 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit and data-Efficient Encoding via Gradient Flow
Dec 01, 2024



The autoencoder model typically uses an encoder to map data to a lower dimensional latent space and a decoder to reconstruct it. However, relying on an encoder for inversion can lead to suboptimal representations, particularly limiting in physical sciences where precision is key. We introduce a decoder-only method using gradient flow to directly encode data into the latent space, defined by ordinary differential equations (ODEs). This approach eliminates the need for approximate encoder inversion. We train the decoder via the adjoint method and show that costly integrals can be avoided with minimal accuracy loss. Additionally, we propose a $2^{nd}$ order ODE variant, approximating Nesterov's accelerated gradient descent for faster convergence. To handle stiff ODEs, we use an adaptive solver that prioritizes loss minimization, improving robustness. Compared to traditional autoencoders, our method demonstrates explicit encoding and superior data efficiency, which is crucial for data-scarce scenarios in the physical sciences. Furthermore, this work paves the way for integrating machine learning into scientific workflows, where precise and efficient encoding is critical. \footnote{The code for this work is available at \url{https://github.com/k-flouris/gfe}.}
ALiSNet: Accurate and Lightweight Human Segmentation Network for Fashion E-Commerce
Apr 15, 2023Accurately estimating human body shape from photos can enable innovative applications in fashion, from mass customization, to size and fit recommendations and virtual try-on. Body silhouettes calculated from user pictures are effective representations of the body shape for downstream tasks. Smartphones provide a convenient way for users to capture images of their body, and on-device image processing allows predicting body segmentation while protecting users privacy. Existing off-the-shelf methods for human segmentation are closed source and cannot be specialized for our application of body shape and measurement estimation. Therefore, we create a new segmentation model by simplifying Semantic FPN with PointRend, an existing accurate model. We finetune this model on a high-quality dataset of humans in a restricted set of poses relevant for our application. We obtain our final model, ALiSNet, with a size of 4MB and 97.6$\pm$1.0$\%$ mIoU, compared to Apple Person Segmentation, which has an accuracy of 94.4$\pm$5.7$\%$ mIoU on our dataset.
Neural Face Video Compression using Multiple Views
Apr 13, 2022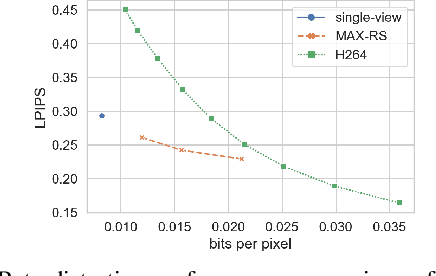
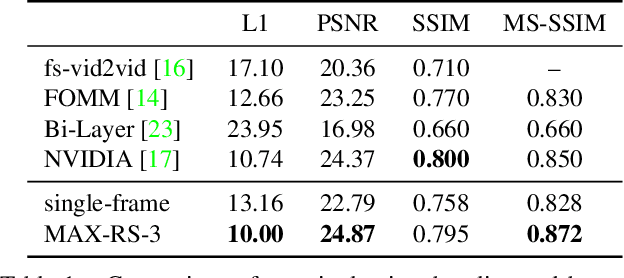

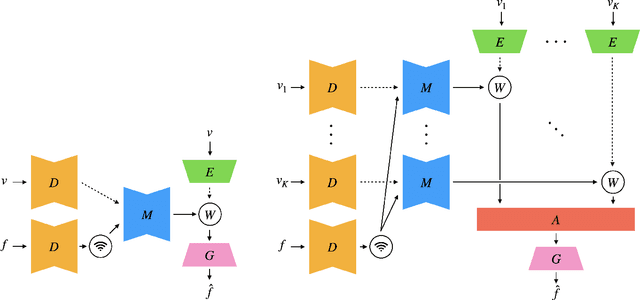
Recent advances in deep generative models led to the development of neural face video compression codecs that use an order of magnitude less bandwidth than engineered codecs. These neural codecs reconstruct the current frame by warping a source frame and using a generative model to compensate for imperfections in the warped source frame. Thereby, the warp is encoded and transmitted using a small number of keypoints rather than a dense flow field, which leads to massive savings compared to traditional codecs. However, by relying on a single source frame only, these methods lead to inaccurate reconstructions (e.g. one side of the head becomes unoccluded when turning the head and has to be synthesized). Here, we aim to tackle this issue by relying on multiple source frames (views of the face) and present encouraging results.
Gradient flow encoding with distance optimization adaptive step size
May 11, 2021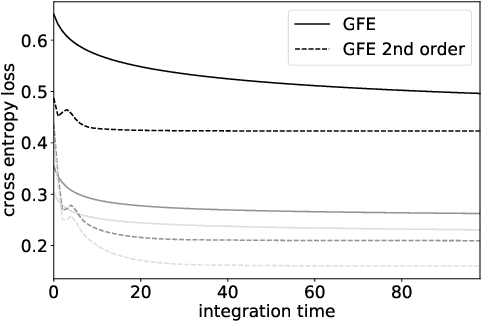
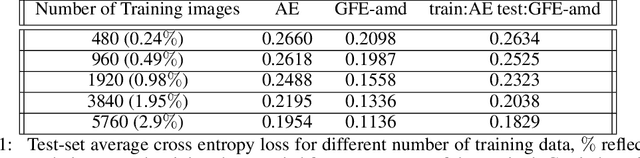
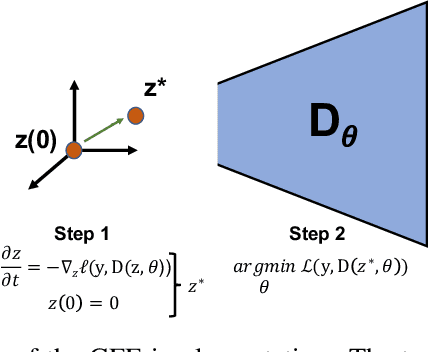

The autoencoder model uses an encoder to map data samples to a lower dimensional latent space and then a decoder to map the latent space representations back to the data space. Implicitly, it relies on the encoder to approximate the inverse of the decoder network, so that samples can be mapped to and back from the latent space faithfully. This approximation may lead to sub-optimal latent space representations. In this work, we investigate a decoder-only method that uses gradient flow to encode data samples in the latent space. The gradient flow is defined based on a given decoder and aims to find the optimal latent space representation for any given sample through optimisation, eliminating the need of an approximate inversion through an encoder. Implementing gradient flow through ordinary differential equations (ODE), we leverage the adjoint method to train a given decoder. We further show empirically that the costly integrals in the adjoint method may not be entirely necessary. Additionally, we propose a $2^{nd}$ order ODE variant to the method, which approximates Nesterov's accelerated gradient descent, with faster convergence per iteration. Commonly used ODE solvers can be quite sensitive to the integration step-size depending on the stiffness of the ODE. To overcome the sensitivity for gradient flow encoding, we use an adaptive solver that prioritises minimising loss at each integration step. We assess the proposed method in comparison to the autoencoding model. In our experiments, GFE showed a much higher data-efficiency than the autoencoding model, which can be crucial for data scarce applications.
Modelling the Distribution of 3D Brain MRI using a 2D Slice VAE
Jul 09, 2020



Probabilistic modelling has been an essential tool in medical image analysis, especially for analyzing brain Magnetic Resonance Images (MRI). Recent deep learning techniques for estimating high-dimensional distributions, in particular Variational Autoencoders (VAEs), opened up new avenues for probabilistic modeling. Modelling of volumetric data has remained a challenge, however, because constraints on available computation and training data make it difficult effectively leverage VAEs, which are well-developed for 2D images. We propose a method to model 3D MR brain volumes distribution by combining a 2D slice VAE with a Gaussian model that captures the relationships between slices. We do so by estimating the sample mean and covariance in the latent space of the 2D model over the slice direction. This combined model lets us sample new coherent stacks of latent variables to decode into slices of a volume. We also introduce a novel evaluation method for generated volumes that quantifies how well their segmentations match those of true brain anatomy. We demonstrate that our proposed model is competitive in generating high quality volumes at high resolutions according to both traditional metrics and our proposed evaluation.
Query-adaptive Video Summarization via Quality-aware Relevance Estimation
Sep 28, 2017
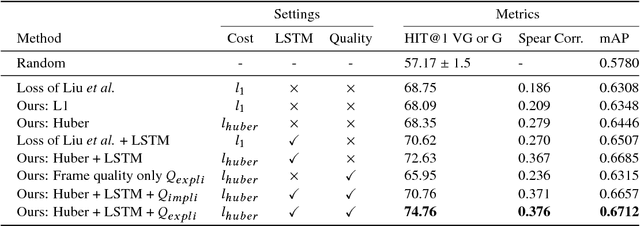
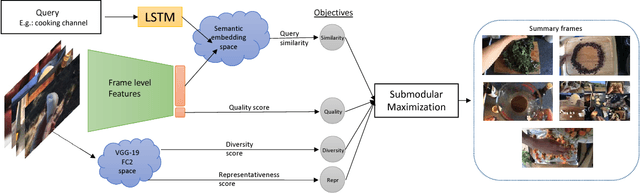
Although the problem of automatic video summarization has recently received a lot of attention, the problem of creating a video summary that also highlights elements relevant to a search query has been less studied. We address this problem by posing query-relevant summarization as a video frame subset selection problem, which lets us optimise for summaries which are simultaneously diverse, representative of the entire video, and relevant to a text query. We quantify relevance by measuring the distance between frames and queries in a common textual-visual semantic embedding space induced by a neural network. In addition, we extend the model to capture query-independent properties, such as frame quality. We compare our method against previous state of the art on textual-visual embeddings for thumbnail selection and show that our model outperforms them on relevance prediction. Furthermore, we introduce a new dataset, annotated with diversity and query-specific relevance labels. On this dataset, we train and test our complete model for video summarization and show that it outperforms standard baselines such as Maximal Marginal Relevance.
Do Deep Neural Networks Suffer from Crowding?
Jun 26, 2017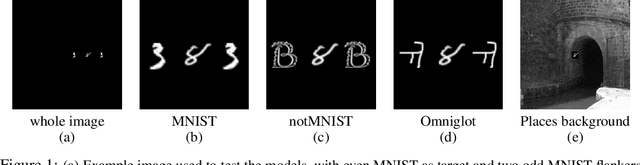
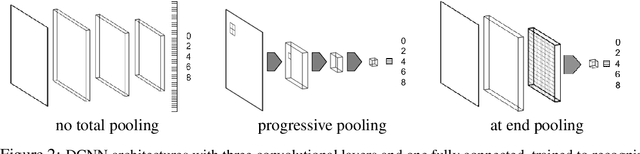
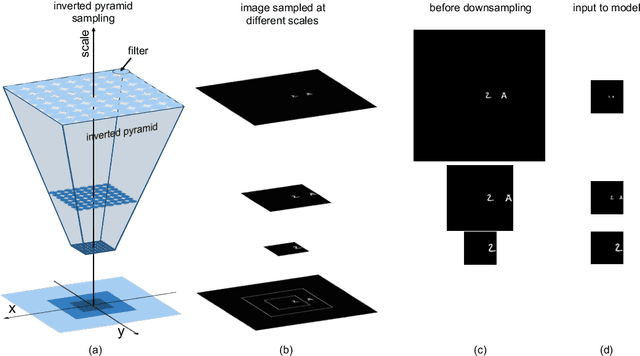
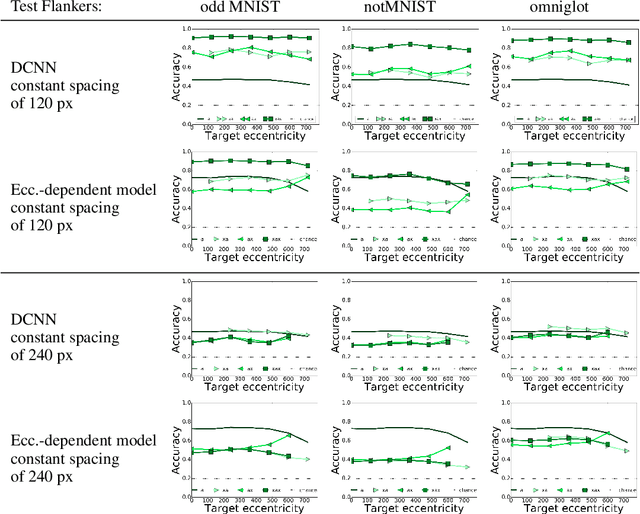
Crowding is a visual effect suffered by humans, in which an object that can be recognized in isolation can no longer be recognized when other objects, called flankers, are placed close to it. In this work, we study the effect of crowding in artificial Deep Neural Networks for object recognition. We analyze both standard deep convolutional neural networks (DCNNs) as well as a new version of DCNNs which is 1) multi-scale and 2) with size of the convolution filters change depending on the eccentricity wrt to the center of fixation. Such networks, that we call eccentricity-dependent, are a computational model of the feedforward path of the primate visual cortex. Our results reveal that the eccentricity-dependent model, trained on target objects in isolation, can recognize such targets in the presence of flankers, if the targets are near the center of the image, whereas DCNNs cannot. Also, for all tested networks, when trained on targets in isolation, we find that recognition accuracy of the networks decreases the closer the flankers are to the target and the more flankers there are. We find that visual similarity between the target and flankers also plays a role and that pooling in early layers of the network leads to more crowding. Additionally, we show that incorporating the flankers into the images of the training set does not improve performance with crowding.