 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Exploiter: A Data Efficient Approach for Competitive Self-Play
Nov 28, 2023Recent advances in Competitive Self-Play (CSP) have achieved, or even surpassed, human level performance in complex game environments such as Dota 2 and StarCraft II using Distributed Multi-Agent Reinforcement Learning (MARL). One core component of these methods relies on creating a pool of learning agents -- consisting of the Main Agent, past versions of this agent, and Exploiter Agents -- where Exploiter Agents learn counter-strategies to the Main Agents. A key drawback of these approaches is the large computational cost and physical time that is required to train the system, making them impractical to deploy in highly iterative real-life settings such as video game productions. In this paper, we propose the Minimax Exploiter, a game theoretic approach to exploiting Main Agents that leverages knowledge of its opponents, leading to significant increases in data efficiency. We validate our approach in a diversity of settings, including simple turn based games, the arcade learning environment, and For Honor, a modern video game. The Minimax Exploiter consistently outperforms strong baselines, demonstrating improved stability and data efficiency, leading to a robust CSP-MARL method that is both flexible and easy to deploy.
Graph augmented Deep Reinforcement Learning in the GameRLand3D environment
Dec 22, 2021


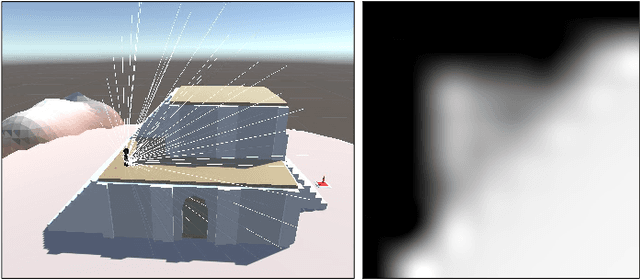
We address planning and navigation in challenging 3D video games featuring maps with disconnected regions reachable by agents using special actions. In this setting, classical symbolic planners are not applicable or difficult to adapt. We introduce a hybrid technique combining a low level policy trained with reinforcement learning and a graph based high level classical planner. In addition to providing human-interpretable paths, the approach improves the generalization performance of an end-to-end approach in unseen maps, where it achieves a 20% absolute increase in success rate over a recurrent end-to-end agent on a point to point navigation task in yet unseen large-scale maps of size 1km x 1km. In an in-depth experimental study, we quantify the limitations of end-to-end Deep RL approaches in vast environments and we also introduce "GameRLand3D", a new benchmark and soon to be released environment can generate complex procedural 3D maps for navigation tasks.