 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA little goes a long way: Improving toxic language classification despite data scarcity
Sep 25, 2020

Detection of some types of toxic language is hampered by extreme scarcity of labeled training data. Data augmentation - generating new synthetic data from a labeled seed dataset - can help. The efficacy of data augmentation on toxic language classification has not been fully explored. We present the first systematic study on how data augmentation techniques impact performance across toxic language classifiers, ranging from shallow logistic regression architectures to BERT - a state-of-the-art pre-trained Transformer network. We compare the performance of eight techniques on very scarce seed datasets. We show that while BERT performed the best, shallow classifiers performed comparably when trained on data augmented with a combination of three techniques, including GPT-2-generated sentences. We discuss the interplay of performance and computational overhead, which can inform the choice of techniques under different constraints.
Extraction of Complex DNN Models: Real Threat or Boogeyman?
Oct 11, 2019

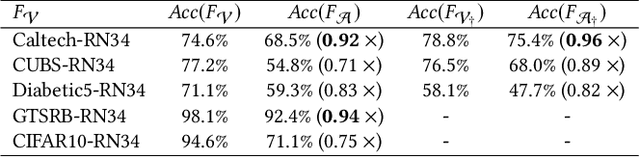
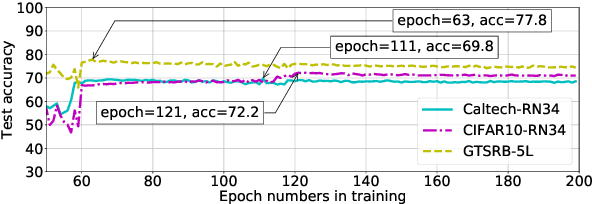
Recently, machine learning (ML) has introduced advanced solutions to many domains. Since ML models provide business advantage to model owners, protecting intellectual property (IP) of ML models has emerged as an important consideration. Confidentiality of ML models can be protected by exposing them to clients only via prediction APIs. However, model extraction attacks can steal the functionality of ML models using the information leaked to clients through the results returned via the API. In this work, we question whether model extraction is a serious threat to complex, real-life ML models. We evaluate the current state-of-the-art model extraction attack (the Knockoff attack) against complex models. We reproduced and confirm the results in the Knockoff attack paper. But we also show that the performance of this attack can be limited by several factors, including ML model architecture and the granularity of API response. Furthermore, we introduce a defense based on distinguishing queries used for Knockoff attack from benign queries. Despite the limitations of the Knockoff attack, we show that a more realistic adversary can effectively steal complex ML models and evade known defenses.
Making targeted black-box evasion attacks effective and efficient
Jun 08, 2019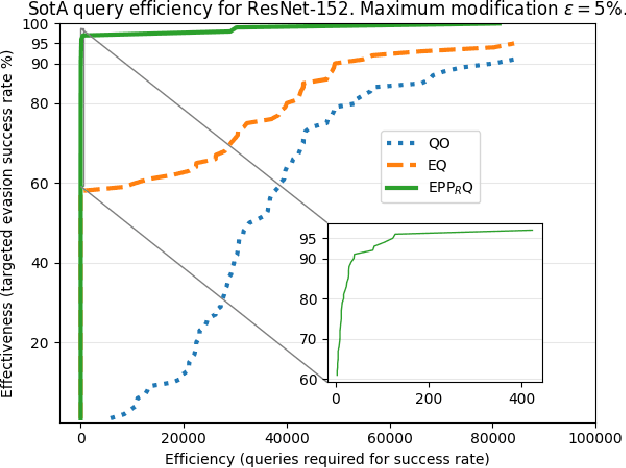


We investigate how an adversary can optimally use its query budget for targeted evasion attacks against deep neural networks in a black-box setting. We formalize the problem setting and systematically evaluate what benefits the adversary can gain by using substitute models. We show that there is an exploration-exploitation tradeoff in that query efficiency comes at the cost of effectiveness. We present two new attack strategies for using substitute models and show that they are as effective as previous query-only techniques but require significantly fewer queries, by up to three orders of magnitude. We also show that an agile adversary capable of switching through different attack techniques can achieve pareto-optimal efficiency. We demonstrate our attack against Google Cloud Vision showing that the difficulty of black-box attacks against real-world prediction APIs is significantly easier than previously thought (requiring approximately 500 queries instead of approximately 20,000 as in previous works).
All You Need is "Love": Evading Hate-speech Detection
Nov 05, 2018

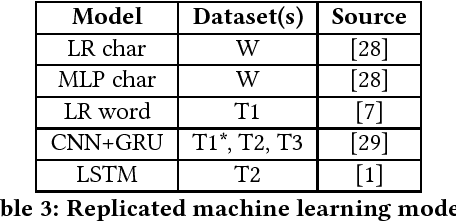

With the spread of social networks and their unfortunate use for hate speech, automatic detection of the latter has become a pressing problem. In this paper, we reproduce seven state-of-the-art hate speech detection models from prior work, and show that they perform well only when tested on the same type of data they were trained on. Based on these results, we argue that for successful hate speech detection, model architecture is less important than the type of data and labeling criteria. We further show that all proposed detection techniques are brittle against adversaries who can (automatically) insert typos, change word boundaries or add innocuous words to the original hate speech. A combination of these methods is also effective against Google Perspective -- a cutting-edge solution from industry. Our experiments demonstrate that adversarial training does not completely mitigate the attacks, and using character-level features makes the models systematically more attack-resistant than using word-level features.
Stay On-Topic: Generating Context-specific Fake Restaurant Reviews
Jun 28, 2018

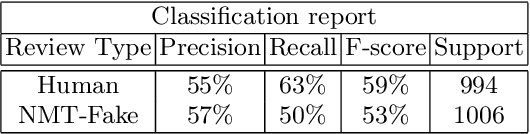
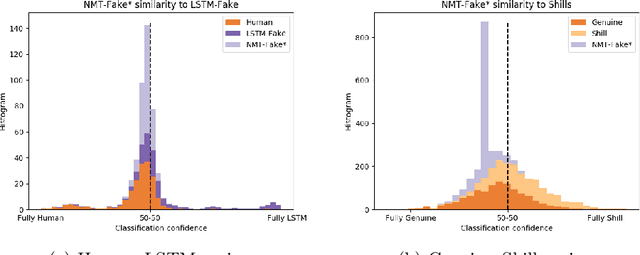
Automatically generated fake restaurant reviews are a threat to online review systems. Recent research has shown that users have difficulties in detecting machine-generated fake reviews hiding among real restaurant reviews. The method used in this work (char-LSTM ) has one drawback: it has difficulties staying in context, i.e. when it generates a review for specific target entity, the resulting review may contain phrases that are unrelated to the target, thus increasing its detectability. In this work, we present and evaluate a more sophisticated technique based on neural machine translation (NMT) with which we can generate reviews that stay on-topic. We test multiple variants of our technique using native English speakers on Amazon Mechanical Turk. We demonstrate that reviews generated by the best variant have almost optimal undetectability (class-averaged F-score 47%). We conduct a user study with skeptical users and show that our method evades detection more frequently compared to the state-of-the-art (average evasion 3.2/4 vs 1.5/4) with statistical significance, at level {\alpha} = 1% (Section 4.3). We develop very effective detection tools and reach average F-score of 97% in classifying these. Although fake reviews are very effective in fooling people, effective automatic detection is still feasible.