 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Physical World Destinations for Commands Given to Self-Driving Cars
Paper and Code
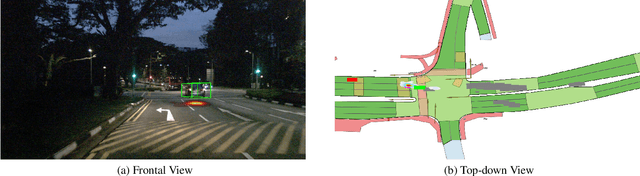
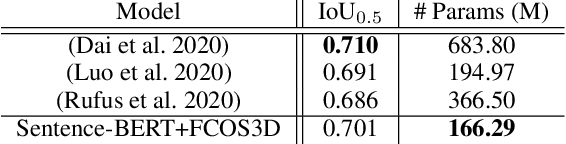

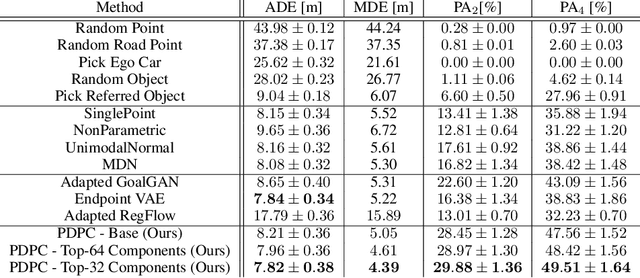
In recent years, we have seen significant steps taken in the development of self-driving cars. Multiple companies are starting to roll out impressive systems that work in a variety of settings. These systems can sometimes give the impression that full self-driving is just around the corner and that we would soon build cars without even a steering wheel. The increase in the level of autonomy and control given to an AI provides an opportunity for new modes of human-vehicle interaction. However, surveys have shown that giving more control to an AI in self-driving cars is accompanied by a degree of uneasiness by passengers. In an attempt to alleviate this issue, recent works have taken a natural language-oriented approach by allowing the passenger to give commands that refer to specific objects in the visual scene. Nevertheless, this is only half the task as the car should also understand the physical destination of the command, which is what we focus on in this paper. We propose an extension in which we annotate the 3D destination that the car needs to reach after executing the given command and evaluate multiple different baselines on predicting this destination location. Additionally, we introduce a model that outperforms the prior works adapted for this particular setting.