 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Structural Knowledge in Multimodal-BERT
Mar 17, 2022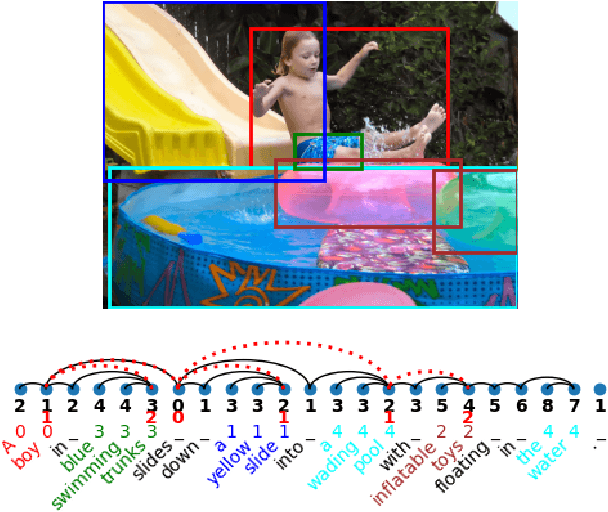
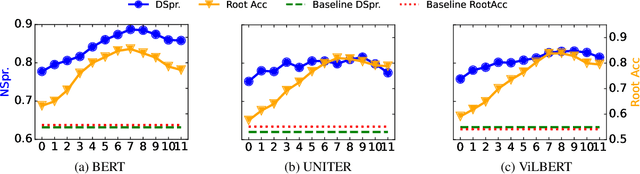
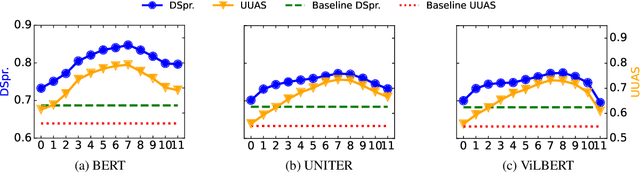
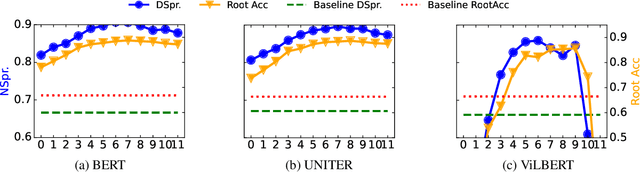
In this work, we investigate the knowledge learned in the embeddings of multimodal-BERT models. More specifically, we probe their capabilities of storing the grammatical structure of linguistic data and the structure learned over objects in visual data. To reach that goal, we first make the inherent structure of language and visuals explicit by a dependency parse of the sentences that describe the image and by the dependencies between the object regions in the image, respectively. We call this explicit visual structure the \textit{scene tree}, that is based on the dependency tree of the language description. Extensive probing experiments show that the multimodal-BERT models do not encode these scene trees.Code available at \url{https://github.com/VSJMilewski/multimodal-probes}.
Giving Commands to a Self-Driving Car: How to Deal with Uncertain Situations?
Jun 08, 2021
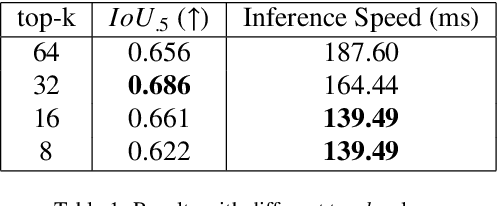
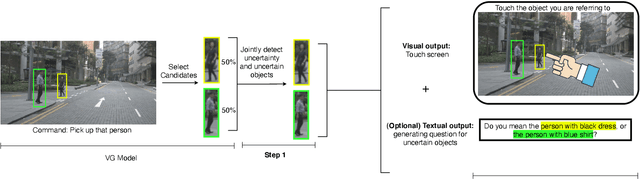
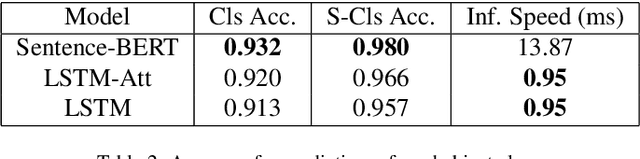
Current technology for autonomous cars primarily focuses on getting the passenger from point A to B. Nevertheless, it has been shown that passengers are afraid of taking a ride in self-driving cars. One way to alleviate this problem is by allowing the passenger to give natural language commands to the car. However, the car can misunderstand the issued command or the visual surroundings which could lead to uncertain situations. It is desirable that the self-driving car detects these situations and interacts with the passenger to solve them. This paper proposes a model that detects uncertain situations when a command is given and finds the visual objects causing it. Optionally, a question generated by the system describing the uncertain objects is included. We argue that if the car could explain the objects in a human-like way, passengers could gain more confidence in the car's abilities. Thus, we investigate how to (1) detect uncertain situations and their underlying causes, and (2) how to generate clarifying questions for the passenger. When evaluating on the Talk2Car dataset, we show that the proposed model, \acrfull{pipeline}, improves \gls{m:ambiguous-absolute-increase} in terms of $IoU_{.5}$ compared to not using \gls{pipeline}. Furthermore, we designed a referring expression generator (REG) \acrfull{reg_model} tailored to a self-driving car setting which yields a relative improvement of \gls{m:meteor-relative} METEOR and \gls{m:rouge-relative} ROUGE-l compared with state-of-the-art REG models, and is three times faster.
Are scene graphs good enough to improve Image Captioning?
Sep 25, 2020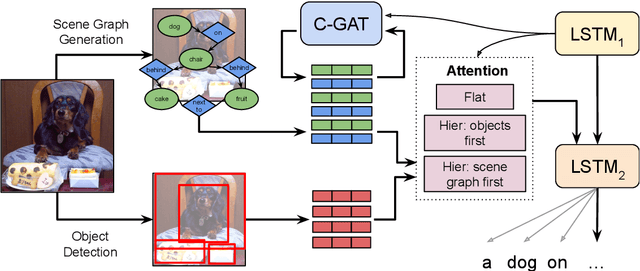
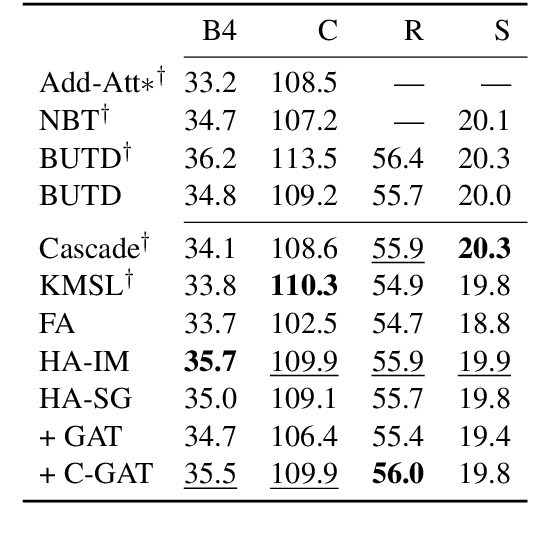
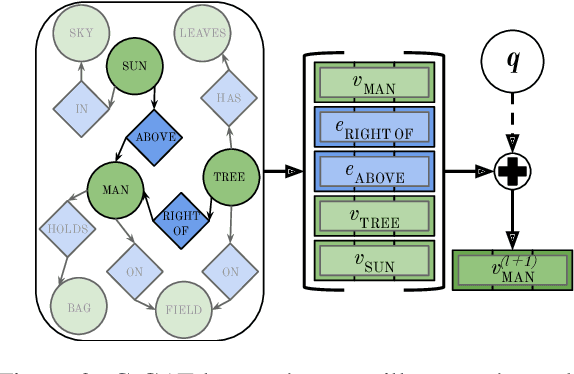
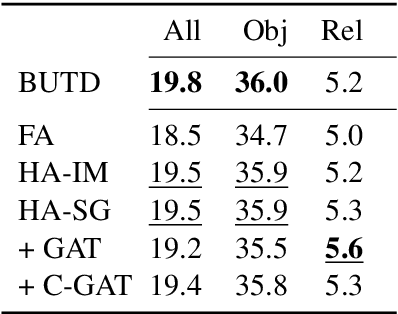
Many top-performing image captioning models rely solely on object features computed with an object detection model to generate image descriptions. However, recent studies propose to directly use scene graphs to introduce information about object relations into captioning, hoping to better describe interactions between objects. In this work, we thoroughly investigate the use of scene graphs in image captioning. We empirically study whether using additional scene graph encoders can lead to better image descriptions and propose a conditional graph attention network (C-GAT), where the image captioning decoder state is used to condition the graph updates. Finally, we determine to what extent noise in the predicted scene graphs influence caption quality. Overall, we find no significant difference between models that use scene graph features and models that only use object detection features across different captioning metrics, which suggests that existing scene graph generation models are still too noisy to be useful in image captioning. Moreover, although the quality of predicted scene graphs is very low in general, when using high quality scene graphs we obtain gains of up to 3.3 CIDEr compared to a strong Bottom-Up Top-Down baseline.