 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Latent Dynamics Prediction is a Strong Baseline For Behavioral Foundation Models
Mar 16, 2026Behavioral Foundation Models (BFMs) produce agents with the capability to adapt to any unknown reward or task. These methods, however, are only able to produce near-optimal policies for the reward functions that are in the span of some pre-existing state features, making the choice of state features crucial to the expressivity of the BFM. As a result, BFMs are trained using a variety of complex objectives and require sufficient dataset coverage, to train task-useful spanning features. In this work, we examine the question: are these complex representation learning objectives necessary for zero-shot RL? Specifically, we revisit the objective of self-supervised next-state prediction in latent space for state feature learning, but observe that such an objective alone is prone to increasing state-feature similarity, and subsequently reducing span. We propose an approach, Regularized Latent Dynamics Prediction (RLDP), that adds a simple orthogonality regularization to maintain feature diversity and can match or surpass state-of-the-art complex representation learning methods for zero-shot RL. Furthermore, we empirically show that prior approaches perform poorly in low-coverage scenarios where RLDP still succeeds.
MAMA-Memeia! Multi-Aspect Multi-Agent Collaboration for Depressive Symptoms Identification in Memes
Dec 31, 2025Over the past years, memes have evolved from being exclusively a medium of humorous exchanges to one that allows users to express a range of emotions freely and easily. With the ever-growing utilization of memes in expressing depressive sentiments, we conduct a study on identifying depressive symptoms exhibited by memes shared by users of online social media platforms. We introduce RESTOREx as a vital resource for detecting depressive symptoms in memes on social media through the Large Language Model (LLM) generated and human-annotated explanations. We introduce MAMAMemeia, a collaborative multi-agent multi-aspect discussion framework grounded in the clinical psychology method of Cognitive Analytic Therapy (CAT) Competencies. MAMAMemeia improves upon the current state-of-the-art by 7.55% in macro-F1 and is established as the new benchmark compared to over 30 methods.
Clink! Chop! Thud! -- Learning Object Sounds from Real-World Interactions
Oct 02, 2025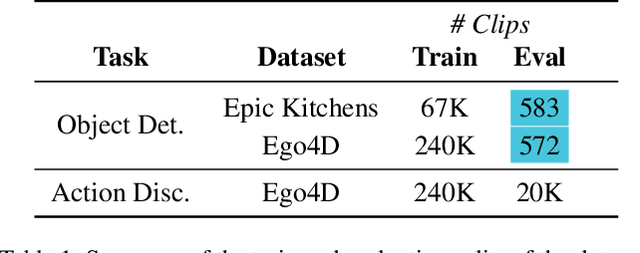

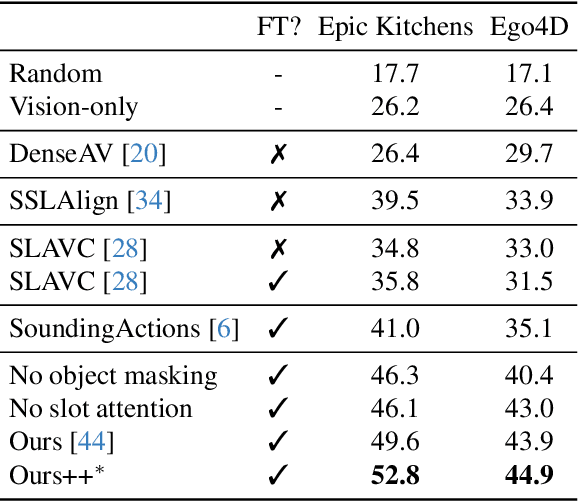
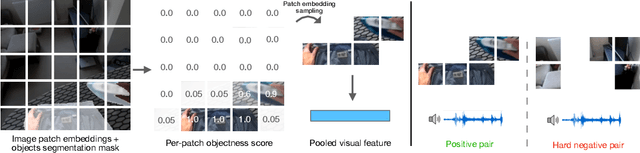
Can a model distinguish between the sound of a spoon hitting a hardwood floor versus a carpeted one? Everyday object interactions produce sounds unique to the objects involved. We introduce the sounding object detection task to evaluate a model's ability to link these sounds to the objects directly involved. Inspired by human perception, our multimodal object-aware framework learns from in-the-wild egocentric videos. To encourage an object-centric approach, we first develop an automatic pipeline to compute segmentation masks of the objects involved to guide the model's focus during training towards the most informative regions of the interaction. A slot attention visual encoder is used to further enforce an object prior. We demonstrate state of the art performance on our new task along with existing multimodal action understanding tasks.
Physics-based machine learning for mantle convection simulations
May 21, 2025Mantle convection simulations are an essential tool for understanding how rocky planets evolve. However, the poorly known input parameters to these simulations, the non-linear dependence of transport properties on pressure and temperature, and the long integration times in excess of several billion years all pose a computational challenge for numerical solvers. We propose a physics-based machine learning approach that predicts creeping flow velocities as a function of temperature while conserving mass, thereby bypassing the numerical solution of the Stokes problem. A finite-volume solver then uses the predicted velocities to advect and diffuse the temperature field to the next time-step, enabling autoregressive rollout at inference. For training, our model requires temperature-velocity snapshots from a handful of simulations (94). We consider mantle convection in a two-dimensional rectangular box with basal and internal heating, pressure- and temperature-dependent viscosity. Overall, our model is up to 89 times faster than the numerical solver. We also show the importance of different components in our convolutional neural network architecture such as mass conservation, learned paddings on the boundaries, and loss scaling for the overall rollout performance. Finally, we test our approach on unseen scenarios to demonstrate some of its strengths and weaknesses.
Null Counterfactual Factor Interactions for Goal-Conditioned Reinforcement Learning
May 06, 2025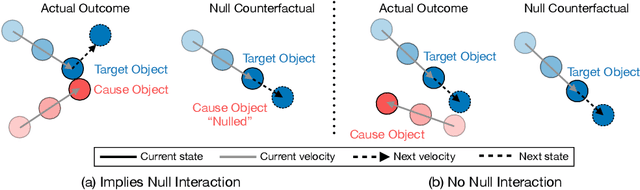
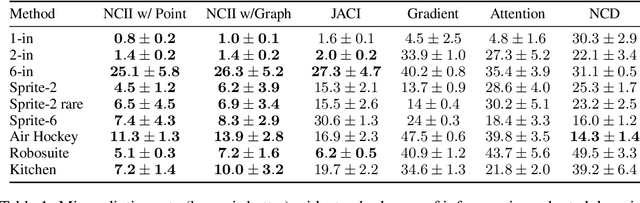
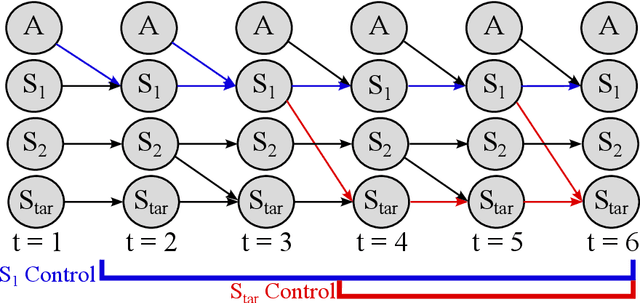

Hindsight relabeling is a powerful tool for overcoming sparsity in goal-conditioned reinforcement learning (GCRL), especially in certain domains such as navigation and locomotion. However, hindsight relabeling can struggle in object-centric domains. For example, suppose that the goal space consists of a robotic arm pushing a particular target block to a goal location. In this case, hindsight relabeling will give high rewards to any trajectory that does not interact with the block. However, these behaviors are only useful when the object is already at the goal -- an extremely rare case in practice. A dataset dominated by these kinds of trajectories can complicate learning and lead to failures. In object-centric domains, one key intuition is that meaningful trajectories are often characterized by object-object interactions such as pushing the block with the gripper. To leverage this intuition, we introduce Hindsight Relabeling using Interactions (HInt), which combines interactions with hindsight relabeling to improve the sample efficiency of downstream RL. However because interactions do not have a consensus statistical definition tractable for downstream GCRL, we propose a definition of interactions based on the concept of null counterfactual: a cause object is interacting with a target object if, in a world where the cause object did not exist, the target object would have different transition dynamics. We leverage this definition to infer interactions in Null Counterfactual Interaction Inference (NCII), which uses a "nulling'' operation with a learned model to infer interactions. NCII is able to achieve significantly improved interaction inference accuracy in both simple linear dynamics domains and dynamic robotic domains in Robosuite, Robot Air Hockey, and Franka Kitchen and HInt improves sample efficiency by up to 4x.
* Published at ICLR 2025
Reinforcement Learning Within the Classical Robotics Stack: A Case Study in Robot Soccer
Dec 12, 2024



Robot decision-making in partially observable, real-time, dynamic, and multi-agent environments remains a difficult and unsolved challenge. Model-free reinforcement learning (RL) is a promising approach to learning decision-making in such domains, however, end-to-end RL in complex environments is often intractable. To address this challenge in the RoboCup Standard Platform League (SPL) domain, we developed a novel architecture integrating RL within a classical robotics stack, while employing a multi-fidelity sim2real approach and decomposing behavior into learned sub-behaviors with heuristic selection. Our architecture led to victory in the 2024 RoboCup SPL Challenge Shield Division. In this work, we fully describe our system's architecture and empirically analyze key design decisions that contributed to its success. Our approach demonstrates how RL-based behaviors can be integrated into complete robot behavior architectures.
RL Zero: Zero-Shot Language to Behaviors without any Supervision
Dec 07, 2024Rewards remain an uninterpretable way to specify tasks for Reinforcement Learning, as humans are often unable to predict the optimal behavior of any given reward function, leading to poor reward design and reward hacking. Language presents an appealing way to communicate intent to agents and bypass reward design, but prior efforts to do so have been limited by costly and unscalable labeling efforts. In this work, we propose a method for a completely unsupervised alternative to grounding language instructions in a zero-shot manner to obtain policies. We present a solution that takes the form of imagine, project, and imitate: The agent imagines the observation sequence corresponding to the language description of a task, projects the imagined sequence to our target domain, and grounds it to a policy. Video-language models allow us to imagine task descriptions that leverage knowledge of tasks learned from internet-scale video-text mappings. The challenge remains to ground these generations to a policy. In this work, we show that we can achieve a zero-shot language-to-behavior policy by first grounding the imagined sequences in real observations of an unsupervised RL agent and using a closed-form solution to imitation learning that allows the RL agent to mimic the grounded observations. Our method, RLZero, is the first to our knowledge to show zero-shot language to behavior generation abilities without any supervision on a variety of tasks on simulated domains. We further show that RLZero can also generate policies zero-shot from cross-embodied videos such as those scraped from YouTube.
Proto Successor Measure: Representing the Space of All Possible Solutions of Reinforcement Learning
Nov 29, 2024Having explored an environment, intelligent agents should be able to transfer their knowledge to most downstream tasks within that environment. Referred to as "zero-shot learning," this ability remains elusive for general-purpose reinforcement learning algorithms. While recent works have attempted to produce zero-shot RL agents, they make assumptions about the nature of the tasks or the structure of the MDP. We present \emph{Proto Successor Measure}: the basis set for all possible solutions of Reinforcement Learning in a dynamical system. We provably show that any possible policy can be represented using an affine combination of these policy independent basis functions. Given a reward function at test time, we simply need to find the right set of linear weights to combine these basis corresponding to the optimal policy. We derive a practical algorithm to learn these basis functions using only interaction data from the environment and show that our approach can produce the optimal policy at test time for any given reward function without additional environmental interactions. Project page: https://agarwalsiddhant10.github.io/projects/psm.html.
Accelerating the discovery of steady-states of planetary interior dynamics with machine learning
Aug 30, 2024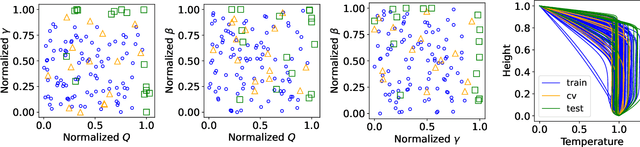

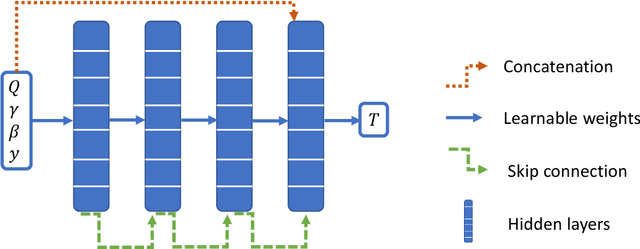
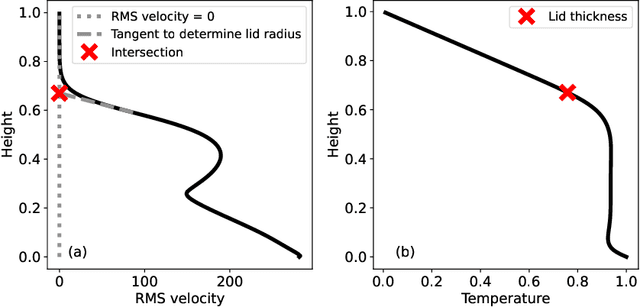
Simulating mantle convection often requires reaching a computationally expensive steady-state, crucial for deriving scaling laws for thermal and dynamical flow properties and benchmarking numerical solutions. The strong temperature dependence of the rheology of mantle rocks causes viscosity variations of several orders of magnitude, leading to a slow-evolving stagnant lid where heat conduction dominates, overlying a rapidly-evolving and strongly convecting region. Time-stepping methods, while effective for fluids with constant viscosity, are hindered by the Courant criterion, which restricts the time step based on the system's maximum velocity and grid size. Consequently, achieving steady-state requires a large number of time steps due to the disparate time scales governing the stagnant and convecting regions. We present a concept for accelerating mantle convection simulations using machine learning. We generate a dataset of 128 two-dimensional simulations with mixed basal and internal heating, and pressure- and temperature-dependent viscosity. We train a feedforward neural network on 97 simulations to predict steady-state temperature profiles. These can then be used to initialize numerical time stepping methods for different simulation parameters. Compared to typical initializations, the number of time steps required to reach steady-state is reduced by a median factor of 3.75. The benefit of this method lies in requiring very few simulations to train on, providing a solution with no prediction error as we initialize a numerical method, and posing minimal computational overhead at inference time. We demonstrate the effectiveness of our approach and discuss the potential implications for accelerated simulations for advancing mantle convection research.
Aero-Nef: Neural Fields for Rapid Aircraft Aerodynamics Simulations
Jul 29, 2024This paper presents a methodology to learn surrogate models of steady state fluid dynamics simulations on meshed domains, based on Implicit Neural Representations (INRs). The proposed models can be applied directly to unstructured domains for different flow conditions, handle non-parametric 3D geometric variations, and generalize to unseen shapes at test time. The coordinate-based formulation naturally leads to robustness with respect to discretization, allowing an excellent trade-off between computational cost (memory footprint and training time) and accuracy. The method is demonstrated on two industrially relevant applications: a RANS dataset of the two-dimensional compressible flow over a transonic airfoil and a dataset of the surface pressure distribution over 3D wings, including shape, inflow condition, and control surface deflection variations. On the considered test cases, our approach achieves a more than three times lower test error and significantly improves generalization error on unseen geometries compared to state-of-the-art Graph Neural Network architectures. Remarkably, the method can perform inference five order of magnitude faster than the high fidelity solver on the RANS transonic airfoil dataset. Code is available at https://gitlab.isae-supaero.fr/gi.catalani/aero-nepf