 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph augmented Deep Reinforcement Learning in the GameRLand3D environment
Dec 22, 2021


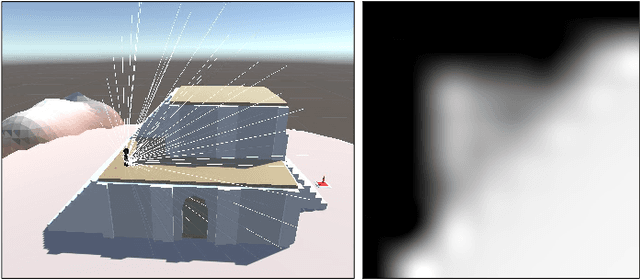
We address planning and navigation in challenging 3D video games featuring maps with disconnected regions reachable by agents using special actions. In this setting, classical symbolic planners are not applicable or difficult to adapt. We introduce a hybrid technique combining a low level policy trained with reinforcement learning and a graph based high level classical planner. In addition to providing human-interpretable paths, the approach improves the generalization performance of an end-to-end approach in unseen maps, where it achieves a 20% absolute increase in success rate over a recurrent end-to-end agent on a point to point navigation task in yet unseen large-scale maps of size 1km x 1km. In an in-depth experimental study, we quantify the limitations of end-to-end Deep RL approaches in vast environments and we also introduce "GameRLand3D", a new benchmark and soon to be released environment can generate complex procedural 3D maps for navigation tasks.
Reinforcement Learning Agents for Ubisoft's Roller Champions
Dec 10, 2020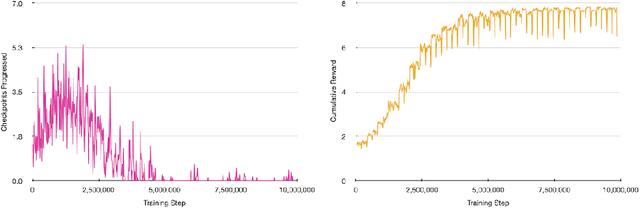
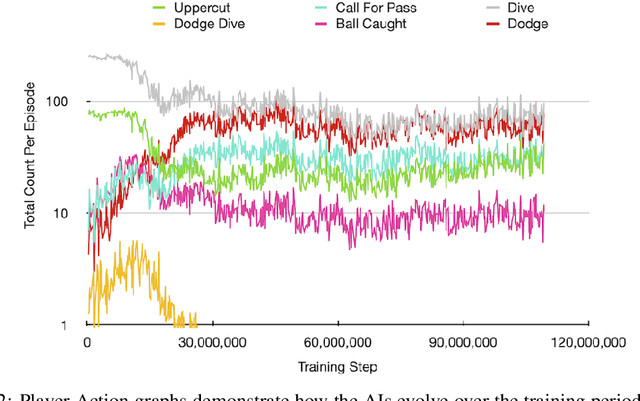
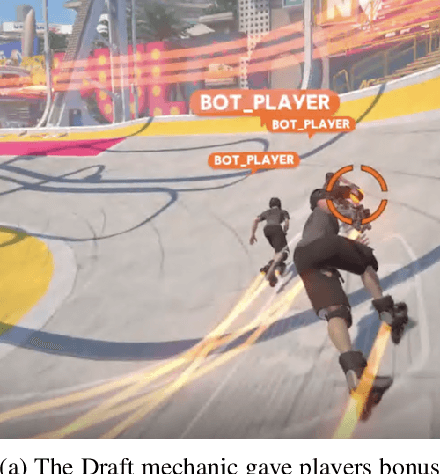
In recent years, Reinforcement Learning (RL) has seen increasing popularity in research and popular culture. However, skepticism still surrounds the practicality of RL in modern video game development. In this paper, we demonstrate by example that RL can be a great tool for Artificial Intelligence (AI) design in modern, non-trivial video games. We present our RL system for Ubisoft's Roller Champions, a 3v3 Competitive Multiplayer Sports Game played on an oval-shaped skating arena. Our system is designed to keep up with agile, fast-paced development, taking 1--4 days to train a new model following gameplay changes. The AIs are adapted for various game modes, including a 2v2 mode, a Training with Bots mode, in addition to the Classic game mode where they replace players who have disconnected. We observe that the AIs develop sophisticated co-ordinated strategies, and can aid in balancing the game as an added bonus. Please see the accompanying video at https://vimeo.com/466780171 (password: rollerRWRL2020) for examples.
Deep Reinforcement Learning for Navigation in AAA Video Games
Nov 09, 2020
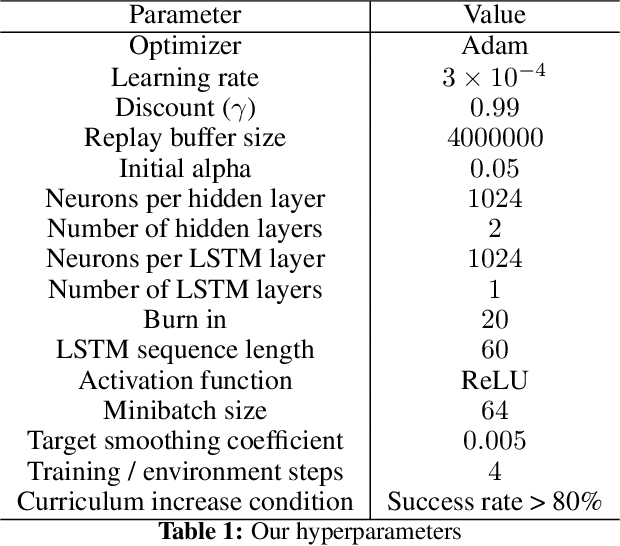
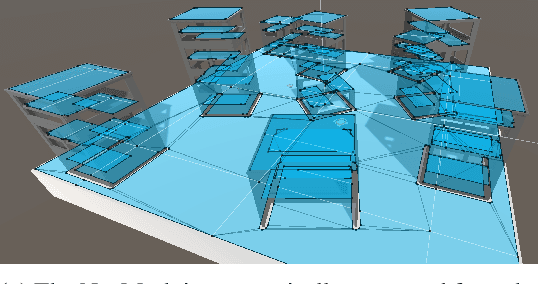
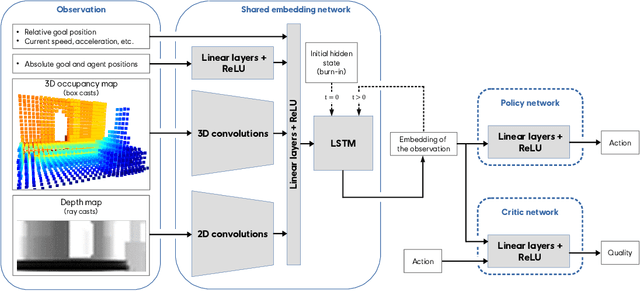
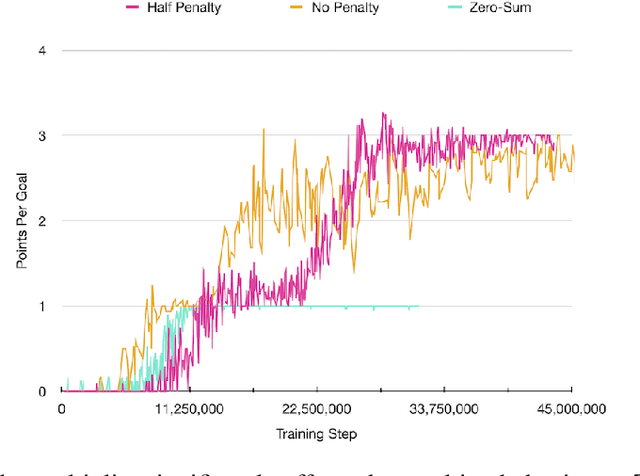
In video games, non-player characters (NPCs) are used to enhance the players' experience in a variety of ways, e.g., as enemies, allies, or innocent bystanders. A crucial component of NPCs is navigation, which allows them to move from one point to another on the map. The most popular approach for NPC navigation in the video game industry is to use a navigation mesh (NavMesh), which is a graph representation of the map, with nodes and edges indicating traversable areas. Unfortunately, complex navigation abilities that extend the character's capacity for movement, e.g., grappling hooks, jetpacks, teleportation, or double-jumps, increases the complexity of the NavMesh, making it intractable in many practical scenarios. Game designers are thus constrained to only add abilities that can be handled by a NavMesh if they want to have NPC navigation. As an alternative, we propose to use Deep Reinforcement Learning (Deep RL) to learn how to navigate 3D maps using any navigation ability. We test our approach on complex 3D environments in the Unity game engine that are notably an order of magnitude larger than maps typically used in the Deep RL literature. One of these maps is directly modeled after a Ubisoft AAA game. We find that our approach performs surprisingly well, achieving at least $90\%$ success rate on all tested scenarios. A video of our results is available at https://youtu.be/WFIf9Wwlq8M.
Discrete and Continuous Action Representation for Practical RL in Video Games
Dec 23, 2019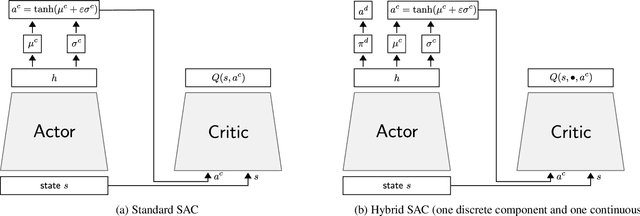
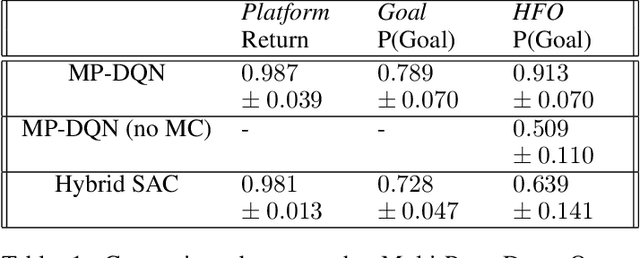
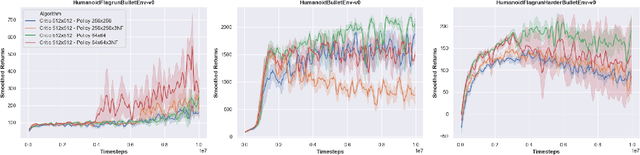
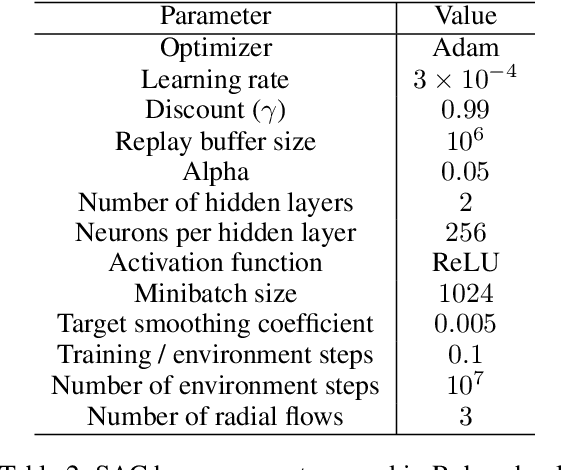
While most current research in Reinforcement Learning (RL) focuses on improving the performance of the algorithms in controlled environments, the use of RL under constraints like those met in the video game industry is rarely studied. Operating under such constraints, we propose Hybrid SAC, an extension of the Soft Actor-Critic algorithm able to handle discrete, continuous and parameterized actions in a principled way. We show that Hybrid SAC can successfully solve a highspeed driving task in one of our games, and is competitive with the state-of-the-art on parameterized actions benchmark tasks. We also explore the impact of using normalizing flows to enrich the expressiveness of the policy at minimal computational cost, and identify a potential undesired effect of SAC when used with normalizing flows, that may be addressed by optimizing a different objective.