 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Task Decathlon: Unifying Image and Video Tasks in Autonomous Driving
Sep 08, 2023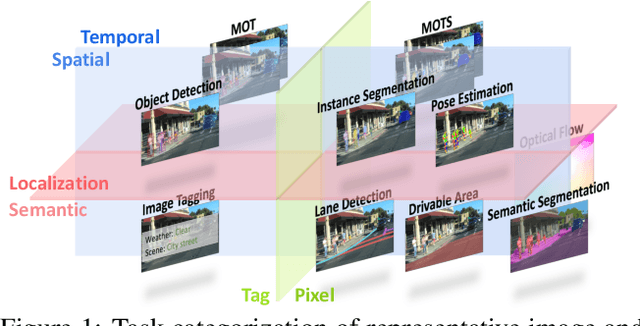

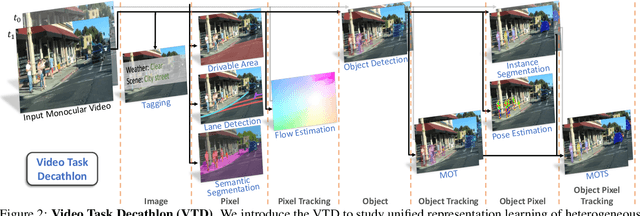
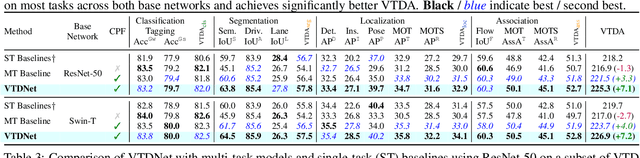
Performing multiple heterogeneous visual tasks in dynamic scenes is a hallmark of human perception capability. Despite remarkable progress in image and video recognition via representation learning, current research still focuses on designing specialized networks for singular, homogeneous, or simple combination of tasks. We instead explore the construction of a unified model for major image and video recognition tasks in autonomous driving with diverse input and output structures. To enable such an investigation, we design a new challenge, Video Task Decathlon (VTD), which includes ten representative image and video tasks spanning classification, segmentation, localization, and association of objects and pixels. On VTD, we develop our unified network, VTDNet, that uses a single structure and a single set of weights for all ten tasks. VTDNet groups similar tasks and employs task interaction stages to exchange information within and between task groups. Given the impracticality of labeling all tasks on all frames, and the performance degradation associated with joint training of many tasks, we design a Curriculum training, Pseudo-labeling, and Fine-tuning (CPF) scheme to successfully train VTDNet on all tasks and mitigate performance loss. Armed with CPF, VTDNet significantly outperforms its single-task counterparts on most tasks with only 20% overall computations. VTD is a promising new direction for exploring the unification of perception tasks in autonomous driving.
Composite Learning for Robust and Effective Dense Predictions
Oct 13, 2022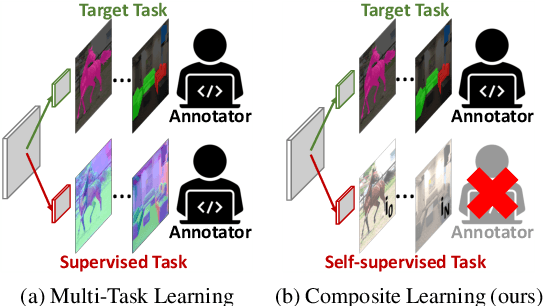
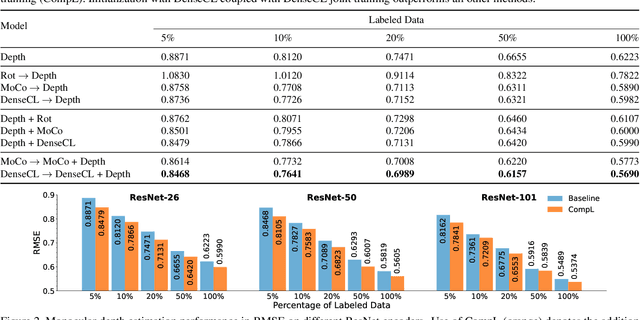
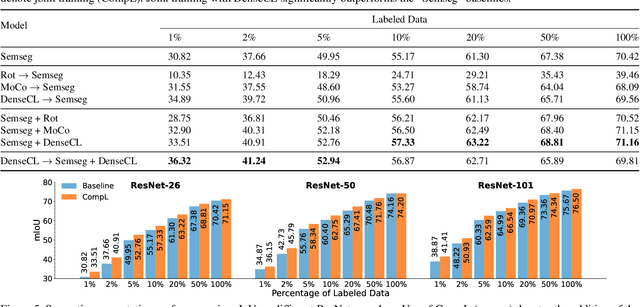
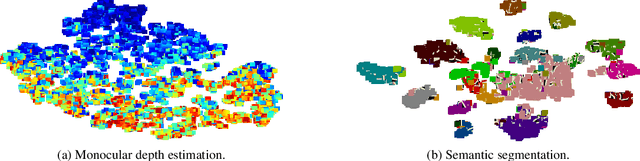
Multi-task learning promises better model generalization on a target task by jointly optimizing it with an auxiliary task. However, the current practice requires additional labeling efforts for the auxiliary task, while not guaranteeing better model performance. In this paper, we find that jointly training a dense prediction (target) task with a self-supervised (auxiliary) task can consistently improve the performance of the target task, while eliminating the need for labeling auxiliary tasks. We refer to this joint training as Composite Learning (CompL). Experiments of CompL on monocular depth estimation, semantic segmentation, and boundary detection show consistent performance improvements in fully and partially labeled datasets. Further analysis on depth estimation reveals that joint training with self-supervision outperforms most labeled auxiliary tasks. We also find that CompL can improve model robustness when the models are evaluated in new domains. These results demonstrate the benefits of self-supervision as an auxiliary task, and establish the design of novel task-specific self-supervised methods as a new axis of investigation for future multi-task learning research.
QDTrack: Quasi-Dense Similarity Learning for Appearance-Only Multiple Object Tracking
Oct 12, 2022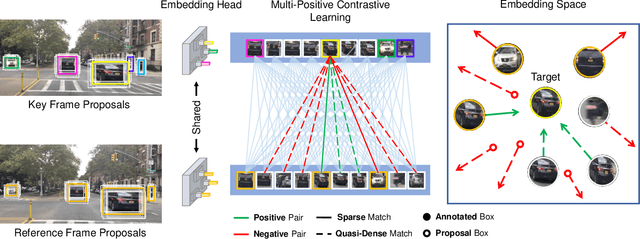
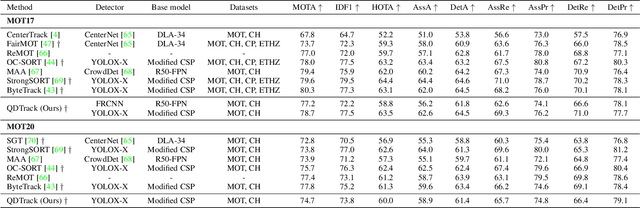
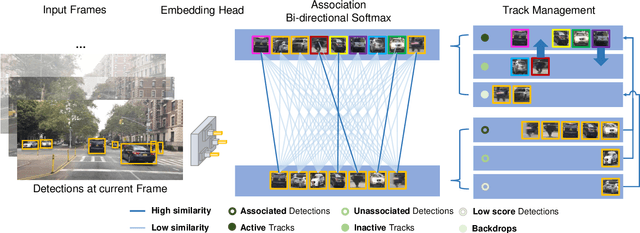
Similarity learning has been recognized as a crucial step for object tracking. However, existing multiple object tracking methods only use sparse ground truth matching as the training objective, while ignoring the majority of the informative regions in images. In this paper, we present Quasi-Dense Similarity Learning, which densely samples hundreds of object regions on a pair of images for contrastive learning. We combine this similarity learning with multiple existing object detectors to build Quasi-Dense Tracking (QDTrack), which does not require displacement regression or motion priors. We find that the resulting distinctive feature space admits a simple nearest neighbor search at inference time for object association. In addition, we show that our similarity learning scheme is not limited to video data, but can learn effective instance similarity even from static input, enabling a competitive tracking performance without training on videos or using tracking supervision. We conduct extensive experiments on a wide variety of popular MOT benchmarks. We find that, despite its simplicity, QDTrack rivals the performance of state-of-the-art tracking methods on all benchmarks and sets a new state-of-the-art on the large-scale BDD100K MOT benchmark, while introducing negligible computational overhead to the detector.
Tracking Every Thing in the Wild
Jul 26, 2022


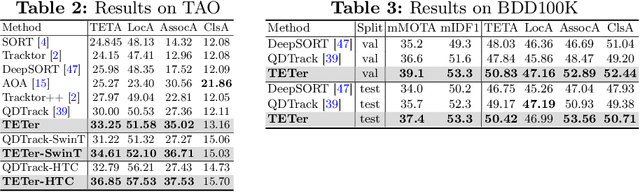
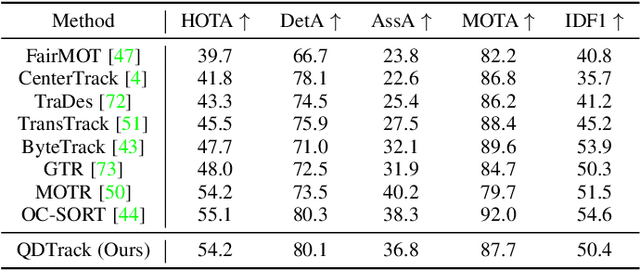
Current multi-category Multiple Object Tracking (MOT) metrics use class labels to group tracking results for per-class evaluation. Similarly, MOT methods typically only associate objects with the same class predictions. These two prevalent strategies in MOT implicitly assume that the classification performance is near-perfect. However, this is far from the case in recent large-scale MOT datasets, which contain large numbers of classes with many rare or semantically similar categories. Therefore, the resulting inaccurate classification leads to sub-optimal tracking and inadequate benchmarking of trackers. We address these issues by disentangling classification from tracking. We introduce a new metric, Track Every Thing Accuracy (TETA), breaking tracking measurement into three sub-factors: localization, association, and classification, allowing comprehensive benchmarking of tracking performance even under inaccurate classification. TETA also deals with the challenging incomplete annotation problem in large-scale tracking datasets. We further introduce a Track Every Thing tracker (TETer), that performs association using Class Exemplar Matching (CEM). Our experiments show that TETA evaluates trackers more comprehensively, and TETer achieves significant improvements on the challenging large-scale datasets BDD100K and TAO compared to the state-of-the-art.
Dense Prediction with Attentive Feature Aggregation
Nov 01, 2021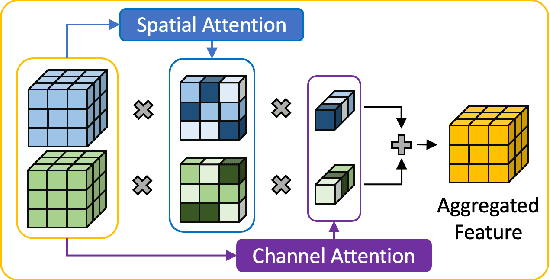

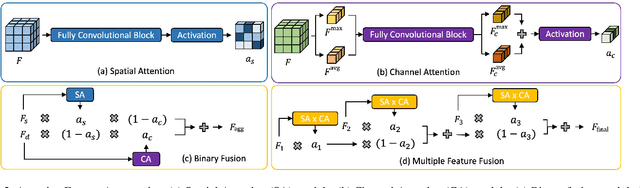
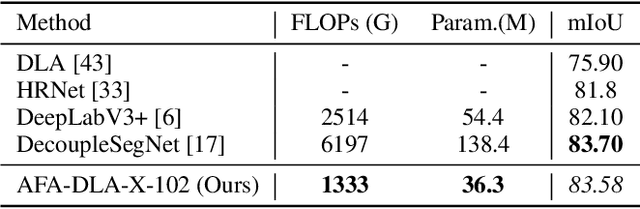
Aggregating information from features across different layers is an essential operation for dense prediction models. Despite its limited expressiveness, feature concatenation dominates the choice of aggregation operations. In this paper, we introduce Attentive Feature Aggregation (AFA) to fuse different network layers with more expressive non-linear operations. AFA exploits both spatial and channel attention to compute weighted average of the layer activations. Inspired by neural volume rendering, we extend AFA with Scale-Space Rendering (SSR) to perform late fusion of multi-scale predictions. AFA is applicable to a wide range of existing network designs. Our experiments show consistent and significant improvements on challenging semantic segmentation benchmarks, including Cityscapes, BDD100K, and Mapillary Vistas, at negligible computational and parameter overhead. In particular, AFA improves the performance of the Deep Layer Aggregation (DLA) model by nearly 6% mIoU on Cityscapes. Our experimental analyses show that AFA learns to progressively refine segmentation maps and to improve boundary details, leading to new state-of-the-art results on boundary detection benchmarks on BSDS500 and NYUDv2. Code and video resources are available at http://vis.xyz/pub/dla-afa.
Robust Object Detection via Instance-Level Temporal Cycle Confusion
Apr 16, 2021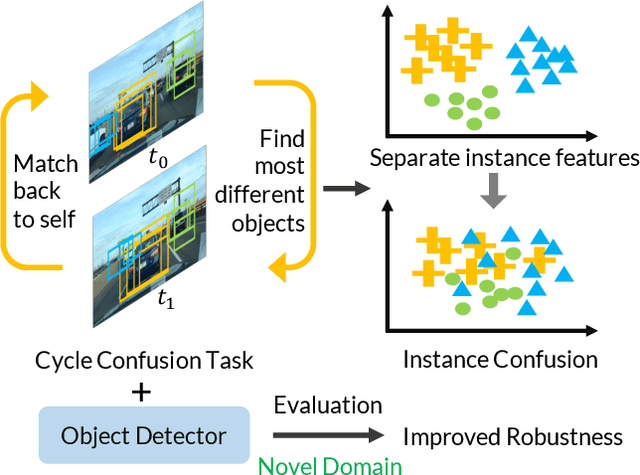
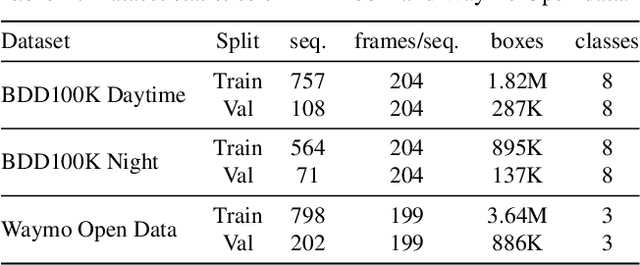
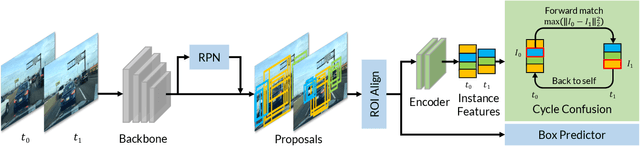
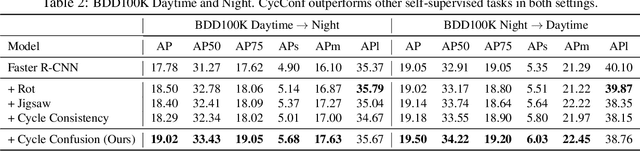
Building reliable object detectors that are robust to domain shifts, such as various changes in context, viewpoint, and object appearances, is critical for real-world applications. In this work, we study the effectiveness of auxiliary self-supervised tasks to improve the out-of-distribution generalization of object detectors. Inspired by the principle of maximum entropy, we introduce a novel self-supervised task, instance-level temporal cycle confusion (CycConf), which operates on the region features of the object detectors. For each object, the task is to find the most different object proposals in the adjacent frame in a video and then cycle back to itself for self-supervision. CycConf encourages the object detector to explore invariant structures across instances under various motions, which leads to improved model robustness in unseen domains at test time. We observe consistent out-of-domain performance improvements when training object detectors in tandem with self-supervised tasks on large-scale video datasets (BDD100K and Waymo open data). The joint training framework also establishes a new state-of-the-art on standard unsupervised domain adaptative detection benchmarks (Cityscapes, Foggy Cityscapes, and Sim10K). The project page is available at https://xinw.ai/cyc-conf.
Frustratingly Simple Few-Shot Object Detection
Mar 16, 2020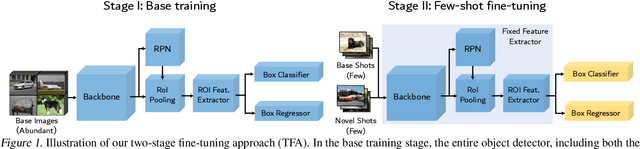
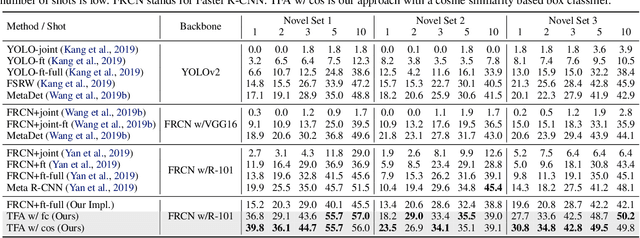
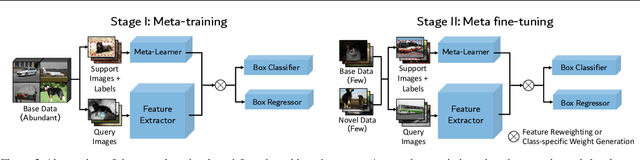
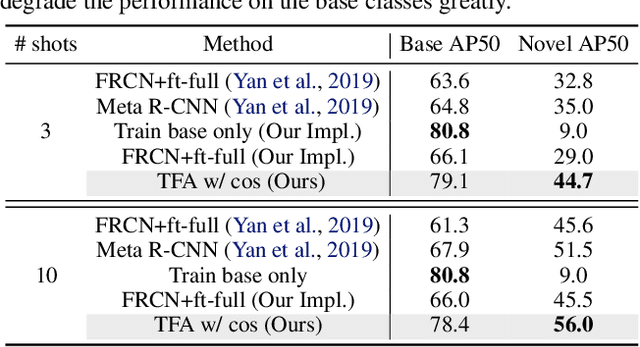
Detecting rare objects from a few examples is an emerging problem. Prior works show meta-learning is a promising approach. But, fine-tuning techniques have drawn scant attention. We find that fine-tuning only the last layer of existing detectors on rare classes is crucial to the few-shot object detection task. Such a simple approach outperforms the meta-learning methods by roughly 2~20 points on current benchmarks and sometimes even doubles the accuracy of the prior methods. However, the high variance in the few samples often leads to the unreliability of existing benchmarks. We revise the evaluation protocols by sampling multiple groups of training examples to obtain stable comparisons and build new benchmarks based on three datasets: PASCAL VOC, COCO and LVIS. Again, our fine-tuning approach establishes a new state of the art on the revised benchmarks. The code as well as the pretrained models are available at https://github.com/ucbdrive/few-shot-object-detection.