 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalk2Nav: Long-Range Vision-and-Language Navigation in Cities
Paper and Code
Oct 04, 2019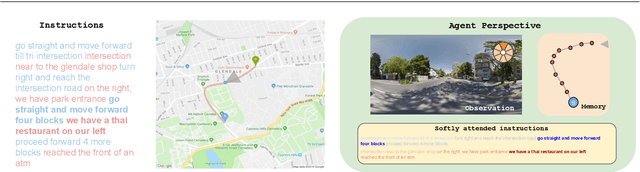
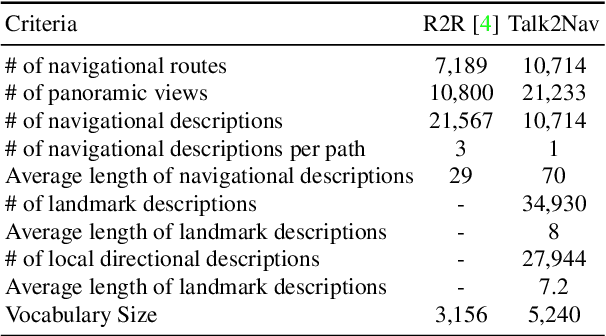
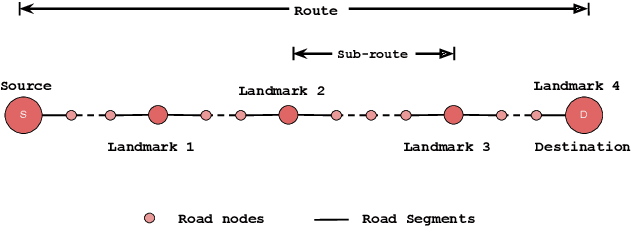
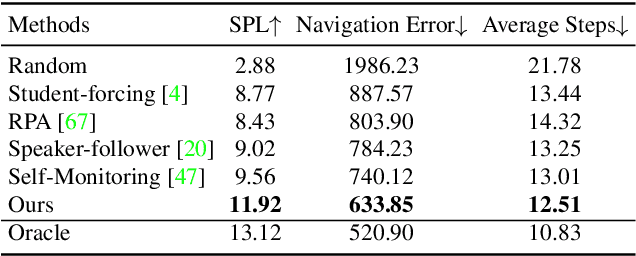
Autonomous driving models often consider the goal as fixed at the start of the ride. Yet, in practice, passengers will still want to influence the route, e.g. to pick up something along the way. In order to keep such inputs intuitive, we provide automatic way finding in cities based on verbal navigational instructions and street-view images. Our first contribution is the creation of a large-scale dataset with verbal navigation instructions. To this end, we have developed an interactive visual navigation environment based on Google Street View; we further design an annotation method to highlight mined anchor landmarks and local directions between them in order to help annotators formulate typical, human references to those. The annotation task was crowdsourced on the AMT platform, to construct a new Talk2Nav dataset with 10,714 routes. Our second contribution is a new learning method. Inspired by spatial cognition research on the mental conceptualization of navigational instructions, we introduce a soft attention mechanism defined over the segmented language instructions to jointly extract two partial instructions -- one for matching the next upcoming visual landmark and the other for matching the local directions to the next landmark. On the similar lines, we also introduce memory scheme to encode the local directional transitions. Our work takes advantage of the advance in two lines of research: mental formalization of verbal navigational instructions and training neural network agents for automatic way finding. Extensive experiments show that our method significantly outperforms previous navigation methods. For demo video, dataset and code, please refer to our \href{https://www.trace.ethz.ch/publications/2019/talk2nav/index.html}{project page}.