 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadar Fields: Frequency-Space Neural Scene Representations for FMCW Radar
May 07, 2024Neural fields have been broadly investigated as scene representations for the reproduction and novel generation of diverse outdoor scenes, including those autonomous vehicles and robots must handle. While successful approaches for RGB and LiDAR data exist, neural reconstruction methods for radar as a sensing modality have been largely unexplored. Operating at millimeter wavelengths, radar sensors are robust to scattering in fog and rain, and, as such, offer a complementary modality to active and passive optical sensing techniques. Moreover, existing radar sensors are highly cost-effective and deployed broadly in robots and vehicles that operate outdoors. We introduce Radar Fields - a neural scene reconstruction method designed for active radar imagers. Our approach unites an explicit, physics-informed sensor model with an implicit neural geometry and reflectance model to directly synthesize raw radar measurements and extract scene occupancy. The proposed method does not rely on volume rendering. Instead, we learn fields in Fourier frequency space, supervised with raw radar data. We validate the effectiveness of the method across diverse outdoor scenarios, including urban scenes with dense vehicles and infrastructure, and in harsh weather scenarios, where mm-wavelength sensing is especially favorable.
MUSES: The Multi-Sensor Semantic Perception Dataset for Driving under Uncertainty
Jan 23, 2024



Achieving level-5 driving automation in autonomous vehicles necessitates a robust semantic visual perception system capable of parsing data from different sensors across diverse conditions. However, existing semantic perception datasets often lack important non-camera modalities typically used in autonomous vehicles, or they do not exploit such modalities to aid and improve semantic annotations in challenging conditions. To address this, we introduce MUSES, the MUlti-SEnsor Semantic perception dataset for driving in adverse conditions under increased uncertainty. MUSES includes synchronized multimodal recordings with 2D panoptic annotations for 2500 images captured under diverse weather and illumination. The dataset integrates a frame camera, a lidar, a radar, an event camera, and an IMU/GNSS sensor. Our new two-stage panoptic annotation protocol captures both class-level and instance-level uncertainty in the ground truth and enables the novel task of uncertainty-aware panoptic segmentation we introduce, along with standard semantic and panoptic segmentation. MUSES proves both effective for training and challenging for evaluating models under diverse visual conditions, and it opens new avenues for research in multimodal and uncertainty-aware dense semantic perception. Our dataset and benchmark will be made publicly available.
Condition-Invariant Semantic Segmentation
May 27, 2023



Adaptation of semantic segmentation networks to different visual conditions from those for which ground-truth annotations are available at training is vital for robust perception in autonomous cars and robots. However, previous work has shown that most feature-level adaptation methods, which employ adversarial training and are validated on synthetic-to-real adaptation, provide marginal gains in normal-to-adverse condition-level adaptation, being outperformed by simple pixel-level adaptation via stylization. Motivated by these findings, we propose to leverage stylization in performing feature-level adaptation by aligning the deep features extracted by the encoder of the network from the original and the stylized view of each input image with a novel feature invariance loss. In this way, we encourage the encoder to extract features that are invariant to the style of the input, allowing the decoder to focus on parsing these features and not on further abstracting from the specific style of the input. We implement our method, named Condition-Invariant Semantic Segmentation (CISS), on the top-performing domain adaptation architecture and demonstrate a significant improvement over previous state-of-the-art methods both on Cityscapes$\to$ACDC and Cityscapes$\to$Dark Zurich adaptation. In particular, CISS is ranked first among all published unsupervised domain adaptation methods on the public ACDC leaderboard. Our method is also shown to generalize well to domains unseen during training, outperforming competing domain adaptation approaches on BDD100K-night and Nighttime Driving. Code is publicly available at https://github.com/SysCV/CISS .
Contrastive Model Adaptation for Cross-Condition Robustness in Semantic Segmentation
Mar 09, 2023



Standard unsupervised domain adaptation methods adapt models from a source to a target domain using labeled source data and unlabeled target data jointly. In model adaptation, on the other hand, access to the labeled source data is prohibited, i.e., only the source-trained model and unlabeled target data are available. We investigate normal-to-adverse condition model adaptation for semantic segmentation, whereby image-level correspondences are available in the target domain. The target set consists of unlabeled pairs of adverse- and normal-condition street images taken at GPS-matched locations. Our method -- CMA -- leverages such image pairs to learn condition-invariant features via contrastive learning. In particular, CMA encourages features in the embedding space to be grouped according to their condition-invariant semantic content and not according to the condition under which respective inputs are captured. To obtain accurate cross-domain semantic correspondences, we warp the normal image to the viewpoint of the adverse image and leverage warp-confidence scores to create robust, aggregated features. With this approach, we achieve state-of-the-art semantic segmentation performance for model adaptation on several normal-to-adverse adaptation benchmarks, such as ACDC and Dark Zurich. We also evaluate CMA on a newly procured adverse-condition generalization benchmark and report favorable results compared to standard unsupervised domain adaptation methods, despite the comparative handicap of CMA due to source data inaccessibility. Code is available at https://github.com/brdav/cma.
Composite Learning for Robust and Effective Dense Predictions
Oct 13, 2022
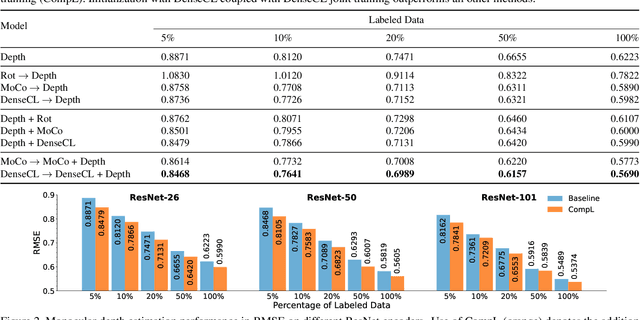
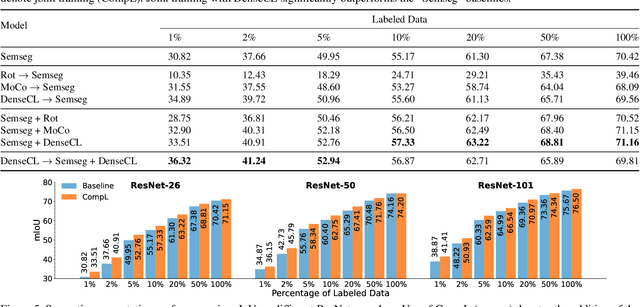
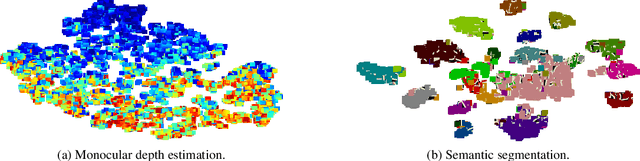
Multi-task learning promises better model generalization on a target task by jointly optimizing it with an auxiliary task. However, the current practice requires additional labeling efforts for the auxiliary task, while not guaranteeing better model performance. In this paper, we find that jointly training a dense prediction (target) task with a self-supervised (auxiliary) task can consistently improve the performance of the target task, while eliminating the need for labeling auxiliary tasks. We refer to this joint training as Composite Learning (CompL). Experiments of CompL on monocular depth estimation, semantic segmentation, and boundary detection show consistent performance improvements in fully and partially labeled datasets. Further analysis on depth estimation reveals that joint training with self-supervision outperforms most labeled auxiliary tasks. We also find that CompL can improve model robustness when the models are evaluated in new domains. These results demonstrate the benefits of self-supervision as an auxiliary task, and establish the design of novel task-specific self-supervised methods as a new axis of investigation for future multi-task learning research.
Refign: Align and Refine for Adaptation of Semantic Segmentation to Adverse Conditions
Jul 14, 2022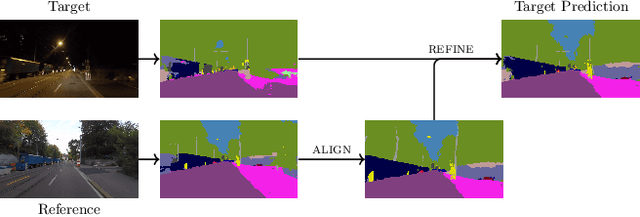

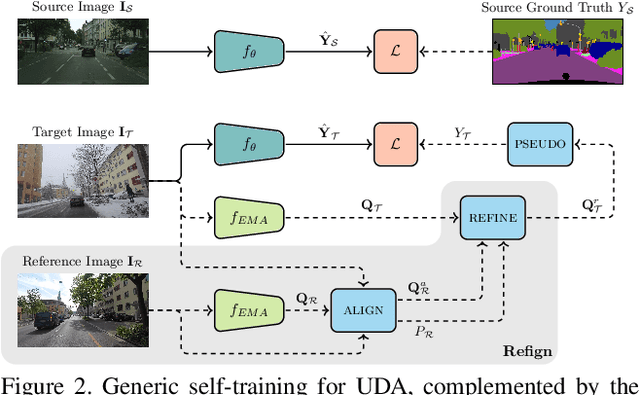
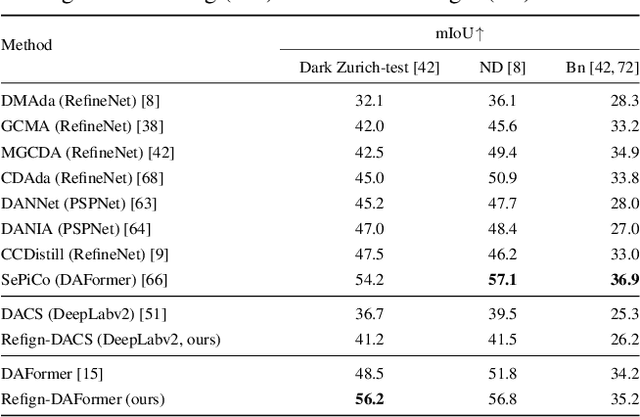
Due to the scarcity of dense pixel-level semantic annotations for images recorded in adverse visual conditions, there has been a keen interest in unsupervised domain adaptation (UDA) for the semantic segmentation of such images. UDA adapts models trained on normal conditions to the target adverse-condition domains. Meanwhile, multiple datasets with driving scenes provide corresponding images of the same scenes across multiple conditions, which can serve as a form of weak supervision for domain adaptation. We propose Refign, a generic extension to self-training-based UDA methods which leverages these cross-domain correspondences. Refign consists of two steps: (1) aligning the normal-condition image to the corresponding adverse-condition image using an uncertainty-aware dense matching network, and (2) refining the adverse prediction with the normal prediction using an adaptive label correction mechanism. We design custom modules to streamline both steps and set the new state of the art for domain-adaptive semantic segmentation on several adverse-condition benchmarks, including ACDC and Dark Zurich. The approach introduces no extra training parameters, minimal computational overhead -- during training only -- and can be used as a drop-in extension to improve any given self-training-based UDA method. Code is available at https://github.com/brdav/refign.
Lasers to Events: Automatic Extrinsic Calibration of Lidars and Event Cameras
Jul 03, 2022



Despite significant academic and corporate efforts, autonomous driving under adverse visual conditions still proves challenging. As neuromorphic technology has matured, its application to robotics and autonomous vehicle systems has become an area of active research. Low-light and latency-demanding situations can benefit. To enable event cameras to operate alongside staple sensors like lidar in perception tasks, we propose a direct, temporally-decoupled calibration method between event cameras and lidars. The high dynamic range and low-light operation of event cameras are exploited to directly register lidar laser returns, allowing information-based correlation methods to optimize for the 6-DoF extrinsic calibration between the two sensors. This paper presents the first direct calibration method between event cameras and lidars, removing dependencies on frame-based camera intermediaries and/or highly-accurate hand measurements. Code will be made publicly available.
Exploring Relational Context for Multi-Task Dense Prediction
Apr 28, 2021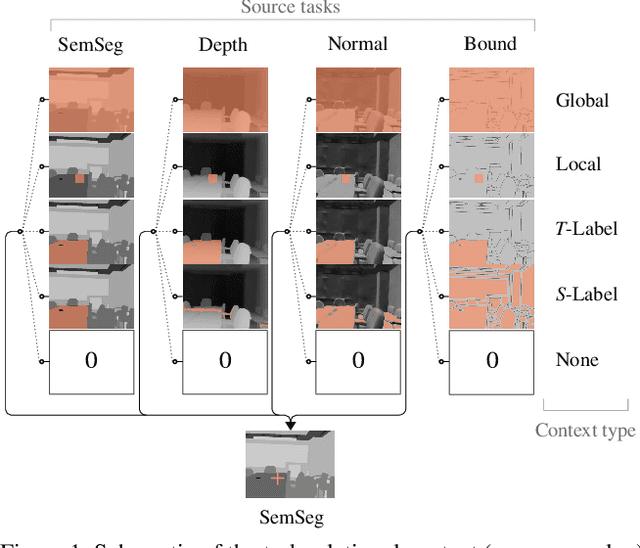
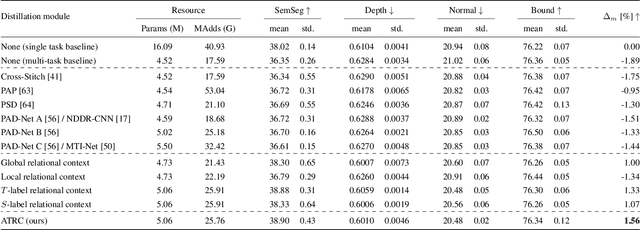
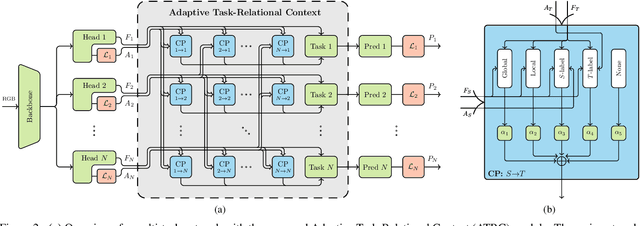
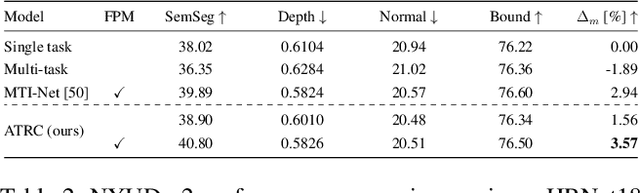
The timeline of computer vision research is marked with advances in learning and utilizing efficient contextual representations. Most of them, however, are targeted at improving model performance on a single downstream task. We consider a multi-task environment for dense prediction tasks, represented by a common backbone and independent task-specific heads. Our goal is to find the most efficient way to refine each task prediction by capturing cross-task contexts dependent on tasks' relations. We explore various attention-based contexts, such as global and local, in the multi-task setting and analyze their behavior when applied to refine each task independently. Empirical findings confirm that different source-target task pairs benefit from different context types. To automate the selection process, we propose an Adaptive Task-Relational Context (ATRC) module, which samples the pool of all available contexts for each task pair using neural architecture search and outputs the optimal configuration for deployment. Our method achieves state-of-the-art performance on two important multi-task benchmarks, namely NYUD-v2 and PASCAL-Context. The proposed ATRC has a low computational toll and can be used as a drop-in refinement module for any supervised multi-task architecture.
Automated Search for Resource-Efficient Branched Multi-Task Networks
Aug 24, 2020
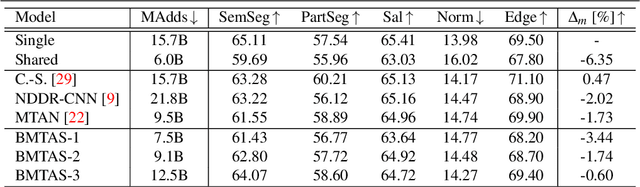

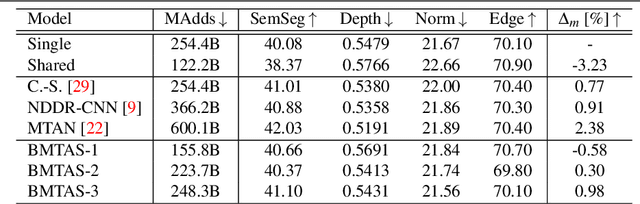
The multi-modal nature of many vision problems calls for neural network architectures that can perform multiple tasks concurrently. Typically, such architectures have been handcrafted in the literature. However, given the size and complexity of the problem, this manual architecture exploration likely exceeds human design abilities. In this paper, we propose a principled approach, rooted in differentiable neural architecture search, to automatically define branching (tree-like) structures in the encoding stage of a multi-task neural network. To allow flexibility within resource-constrained environments, we introduce a proxyless, resource-aware loss that dynamically controls the model size. Evaluations across a variety of dense prediction tasks show that our approach consistently finds high-performing branching structures within limited resource budgets.
Reparameterizing Convolutions for Incremental Multi-Task Learning without Task Interference
Jul 24, 2020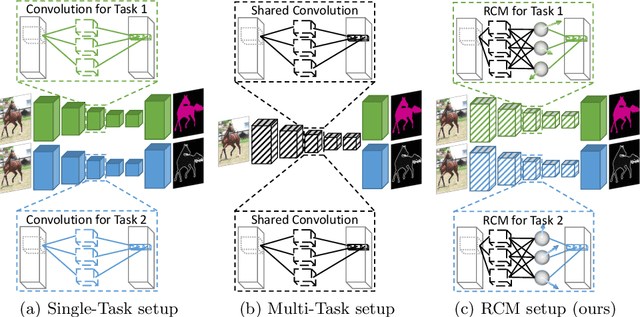

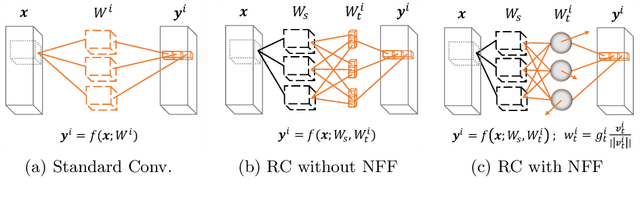
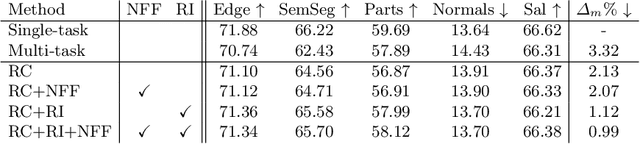
Multi-task networks are commonly utilized to alleviate the need for a large number of highly specialized single-task networks. However, two common challenges in developing multi-task models are often overlooked in literature. First, enabling the model to be inherently incremental, continuously incorporating information from new tasks without forgetting the previously learned ones (incremental learning). Second, eliminating adverse interactions amongst tasks, which has been shown to significantly degrade the single-task performance in a multi-task setup (task interference). In this paper, we show that both can be achieved simply by reparameterizing the convolutions of standard neural network architectures into a non-trainable shared part (filter bank) and task-specific parts (modulators), where each modulator has a fraction of the filter bank parameters. Thus, our reparameterization enables the model to learn new tasks without adversely affecting the performance of existing ones. The results of our ablation study attest the efficacy of the proposed reparameterization. Moreover, our method achieves state-of-the-art on two challenging multi-task learning benchmarks, PASCAL-Context and NYUD, and also demonstrates superior incremental learning capability as compared to its close competitors.