$'s architecture or any other information about it beyond its intended image translation task, and queries $F_V$'s inference interface using data drawn from the same domain as the training data for $F_V$. We evaluate the effectiveness of our attacks using three different instances of two popular categories of image translation: (1) Selfie-to-Anime and (2) Monet-to-Photo (image style transfer), and (3) Super-Resolution (super resolution). Using standard performance metrics for GANs, we show that our attacks are effective in each of the three cases -- the differences between $F_V$ and $F_A$, compared to the target are in the following ranges: Selfie-to-Anime: FID $13.36-68.66$, Monet-to-Photo: FID $3.57-4.40$, and Super-Resolution: SSIM: $0.06-0.08$ and PSNR: $1.43-4.46$. Furthermore, we conducted a large scale (125 participants) user study on Selfie-to-Anime and Monet-to-Photo to show that human perception of the images produced by the victim and surrogate models can be considered equivalent, within an equivalence bound of Cohen's $d=0.3$.
A little goes a long way: Improving toxic language classification despite data scarcity
Sep 25, 2020

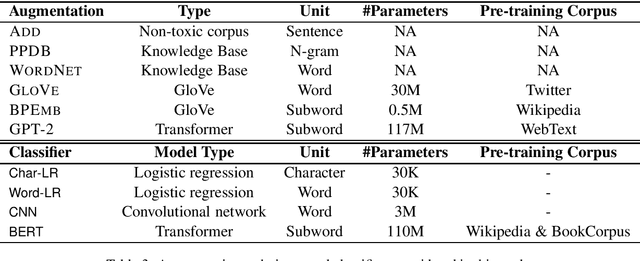
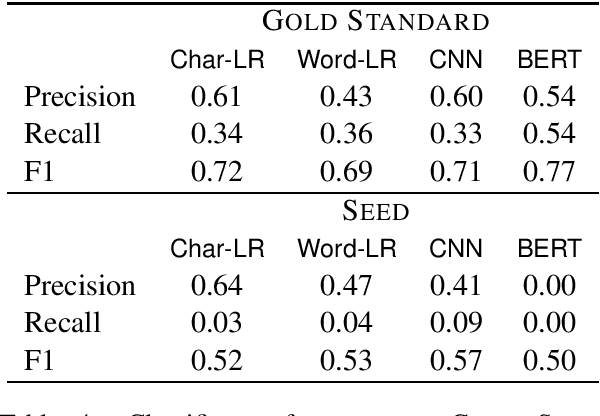
Detection of some types of toxic language is hampered by extreme scarcity of labeled training data. Data augmentation - generating new synthetic data from a labeled seed dataset - can help. The efficacy of data augmentation on toxic language classification has not been fully explored. We present the first systematic study on how data augmentation techniques impact performance across toxic language classifiers, ranging from shallow logistic regression architectures to BERT - a state-of-the-art pre-trained Transformer network. We compare the performance of eight techniques on very scarce seed datasets. We show that while BERT performed the best, shallow classifiers performed comparably when trained on data augmented with a combination of three techniques, including GPT-2-generated sentences. We discuss the interplay of performance and computational overhead, which can inform the choice of techniques under different constraints.
Effective writing style imitation via combinatorial paraphrasing
May 31, 2019
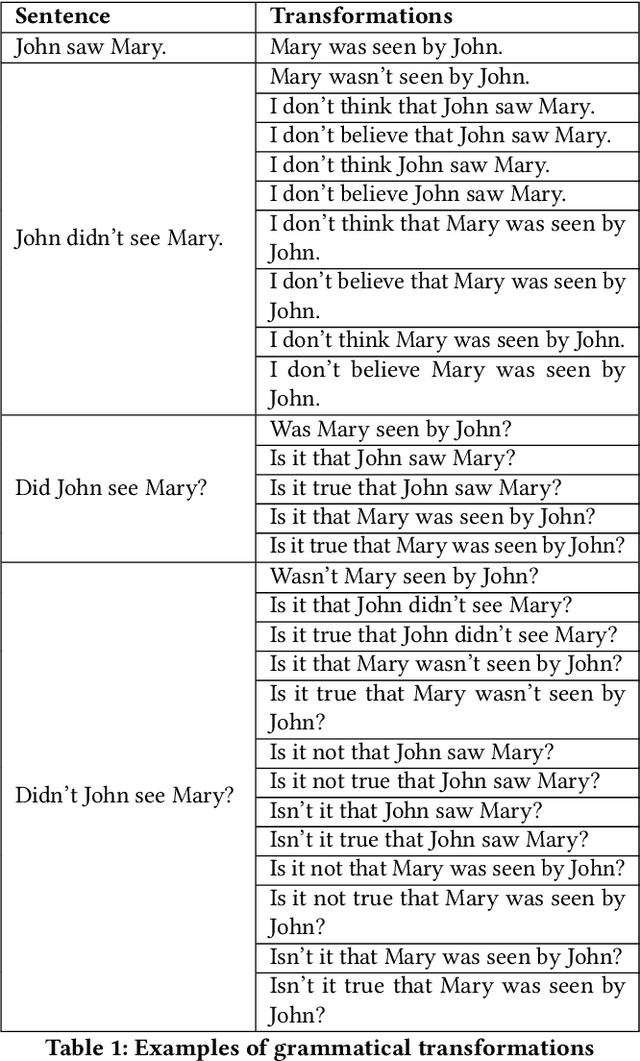
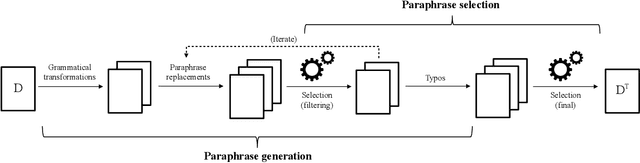

Stylometry can be used to profile authors based on their written text. Transforming text to imitate someone else's writing style while retaining meaning constitutes a defence. A variety of deep learning methods for style imitation have been proposed in recent research literature. Via empirical evaluation of three state-of-the-art models on four datasets, we illustrate that none succeed in semantic retainment, often drastically changing the original meaning or removing important parts of the text. To mitigate this problem we present ParChoice: an alternative approach based on the combinatorial application of multiple paraphrasing techniques. ParChoice first produces a large number of possible candidate paraphrases, from which it then chooses the candidate that maximizes proximity to a target corpus. Through systematic automated and manual evaluation as well as a user study, we demonstrate that ParChoice significantly outperforms prior methods in its ability to retain semantic content. Using state-of-the art deep learning author profiling tools, we additionally show that ParChoice accomplishes better imitation success than A$^4$NT, the state-of-the-art style imitation technique with the best semantic retainment.
EAT2seq: A generic framework for controlled sentence transformation without task-specific training
Apr 08, 2019
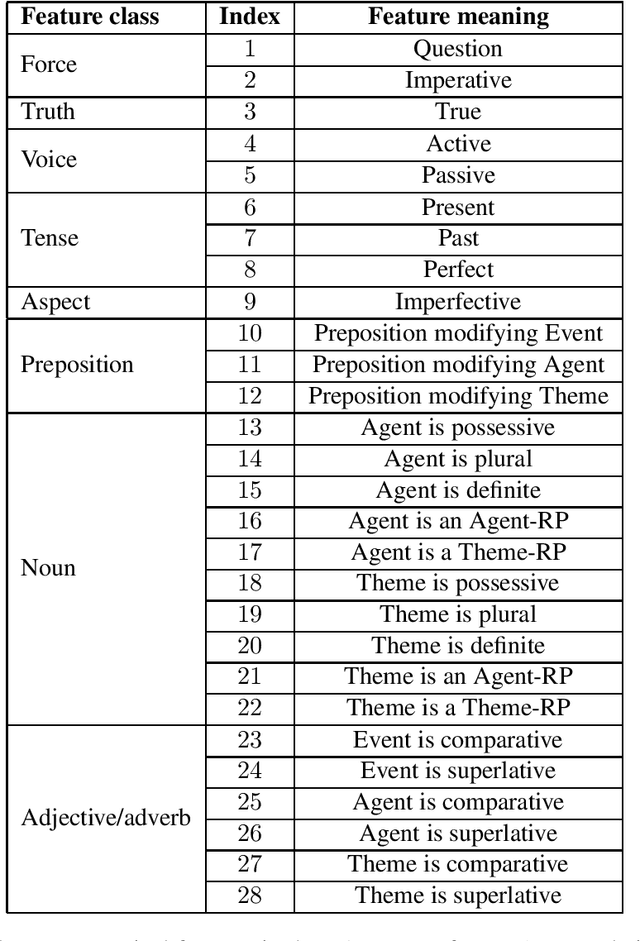
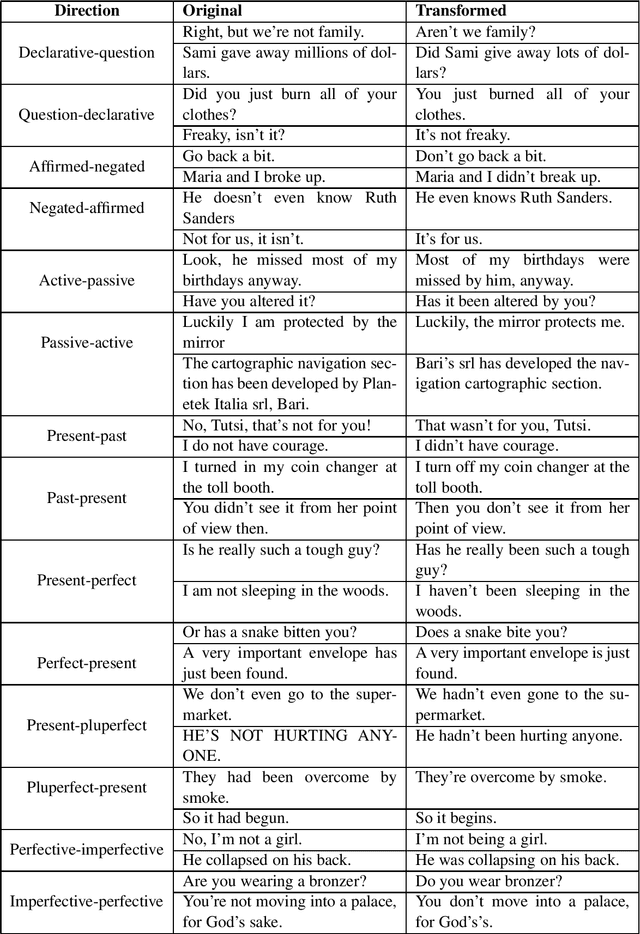
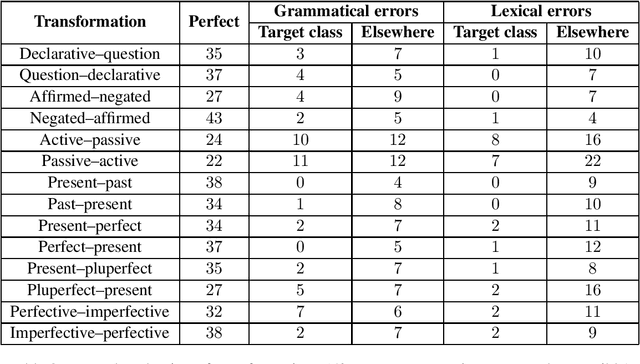
We present EAT2seq: a novel method to architect automatic linguistic transformations for a number of tasks, including controlled grammatical or lexical changes, style transfer, text generation, and machine translation. Our approach consists in creating an abstract representation of a sentence's meaning and grammar, which we use as input to an encoder-decoder network trained to reproduce the original sentence. Manipulating the abstract representation allows the transformation of sentences according to user-provided parameters, both grammatically and lexically, in any combination. The same architecture can further be used for controlled text generation, and has additional promise for machine translation. This strategy holds the promise of enabling many tasks that were hitherto outside the scope of NLP techniques for want of sufficient training data. We provide empirical evidence for the effectiveness of our approach by reproducing and transforming English sentences, and evaluating the results both manually and automatically. A single model trained on monolingual data is used for all tasks without any task-specific training. For a model trained on 8.5 million sentences, we report a BLEU score of 74.45 for reproduction, and scores between 55.29 and 81.82 for back-and-forth grammatical transformations across 14 category pairs.
Text Analysis in Adversarial Settings: Does Deception Leave a Stylistic Trace?
Feb 26, 2019

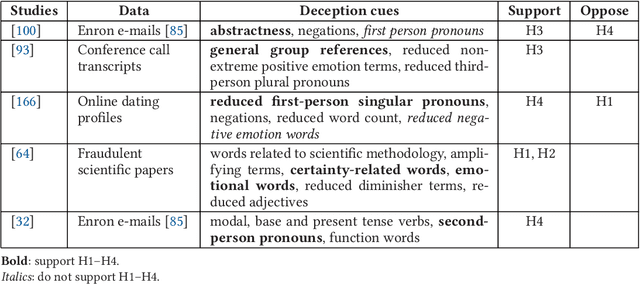

Textual deception constitutes a major problem for online security. Many studies have argued that deceptiveness leaves traces in writing style, which could be detected using text classification techniques. By conducting an extensive literature review of existing empirical work, we demonstrate that while certain linguistic features have been indicative of deception in certain corpora, they fail to generalize across divergent semantic domains. We suggest that deceptiveness as such leaves no content-invariant stylistic trace, and textual similarity measures provide superior means of classifying texts as potentially deceptive. Additionally, we discuss forms of deception beyond semantic content, focusing on hiding author identity by writing style obfuscation. Surveying the literature on both author identification and obfuscation techniques, we conclude that current style transformation methods fail to achieve reliable obfuscation while simultaneously ensuring semantic faithfulness to the original text. We propose that future work in style transformation should pay particular attention to disallowing semantically drastic changes.
All You Need is "Love": Evading Hate-speech Detection
Nov 05, 2018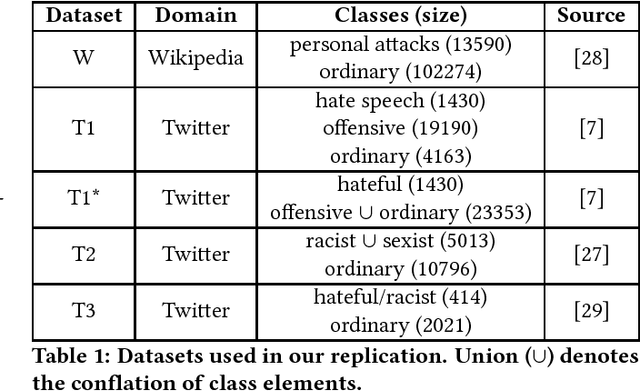

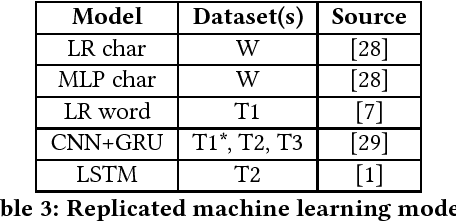

With the spread of social networks and their unfortunate use for hate speech, automatic detection of the latter has become a pressing problem. In this paper, we reproduce seven state-of-the-art hate speech detection models from prior work, and show that they perform well only when tested on the same type of data they were trained on. Based on these results, we argue that for successful hate speech detection, model architecture is less important than the type of data and labeling criteria. We further show that all proposed detection techniques are brittle against adversaries who can (automatically) insert typos, change word boundaries or add innocuous words to the original hate speech. A combination of these methods is also effective against Google Perspective -- a cutting-edge solution from industry. Our experiments demonstrate that adversarial training does not completely mitigate the attacks, and using character-level features makes the models systematically more attack-resistant than using word-level features.