 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDP: Spiking Diffusion Policy for Robotic Manipulation with Learnable Channel-Wise Membrane Thresholds
Sep 17, 2024



This paper introduces a Spiking Diffusion Policy (SDP) learning method for robotic manipulation by integrating Spiking Neurons and Learnable Channel-wise Membrane Thresholds (LCMT) into the diffusion policy model, thereby enhancing computational efficiency and achieving high performance in evaluated tasks. Specifically, the proposed SDP model employs the U-Net architecture as the backbone for diffusion learning within the Spiking Neural Network (SNN). It strategically places residual connections between the spike convolution operations and the Leaky Integrate-and-Fire (LIF) nodes, thereby preventing disruptions to the spiking states. Additionally, we introduce a temporal encoding block and a temporal decoding block to transform static and dynamic data with timestep $T_S$ into each other, enabling the transmission of data within the SNN in spike format. Furthermore, we propose LCMT to enable the adaptive acquisition of membrane potential thresholds, thereby matching the conditions of varying membrane potentials and firing rates across channels and avoiding the cumbersome process of manually setting and tuning hyperparameters. Evaluating the SDP model on seven distinct tasks with SNN timestep $T_S=4$, we achieve results comparable to those of the ANN counterparts, along with faster convergence speeds than the baseline SNN method. This improvement is accompanied by a reduction of 94.3\% in dynamic energy consumption estimated on 45nm hardware.
FBPT: A Fully Binary Point Transformer
Mar 15, 2024



This paper presents a novel Fully Binary Point Cloud Transformer (FBPT) model which has the potential to be widely applied and expanded in the fields of robotics and mobile devices. By compressing the weights and activations of a 32-bit full-precision network to 1-bit binary values, the proposed binary point cloud Transformer network significantly reduces the storage footprint and computational resource requirements of neural network models for point cloud processing tasks, compared to full-precision point cloud networks. However, achieving a fully binary point cloud Transformer network, where all parts except the modules specific to the task are binary, poses challenges and bottlenecks in quantizing the activations of Q, K, V and self-attention in the attention module, as they do not adhere to simple probability distributions and can vary with input data. Furthermore, in our network, the binary attention module undergoes a degradation of the self-attention module due to the uniform distribution that occurs after the softmax operation. The primary focus of this paper is on addressing the performance degradation issue caused by the use of binary point cloud Transformer modules. We propose a novel binarization mechanism called dynamic-static hybridization. Specifically, our approach combines static binarization of the overall network model with fine granularity dynamic binarization of data-sensitive components. Furthermore, we make use of a novel hierarchical training scheme to obtain the optimal model and binarization parameters. These above improvements allow the proposed binarization method to outperform binarization methods applied to convolution neural networks when used in point cloud Transformer structures. To demonstrate the superiority of our algorithm, we conducted experiments on two different tasks: point cloud classification and place recognition.
BPT: Binary Point Cloud Transformer for Place Recognition
Mar 02, 2023Place recognition, an algorithm to recognize the re-visited places, plays the role of back-end optimization trigger in a full SLAM system. Many works equipped with deep learning tools, such as MLP, CNN, and transformer, have achieved great improvements in this research field. Point cloud transformer is one of the excellent frameworks for place recognition applied in robotics, but with large memory consumption and expensive computation, it is adverse to widely deploy the various point cloud transformer networks in mobile or embedded devices. To solve this issue, we propose a binary point cloud transformer for place recognition. As a result, a 32-bit full-precision model can be reduced to a 1-bit model with less memory occupation and faster binarized bitwise operations. To our best knowledge, this is the first binary point cloud transformer that can be deployed on mobile devices for online applications such as place recognition. Experiments on several standard benchmarks demonstrate that the proposed method can get comparable results with the corresponding full-precision transformer model and even outperform some full-precision deep learning methods. For example, the proposed method achieves 93.28% at the top @1% and 85.74% at the top @1% on the Oxford RobotCar dataset in terms of the metric of the average recall rate. Meanwhile, the size and floating point operations of the model with the same transformer structure reduce 56.1% and 34.1% respectively from original precision to binary precision.
HiTPR: Hierarchical Transformer for Place Recognition in Point Cloud
Apr 12, 2022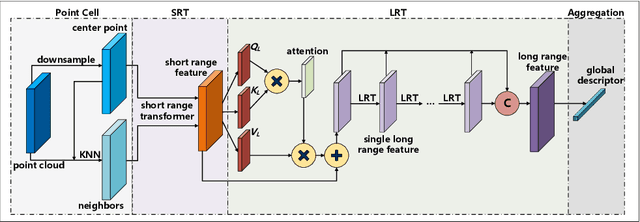
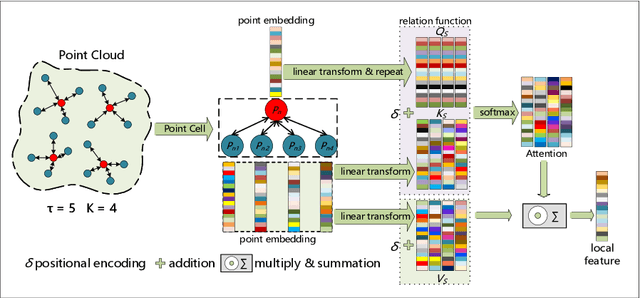
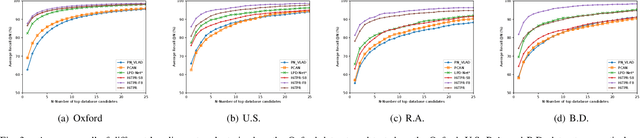

Place recognition or loop closure detection is one of the core components in a full SLAM system. In this paper, aiming at strengthening the relevancy of local neighboring points and the contextual dependency among global points simultaneously, we investigate the exploitation of transformer-based network for feature extraction, and propose a Hierarchical Transformer for Place Recognition (HiTPR). The HiTPR consists of four major parts: point cell generation, short-range transformer (SRT), long-range transformer (LRT) and global descriptor aggregation. Specifically, the point cloud is initially divided into a sequence of small cells by downsampling and nearest neighbors searching. In the SRT, we extract the local feature for each point cell. While in the LRT, we build the global dependency among all of the point cells in the whole point cloud. Experiments on several standard benchmarks demonstrate the superiority of the HiTPR in terms of average recall rate, achieving 93.71% at top 1% and 86.63% at top 1 on the Oxford RobotCar dataset for example.