 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Search for Resource-Efficient Branched Multi-Task Networks
Paper and Code

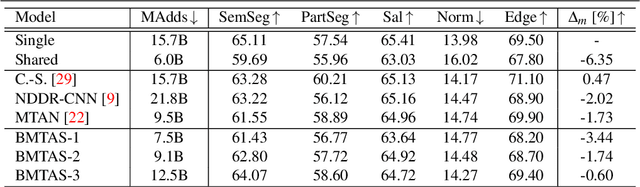

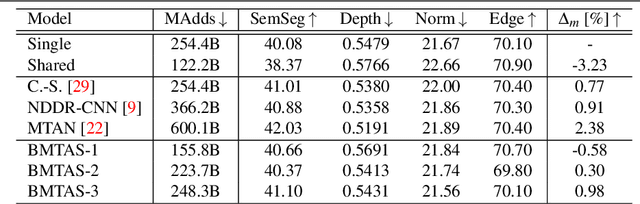
The multi-modal nature of many vision problems calls for neural network architectures that can perform multiple tasks concurrently. Typically, such architectures have been handcrafted in the literature. However, given the size and complexity of the problem, this manual architecture exploration likely exceeds human design abilities. In this paper, we propose a principled approach, rooted in differentiable neural architecture search, to automatically define branching (tree-like) structures in the encoding stage of a multi-task neural network. To allow flexibility within resource-constrained environments, we introduce a proxyless, resource-aware loss that dynamically controls the model size. Evaluations across a variety of dense prediction tasks show that our approach consistently finds high-performing branching structures within limited resource budgets.