 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClink! Chop! Thud! -- Learning Object Sounds from Real-World Interactions
Oct 02, 2025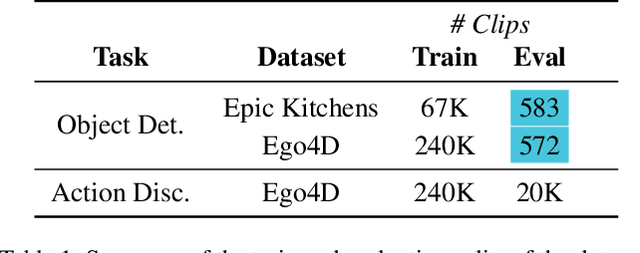

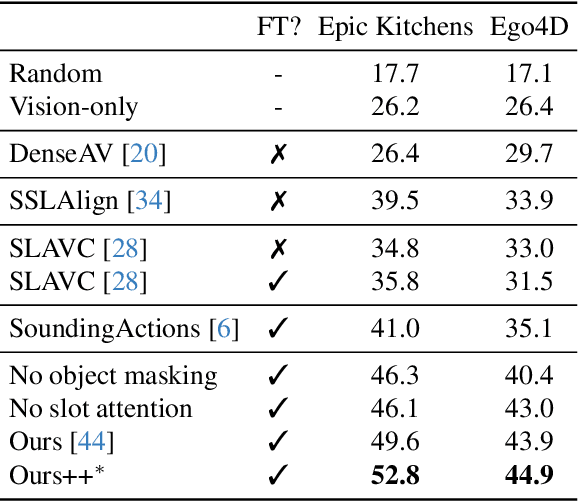
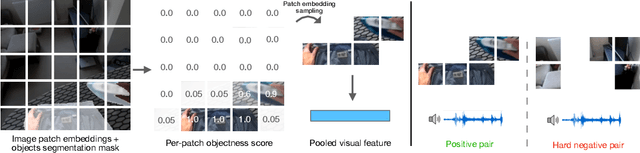
Can a model distinguish between the sound of a spoon hitting a hardwood floor versus a carpeted one? Everyday object interactions produce sounds unique to the objects involved. We introduce the sounding object detection task to evaluate a model's ability to link these sounds to the objects directly involved. Inspired by human perception, our multimodal object-aware framework learns from in-the-wild egocentric videos. To encourage an object-centric approach, we first develop an automatic pipeline to compute segmentation masks of the objects involved to guide the model's focus during training towards the most informative regions of the interaction. A slot attention visual encoder is used to further enforce an object prior. We demonstrate state of the art performance on our new task along with existing multimodal action understanding tasks.
Planning with Adaptive World Models for Autonomous Driving
Jun 15, 2024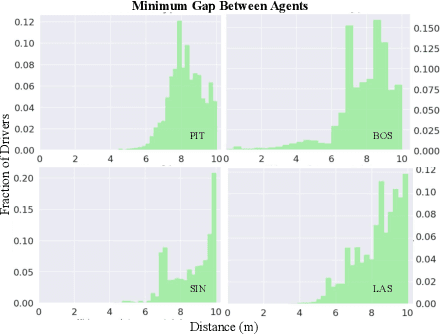

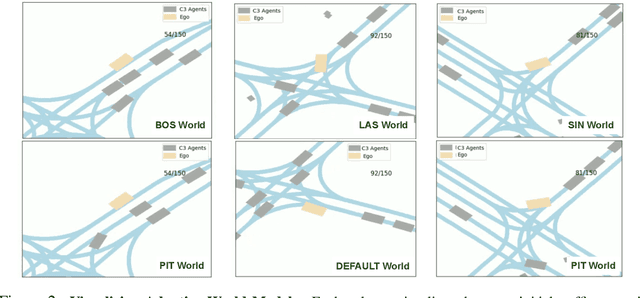

Motion planning is crucial for safe navigation in complex urban environments. Historically, motion planners (MPs) have been evaluated with procedurally-generated simulators like CARLA. However, such synthetic benchmarks do not capture real-world multi-agent interactions. nuPlan, a recently released MP benchmark, addresses this limitation by augmenting real-world driving logs with closed-loop simulation logic, effectively turning the fixed dataset into a reactive simulator. We analyze the characteristics of nuPlan's recorded logs and find that each city has its own unique driving behaviors, suggesting that robust planners must adapt to different environments. We learn to model such unique behaviors with BehaviorNet, a graph convolutional neural network (GCNN) that predicts reactive agent behaviors using features derived from recently-observed agent histories; intuitively, some aggressive agents may tailgate lead vehicles, while others may not. To model such phenomena, BehaviorNet predicts parameters of an agent's motion controller rather than predicting its spacetime trajectory (as most forecasters do). Finally, we present AdaptiveDriver, a model-predictive control (MPC) based planner that unrolls different world models conditioned on BehaviorNet's predictions. Our extensive experiments demonstrate that AdaptiveDriver achieves state-of-the-art results on the nuPlan closed-loop planning benchmark, reducing test error from 6.4% to 4.6%, even when applied to never-before-seen cities.
The Un-Kidnappable Robot: Acoustic Localization of Sneaking People
Oct 05, 2023



How easy is it to sneak up on a robot? We examine whether we can detect people using only the incidental sounds they produce as they move, even when they try to be quiet. We collect a robotic dataset of high-quality 4-channel audio paired with 360 degree RGB data of people moving in different indoor settings. We train models that predict if there is a moving person nearby and their location using only audio. We implement our method on a robot, allowing it to track a single person moving quietly with only passive audio sensing. For demonstration videos, see our project page: https://sites.google.com/view/unkidnappable-robot
Sound and Visual Representation Learning with Multiple Pretraining Tasks
Jan 04, 2022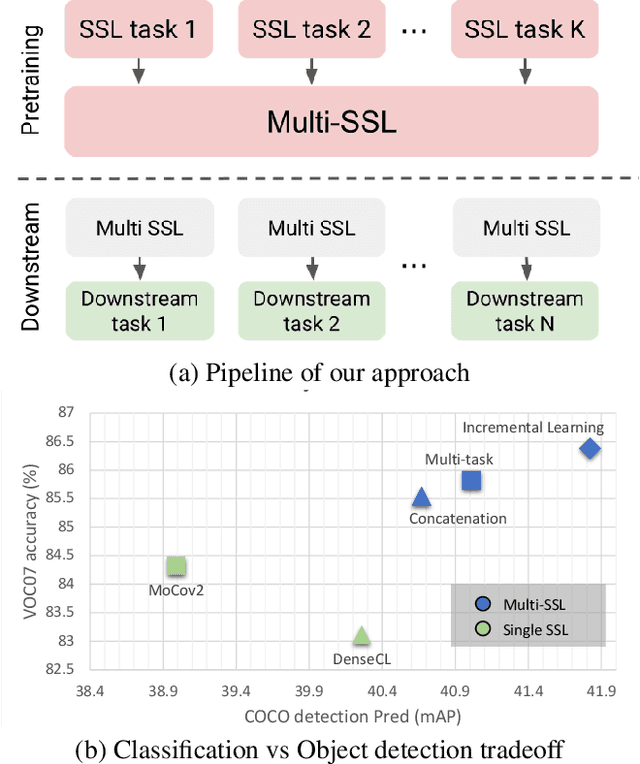

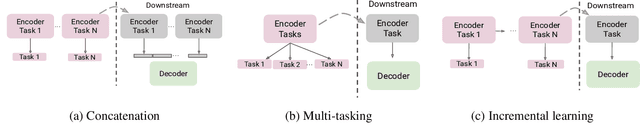
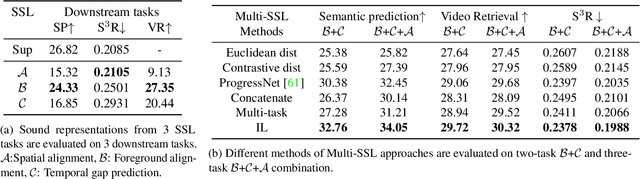
Different self-supervised tasks (SSL) reveal different features from the data. The learned feature representations can exhibit different performance for each downstream task. In this light, this work aims to combine Multiple SSL tasks (Multi-SSL) that generalizes well for all downstream tasks. Specifically, for this study, we investigate binaural sounds and image data in isolation. For binaural sounds, we propose three SSL tasks namely, spatial alignment, temporal synchronization of foreground objects and binaural audio and temporal gap prediction. We investigate several approaches of Multi-SSL and give insights into the downstream task performance on video retrieval, spatial sound super resolution, and semantic prediction on the OmniAudio dataset. Our experiments on binaural sound representations demonstrate that Multi-SSL via incremental learning (IL) of SSL tasks outperforms single SSL task models and fully supervised models in the downstream task performance. As a check of applicability on other modality, we also formulate our Multi-SSL models for image representation learning and we use the recently proposed SSL tasks, MoCov2 and DenseCL. Here, Multi-SSL surpasses recent methods such as MoCov2, DenseCL and DetCo by 2.06%, 3.27% and 1.19% on VOC07 classification and +2.83, +1.56 and +1.61 AP on COCO detection. Code will be made publicly available.
Binaural SoundNet: Predicting Semantics, Depth and Motion with Binaural Sounds
Sep 06, 2021
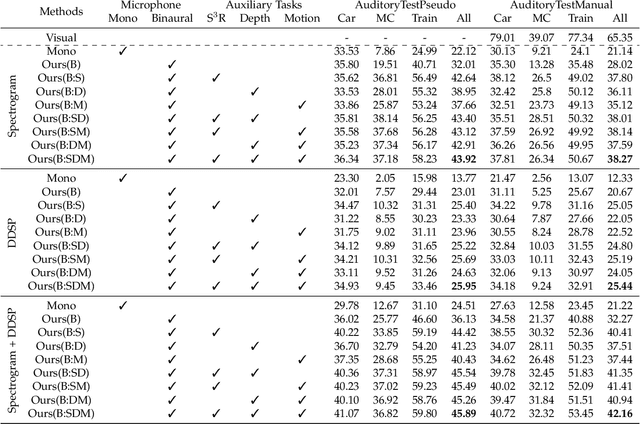
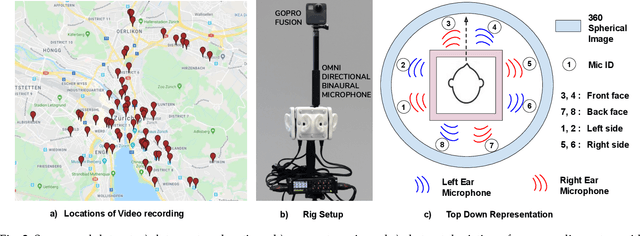
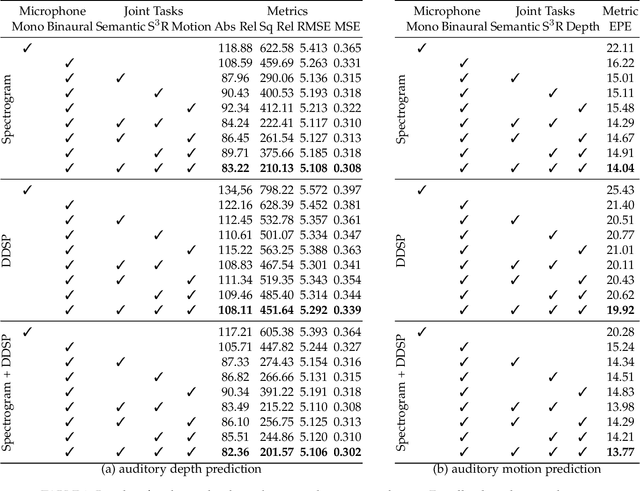
Humans can robustly recognize and localize objects by using visual and/or auditory cues. While machines are able to do the same with visual data already, less work has been done with sounds. This work develops an approach for scene understanding purely based on binaural sounds. The considered tasks include predicting the semantic masks of sound-making objects, the motion of sound-making objects, and the depth map of the scene. To this aim, we propose a novel sensor setup and record a new audio-visual dataset of street scenes with eight professional binaural microphones and a 360-degree camera. The co-existence of visual and audio cues is leveraged for supervision transfer. In particular, we employ a cross-modal distillation framework that consists of multiple vision teacher methods and a sound student method -- the student method is trained to generate the same results as the teacher methods do. This way, the auditory system can be trained without using human annotations. To further boost the performance, we propose another novel auxiliary task, coined Spatial Sound Super-Resolution, to increase the directional resolution of sounds. We then formulate the four tasks into one end-to-end trainable multi-tasking network aiming to boost the overall performance. Experimental results show that 1) our method achieves good results for all four tasks, 2) the four tasks are mutually beneficial -- training them together achieves the best performance, 3) the number and orientation of microphones are both important, and 4) features learned from the standard spectrogram and features obtained by the classic signal processing pipeline are complementary for auditory perception tasks. The data and code are released.
Semantic Object Prediction and Spatial Sound Super-Resolution with Binaural Sounds
Mar 09, 2020
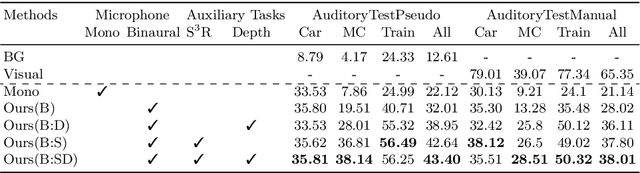

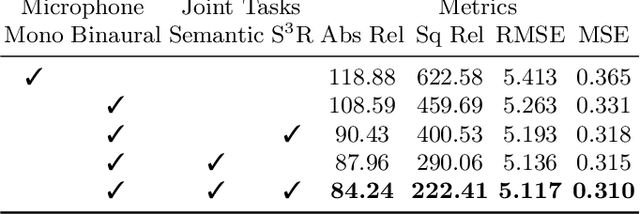
Humans can robustly recognize and localize objects by integrating visual and auditory cues. While machines are able to do the same now with images, less work has been done with sounds. This work develops an approach for dense semantic labelling of sound-making objects, purely based on binaural sounds. We propose a novel sensor setup and record a new audio-visual dataset of street scenes with eight professional binaural microphones and a 360 degree camera. The co-existence of visual and audio cues is leveraged for supervision transfer. In particular, we employ a cross-modal distillation framework that consists of a vision `teacher' method and a sound `student' method -- the student method is trained to generate the same results as the teacher method. This way, the auditory system can be trained without using human annotations. We also propose two auxiliary tasks namely, a) a novel task on Spatial Sound Super-resolution to increase the spatial resolution of sounds, and b) dense depth prediction of the scene. We then formulate the three tasks into one end-to-end trainable multi-tasking network aiming to boost the overall performance. Experimental results on the dataset show that 1) our method achieves promising results for semantic prediction and the two auxiliary tasks; and 2) the three tasks are mutually beneficial -- training them together achieves the best performance and 3) the number and orientations of microphones are both important. The data and code will be released to facilitate the research in this new direction.
Talk2Nav: Long-Range Vision-and-Language Navigation in Cities
Oct 04, 2019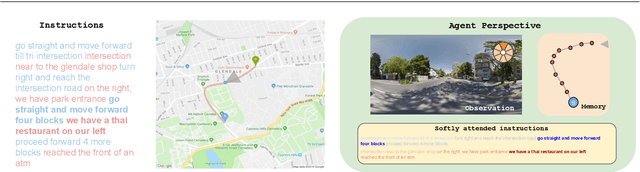
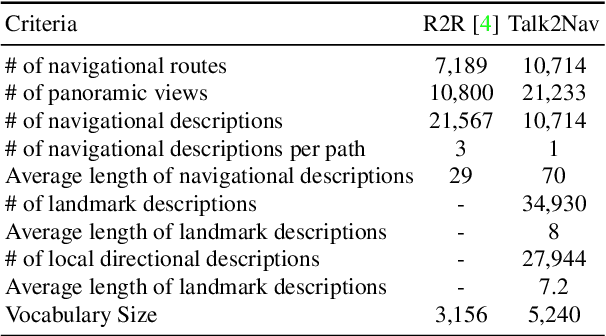
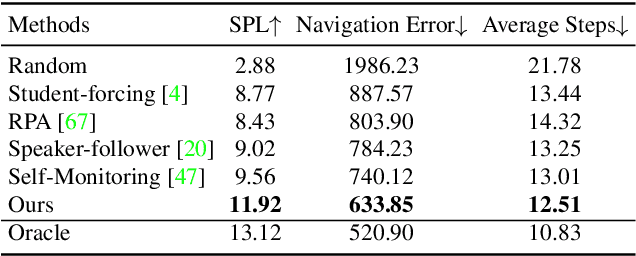
Autonomous driving models often consider the goal as fixed at the start of the ride. Yet, in practice, passengers will still want to influence the route, e.g. to pick up something along the way. In order to keep such inputs intuitive, we provide automatic way finding in cities based on verbal navigational instructions and street-view images. Our first contribution is the creation of a large-scale dataset with verbal navigation instructions. To this end, we have developed an interactive visual navigation environment based on Google Street View; we further design an annotation method to highlight mined anchor landmarks and local directions between them in order to help annotators formulate typical, human references to those. The annotation task was crowdsourced on the AMT platform, to construct a new Talk2Nav dataset with 10,714 routes. Our second contribution is a new learning method. Inspired by spatial cognition research on the mental conceptualization of navigational instructions, we introduce a soft attention mechanism defined over the segmented language instructions to jointly extract two partial instructions -- one for matching the next upcoming visual landmark and the other for matching the local directions to the next landmark. On the similar lines, we also introduce memory scheme to encode the local directional transitions. Our work takes advantage of the advance in two lines of research: mental formalization of verbal navigational instructions and training neural network agents for automatic way finding. Extensive experiments show that our method significantly outperforms previous navigation methods. For demo video, dataset and code, please refer to our \href{https://www.trace.ethz.ch/publications/2019/talk2nav/index.html}{project page}.
Object Referring in Videos with Language and Human Gaze
Apr 04, 2018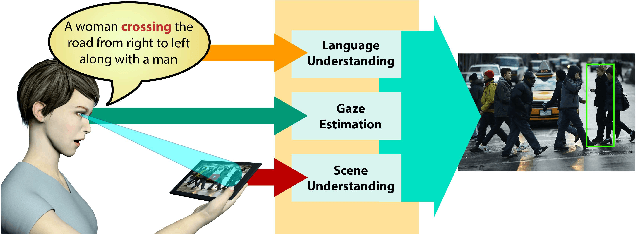
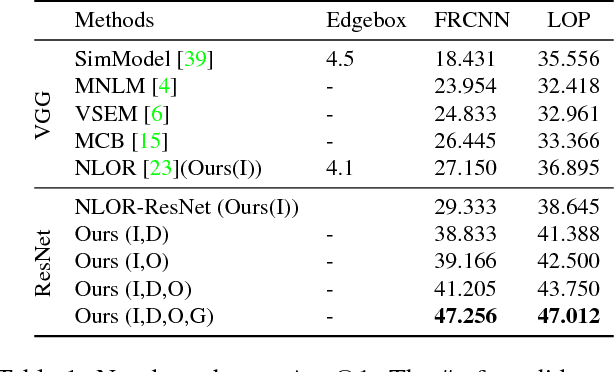
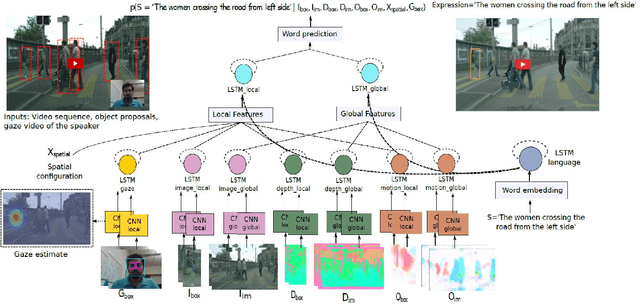
We investigate the problem of object referring (OR) i.e. to localize a target object in a visual scene coming with a language description. Humans perceive the world more as continued video snippets than as static images, and describe objects not only by their appearance, but also by their spatio-temporal context and motion features. Humans also gaze at the object when they issue a referring expression. Existing works for OR mostly focus on static images only, which fall short in providing many such cues. This paper addresses OR in videos with language and human gaze. To that end, we present a new video dataset for OR, with 30, 000 objects over 5, 000 stereo video sequences annotated for their descriptions and gaze. We further propose a novel network model for OR in videos, by integrating appearance, motion, gaze, and spatio-temporal context into one network. Experimental results show that our method effectively utilizes motion cues, human gaze, and spatio-temporal context. Our method outperforms previousOR methods. For dataset and code, please refer https://people.ee.ethz.ch/~arunv/ORGaze.html.
Object Referring in Visual Scene with Spoken Language
Dec 05, 2017



Object referring has important applications, especially for human-machine interaction. While having received great attention, the task is mainly attacked with written language (text) as input rather than spoken language (speech), which is more natural. This paper investigates Object Referring with Spoken Language (ORSpoken) by presenting two datasets and one novel approach. Objects are annotated with their locations in images, text descriptions and speech descriptions. This makes the datasets ideal for multi-modality learning. The approach is developed by carefully taking down ORSpoken problem into three sub-problems and introducing task-specific vision-language interactions at the corresponding levels. Experiments show that our method outperforms competing methods consistently and significantly. The approach is also evaluated in the presence of audio noise, showing the efficacy of the proposed vision-language interaction methods in counteracting background noise.
Query-adaptive Video Summarization via Quality-aware Relevance Estimation
Sep 28, 2017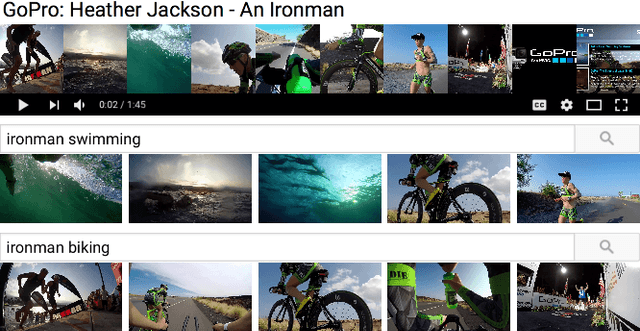
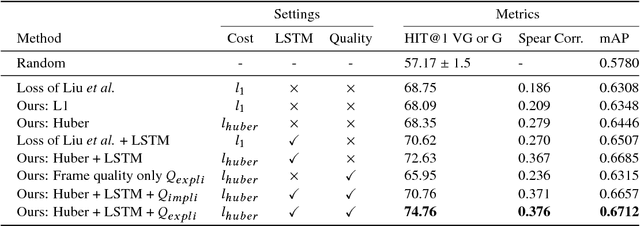
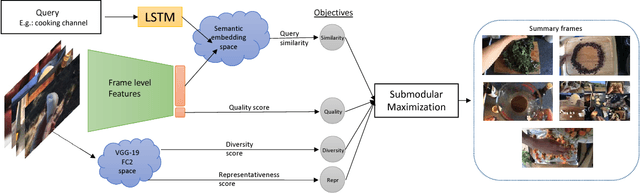
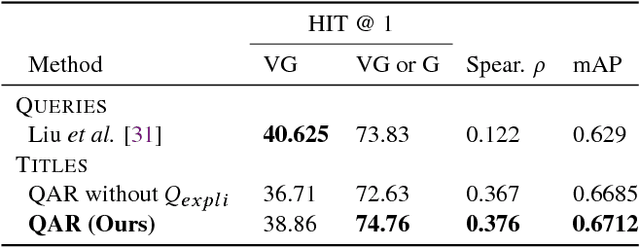
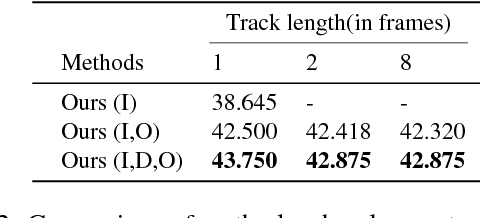
Although the problem of automatic video summarization has recently received a lot of attention, the problem of creating a video summary that also highlights elements relevant to a search query has been less studied. We address this problem by posing query-relevant summarization as a video frame subset selection problem, which lets us optimise for summaries which are simultaneously diverse, representative of the entire video, and relevant to a text query. We quantify relevance by measuring the distance between frames and queries in a common textual-visual semantic embedding space induced by a neural network. In addition, we extend the model to capture query-independent properties, such as frame quality. We compare our method against previous state of the art on textual-visual embeddings for thumbnail selection and show that our model outperforms them on relevance prediction. Furthermore, we introduce a new dataset, annotated with diversity and query-specific relevance labels. On this dataset, we train and test our complete model for video summarization and show that it outperforms standard baselines such as Maximal Marginal Relevance.