 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic3D: Controllable Stereo Video Conversion with Guided Latent Decoding
Dec 16, 2025The growing demand for immersive 3D content calls for automated monocular-to-stereo video conversion. We present Elastic3D, a controllable, direct end-to-end method for upgrading a conventional video to a binocular one. Our approach, based on (conditional) latent diffusion, avoids artifacts due to explicit depth estimation and warping. The key to its high-quality stereo video output is a novel, guided VAE decoder that ensures sharp and epipolar-consistent stereo video output. Moreover, our method gives the user control over the strength of the stereo effect (more precisely, the disparity range) at inference time, via an intuitive, scalar tuning knob. Experiments on three different datasets of real-world stereo videos show that our method outperforms both traditional warping-based and recent warping-free baselines and sets a new standard for reliable, controllable stereo video conversion. Please check the project page for the video samples https://elastic3d.github.io.
AnyUp: Universal Feature Upsampling
Oct 14, 2025
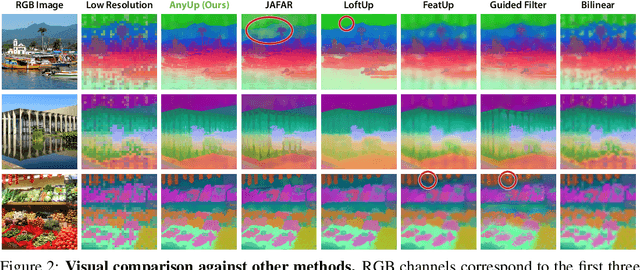

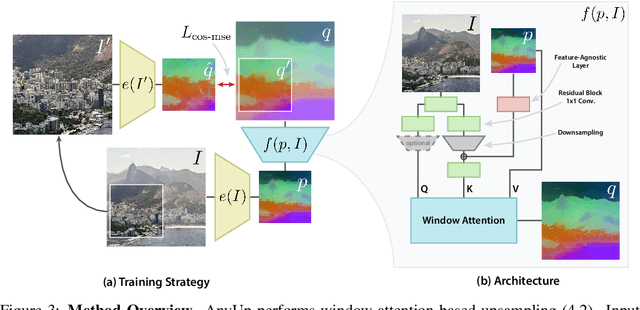
We introduce AnyUp, a method for feature upsampling that can be applied to any vision feature at any resolution, without encoder-specific training. Existing learning-based upsamplers for features like DINO or CLIP need to be re-trained for every feature extractor and thus do not generalize to different feature types at inference time. In this work, we propose an inference-time feature-agnostic upsampling architecture to alleviate this limitation and improve upsampling quality. In our experiments, AnyUp sets a new state of the art for upsampled features, generalizes to different feature types, and preserves feature semantics while being efficient and easy to apply to a wide range of downstream tasks.
M2SVid: End-to-End Inpainting and Refinement for Monocular-to-Stereo Video Conversion
May 22, 2025We tackle the problem of monocular-to-stereo video conversion and propose a novel architecture for inpainting and refinement of the warped right view obtained by depth-based reprojection of the input left view. We extend the Stable Video Diffusion (SVD) model to utilize the input left video, the warped right video, and the disocclusion masks as conditioning input to generate a high-quality right camera view. In order to effectively exploit information from neighboring frames for inpainting, we modify the attention layers in SVD to compute full attention for discoccluded pixels. Our model is trained to generate the right view video in an end-to-end manner by minimizing image space losses to ensure high-quality generation. Our approach outperforms previous state-of-the-art methods, obtaining an average rank of 1.43 among the 4 compared methods in a user study, while being 6x faster than the second placed method.
One2Any: One-Reference 6D Pose Estimation for Any Object
May 07, 20256D object pose estimation remains challenging for many applications due to dependencies on complete 3D models, multi-view images, or training limited to specific object categories. These requirements make generalization to novel objects difficult for which neither 3D models nor multi-view images may be available. To address this, we propose a novel method One2Any that estimates the relative 6-degrees of freedom (DOF) object pose using only a single reference-single query RGB-D image, without prior knowledge of its 3D model, multi-view data, or category constraints. We treat object pose estimation as an encoding-decoding process, first, we obtain a comprehensive Reference Object Pose Embedding (ROPE) that encodes an object shape, orientation, and texture from a single reference view. Using this embedding, a U-Net-based pose decoding module produces Reference Object Coordinate (ROC) for new views, enabling fast and accurate pose estimation. This simple encoding-decoding framework allows our model to be trained on any pair-wise pose data, enabling large-scale training and demonstrating great scalability. Experiments on multiple benchmark datasets demonstrate that our model generalizes well to novel objects, achieving state-of-the-art accuracy and robustness even rivaling methods that require multi-view or CAD inputs, at a fraction of compute.
* accepted by CVPR 2025
SPARF: Neural Radiance Fields from Sparse and Noisy Poses
Nov 21, 2022



Neural Radiance Field (NeRF) has recently emerged as a powerful representation to synthesize photorealistic novel views. While showing impressive performance, it relies on the availability of dense input views with highly accurate camera poses, thus limiting its application in real-world scenarios. In this work, we introduce Sparse Pose Adjusting Radiance Field (SPARF), to address the challenge of novel-view synthesis given only few wide-baseline input images (as low as 3) with noisy camera poses. Our approach exploits multi-view geometry constraints in order to jointly learn the NeRF and refine the camera poses. By relying on pixel matches extracted between the input views, our multi-view correspondence objective enforces the optimized scene and camera poses to converge to a global and geometrically accurate solution. Our depth consistency loss further encourages the reconstructed scene to be consistent from any viewpoint. Our approach sets a new state of the art in the sparse-view regime on multiple challenging datasets.
Refign: Align and Refine for Adaptation of Semantic Segmentation to Adverse Conditions
Jul 14, 2022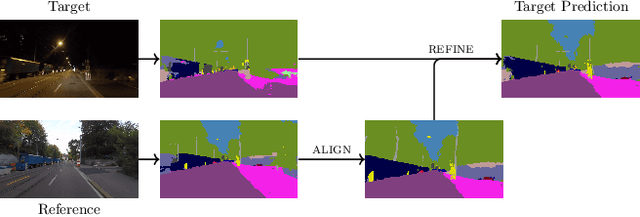

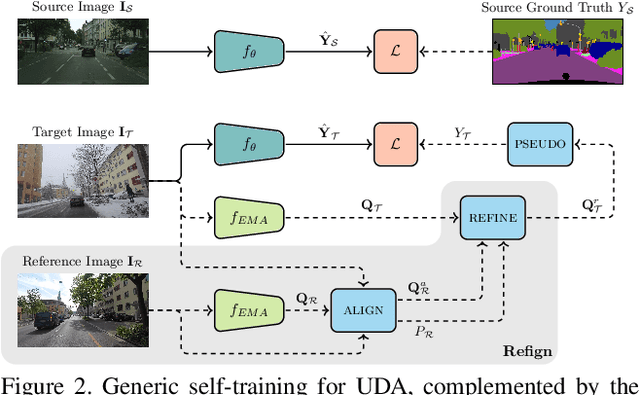
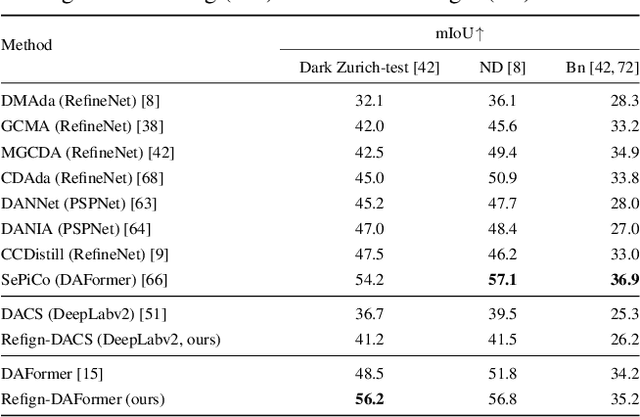
Due to the scarcity of dense pixel-level semantic annotations for images recorded in adverse visual conditions, there has been a keen interest in unsupervised domain adaptation (UDA) for the semantic segmentation of such images. UDA adapts models trained on normal conditions to the target adverse-condition domains. Meanwhile, multiple datasets with driving scenes provide corresponding images of the same scenes across multiple conditions, which can serve as a form of weak supervision for domain adaptation. We propose Refign, a generic extension to self-training-based UDA methods which leverages these cross-domain correspondences. Refign consists of two steps: (1) aligning the normal-condition image to the corresponding adverse-condition image using an uncertainty-aware dense matching network, and (2) refining the adverse prediction with the normal prediction using an adaptive label correction mechanism. We design custom modules to streamline both steps and set the new state of the art for domain-adaptive semantic segmentation on several adverse-condition benchmarks, including ACDC and Dark Zurich. The approach introduces no extra training parameters, minimal computational overhead -- during training only -- and can be used as a drop-in extension to improve any given self-training-based UDA method. Code is available at https://github.com/brdav/refign.
Probabilistic Warp Consistency for Weakly-Supervised Semantic Correspondences
Mar 08, 2022



We propose Probabilistic Warp Consistency, a weakly-supervised learning objective for semantic matching. Our approach directly supervises the dense matching scores predicted by the network, encoded as a conditional probability distribution. We first construct an image triplet by applying a known warp to one of the images in a pair depicting different instances of the same object class. Our probabilistic learning objectives are then derived using the constraints arising from the resulting image triplet. We further account for occlusion and background clutter present in real image pairs by extending our probabilistic output space with a learnable unmatched state. To supervise it, we design an objective between image pairs depicting different object classes. We validate our method by applying it to four recent semantic matching architectures. Our weakly-supervised approach sets a new state-of-the-art on four challenging semantic matching benchmarks. Lastly, we demonstrate that our objective also brings substantial improvements in the strongly-supervised regime, when combined with keypoint annotations.
* Accepted at CVPR 2022 code: https://github.com/PruneTruong/DenseMatching
PDC-Net+: Enhanced Probabilistic Dense Correspondence Network
Sep 29, 2021
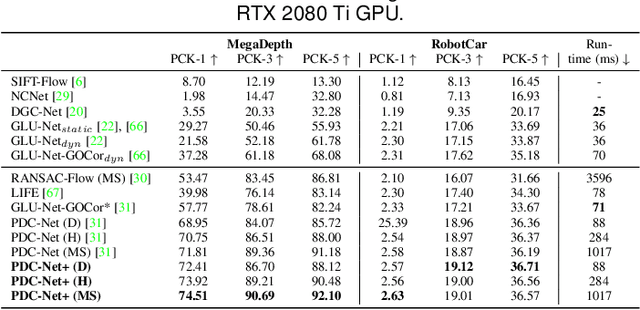
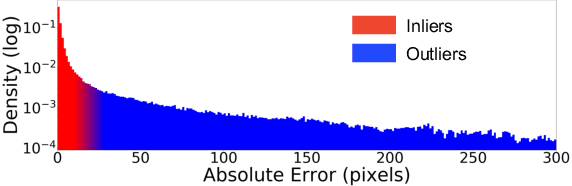

Establishing robust and accurate correspondences between a pair of images is a long-standing computer vision problem with numerous applications. While classically dominated by sparse methods, emerging dense approaches offer a compelling alternative paradigm that avoids the keypoint detection step. However, dense flow estimation is often inaccurate in the case of large displacements, occlusions, or homogeneous regions. In order to apply dense methods to real-world applications, such as pose estimation, image manipulation, or 3D reconstruction, it is therefore crucial to estimate the confidence of the predicted matches. We propose the Enhanced Probabilistic Dense Correspondence Network, PDC-Net+, capable of estimating accurate dense correspondences along with a reliable confidence map. We develop a flexible probabilistic approach that jointly learns the flow prediction and its uncertainty. In particular, we parametrize the predictive distribution as a constrained mixture model, ensuring better modelling of both accurate flow predictions and outliers. Moreover, we develop an architecture and an enhanced training strategy tailored for robust and generalizable uncertainty prediction in the context of self-supervised training. Our approach obtains state-of-the-art results on multiple challenging geometric matching and optical flow datasets. We further validate the usefulness of our probabilistic confidence estimation for the tasks of pose estimation, 3D reconstruction, image-based localization, and image retrieval. Code and models are available at https://github.com/PruneTruong/DenseMatching.
Warp Consistency for Unsupervised Learning of Dense Correspondences
Apr 08, 2021



The key challenge in learning dense correspondences lies in the lack of ground-truth matches for real image pairs. While photometric consistency losses provide unsupervised alternatives, they struggle with large appearance changes, which are ubiquitous in geometric and semantic matching tasks. Moreover, methods relying on synthetic training pairs often suffer from poor generalisation to real data. We propose Warp Consistency, an unsupervised learning objective for dense correspondence regression. Our objective is effective even in settings with large appearance and view-point changes. Given a pair of real images, we first construct an image triplet by applying a randomly sampled warp to one of the original images. We derive and analyze all flow-consistency constraints arising between the triplet. From our observations and empirical results, we design a general unsupervised objective employing two of the derived constraints. We validate our warp consistency loss by training three recent dense correspondence networks for the geometric and semantic matching tasks. Our approach sets a new state-of-the-art on several challenging benchmarks, including MegaDepth, RobotCar and TSS. Code and models will be released at https://github.com/PruneTruong/DenseMatching.
Learning Accurate Dense Correspondences and When to Trust Them
Jan 05, 2021
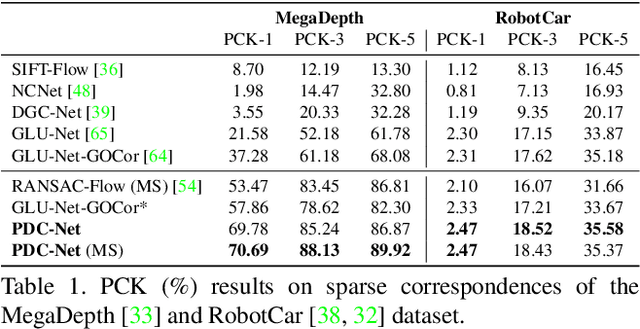


Establishing dense correspondences between a pair of images is an important and general problem. However, dense flow estimation is often inaccurate in the case of large displacements or homogeneous regions. For most applications and down-steam tasks, such as pose estimation, image manipulation, or 3D reconstruction, it is crucial to know when and where to trust the estimated correspondences. In this work, we aim to estimate a dense flow field relating two images, coupled with a robust pixel-wise confidence map indicating the reliability and accuracy of the prediction. We develop a flexible probabilistic approach that jointly learns the flow prediction and its uncertainty. In particular, we parametrize the predictive distribution as a constrained mixture model, ensuring better modelling of both accurate flow predictions and outliers. Moreover, we develop an architecture and training strategy tailored for robust and generalizable uncertainty prediction in the context of self-supervised training. Our approach obtains state-of-the-art results on multiple challenging geometric matching and optical flow datasets. We further validate the usefulness of our probabilistic confidence estimation for the task of pose estimation. Code and models will be released at github.com/PruneTruong/PDCNet.