 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeo-UNet: A Geometrically Constrained Neural Framework for Clinical-Grade Lumen Segmentation in Intravascular Ultrasound
Aug 09, 2024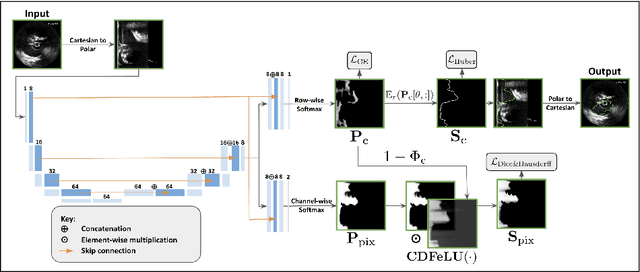
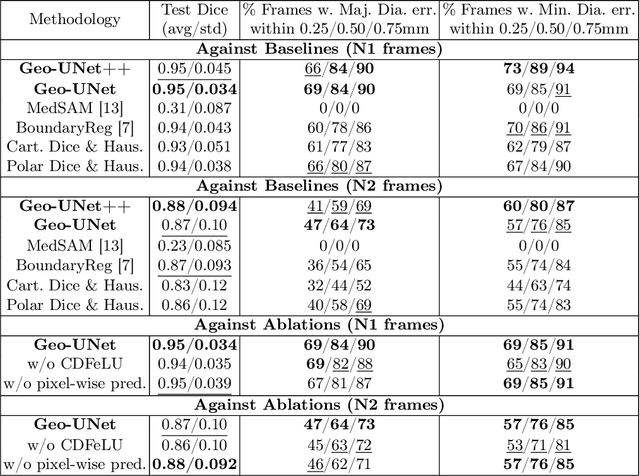
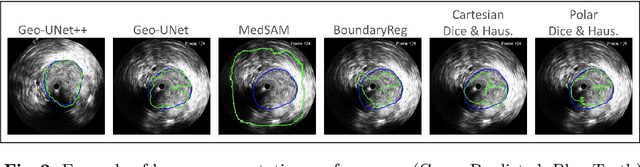
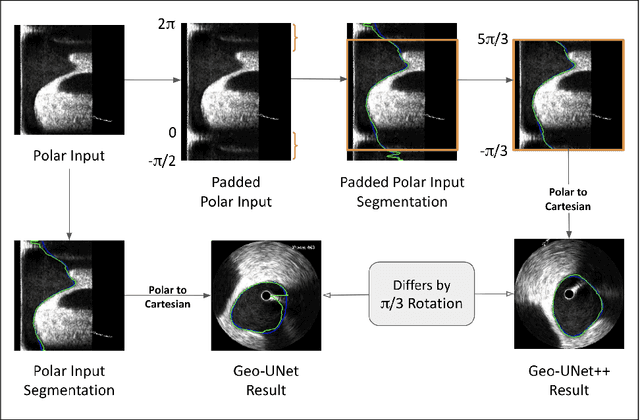
Precisely estimating lumen boundaries in intravascular ultrasound (IVUS) is needed for sizing interventional stents to treat deep vein thrombosis (DVT). Unfortunately, current segmentation networks like the UNet lack the precision needed for clinical adoption in IVUS workflows. This arises due to the difficulty of automatically learning accurate lumen contour from limited training data while accounting for the radial geometry of IVUS imaging. We propose the Geo-UNet framework to address these issues via a design informed by the geometry of the lumen contour segmentation task. We first convert the input data and segmentation targets from Cartesian to polar coordinates. Starting from a convUNet feature extractor, we propose a two-task setup, one for conventional pixel-wise labeling and the other for single boundary lumen-contour localization. We directly combine the two predictions by passing the predicted lumen contour through a new activation (named CDFeLU) to filter out spurious pixel-wise predictions. Our unified loss function carefully balances area-based, distance-based, and contour-based penalties to provide near clinical-grade generalization in unseen patient data. We also introduce a lightweight, inference-time technique to enhance segmentation smoothness. The efficacy of our framework on a venous IVUS dataset is shown against state-of-the-art models.
Consistency Regularization Improves Placenta Segmentation in Fetal EPI MRI Time Series
Oct 16, 2023The placenta plays a crucial role in fetal development. Automated 3D placenta segmentation from fetal EPI MRI holds promise for advancing prenatal care. This paper proposes an effective semi-supervised learning method for improving placenta segmentation in fetal EPI MRI time series. We employ consistency regularization loss that promotes consistency under spatial transformation of the same image and temporal consistency across nearby images in a time series. The experimental results show that the method improves the overall segmentation accuracy and provides better performance for outliers and hard samples. The evaluation also indicates that our method improves the temporal coherency of the prediction, which could lead to more accurate computation of temporal placental biomarkers. This work contributes to the study of the placenta and prenatal clinical decision-making. Code is available at https://github.com/firstmover/cr-seg.
Boundary-weighted logit consistency improves calibration of segmentation networks
Jul 16, 2023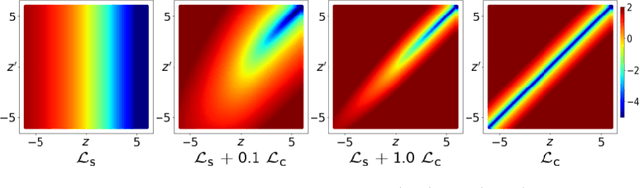
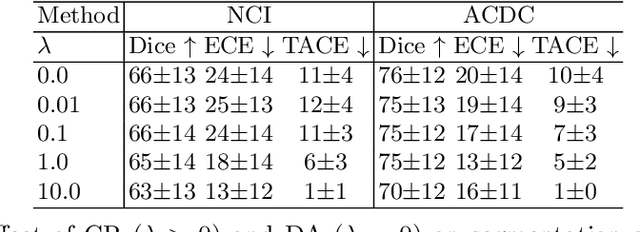

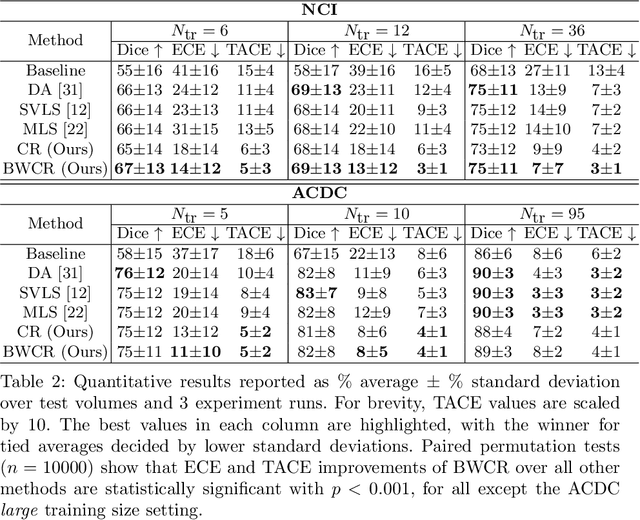
Neural network prediction probabilities and accuracy are often only weakly-correlated. Inherent label ambiguity in training data for image segmentation aggravates such miscalibration. We show that logit consistency across stochastic transformations acts as a spatially varying regularizer that prevents overconfident predictions at pixels with ambiguous labels. Our boundary-weighted extension of this regularizer provides state-of-the-art calibration for prostate and heart MRI segmentation.
A Field of Experts Prior for Adapting Neural Networks at Test Time
Feb 10, 2022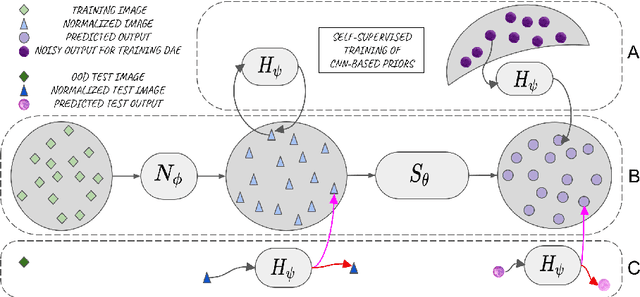
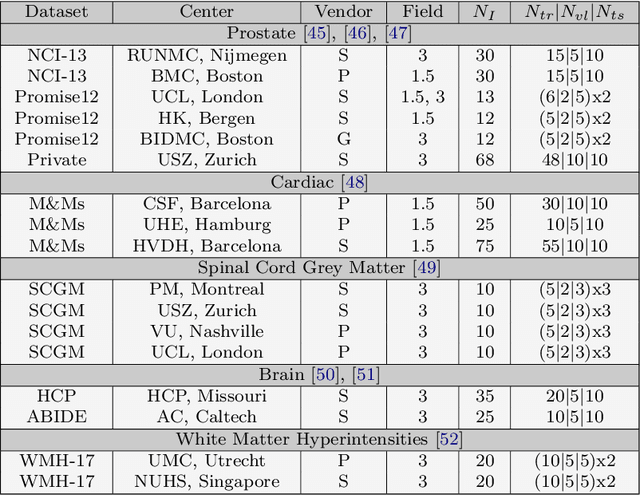
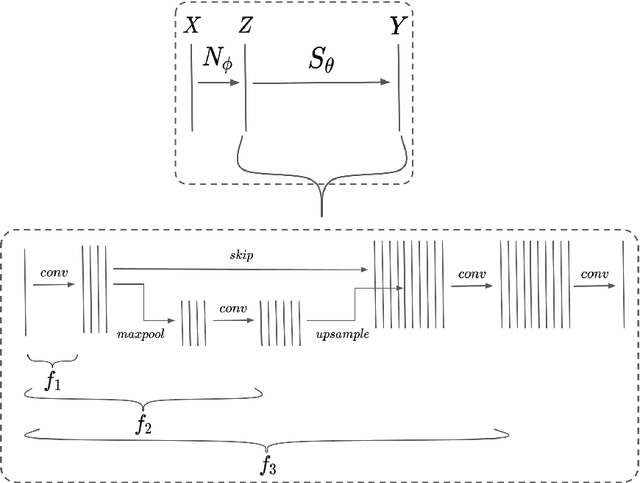
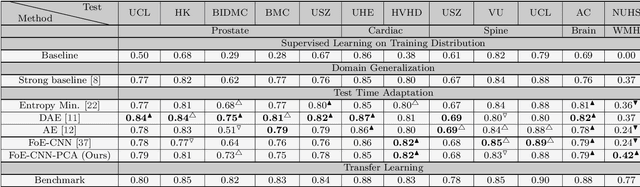
Performance of convolutional neural networks (CNNs) in image analysis tasks is often marred in the presence of acquisition-related distribution shifts between training and test images. Recently, it has been proposed to tackle this problem by fine-tuning trained CNNs for each test image. Such test-time-adaptation (TTA) is a promising and practical strategy for improving robustness to distribution shifts as it requires neither data sharing between institutions nor annotating additional data. Previous TTA methods use a helper model to increase similarity between outputs and/or features extracted from a test image with those of the training images. Such helpers, which are typically modeled using CNNs, can be task-specific and themselves vulnerable to distribution shifts in their inputs. To overcome these problems, we propose to carry out TTA by matching the feature distributions of test and training images, as modelled by a field-of-experts (FoE) prior. FoEs model complicated probability distributions as products of many simpler expert distributions. We use 1D marginal distributions of a trained task CNN's features as experts in the FoE model. Further, we compute principal components of patches of the task CNN's features, and consider the distributions of PCA loadings as additional experts. We validate the method on 5 MRI segmentation tasks (healthy tissues in 4 anatomical regions and lesions in 1 one anatomy), using data from 17 clinics, and on a MRI registration task, using data from 3 clinics. We find that the proposed FoE-based TTA is generically applicable in multiple tasks, and outperforms all previous TTA methods for lesion segmentation. For healthy tissue segmentation, the proposed method outperforms other task-agnostic methods, but a previous TTA method which is specifically designed for segmentation performs the best for most of the tested datasets. Our code is publicly available.
Local contrastive loss with pseudo-label based self-training for semi-supervised medical image segmentation
Dec 17, 2021
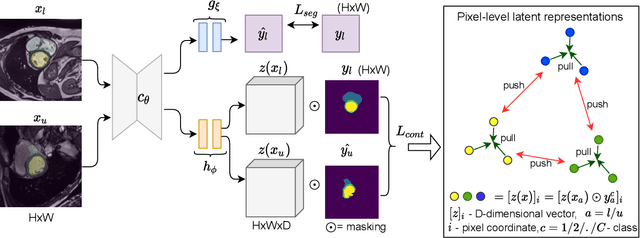
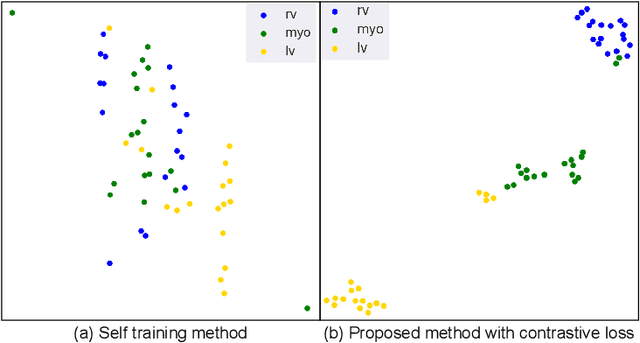

Supervised deep learning-based methods yield accurate results for medical image segmentation. However, they require large labeled datasets for this, and obtaining them is a laborious task that requires clinical expertise. Semi/self-supervised learning-based approaches address this limitation by exploiting unlabeled data along with limited annotated data. Recent self-supervised learning methods use contrastive loss to learn good global level representations from unlabeled images and achieve high performance in classification tasks on popular natural image datasets like ImageNet. In pixel-level prediction tasks such as segmentation, it is crucial to also learn good local level representations along with global representations to achieve better accuracy. However, the impact of the existing local contrastive loss-based methods remains limited for learning good local representations because similar and dissimilar local regions are defined based on random augmentations and spatial proximity; not based on the semantic label of local regions due to lack of large-scale expert annotations in the semi/self-supervised setting. In this paper, we propose a local contrastive loss to learn good pixel level features useful for segmentation by exploiting semantic label information obtained from pseudo-labels of unlabeled images alongside limited annotated images. In particular, we define the proposed loss to encourage similar representations for the pixels that have the same pseudo-label/ label while being dissimilar to the representation of pixels with different pseudo-label/label in the dataset. We perform pseudo-label based self-training and train the network by jointly optimizing the proposed contrastive loss on both labeled and unlabeled sets and segmentation loss on only the limited labeled set. We evaluated on three public cardiac and prostate datasets, and obtain high segmentation performance.
Semi-supervised Task-driven Data Augmentation for Medical Image Segmentation
Jul 09, 2020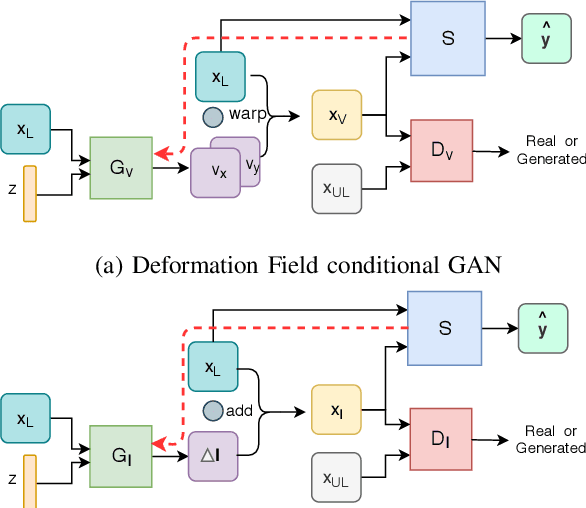
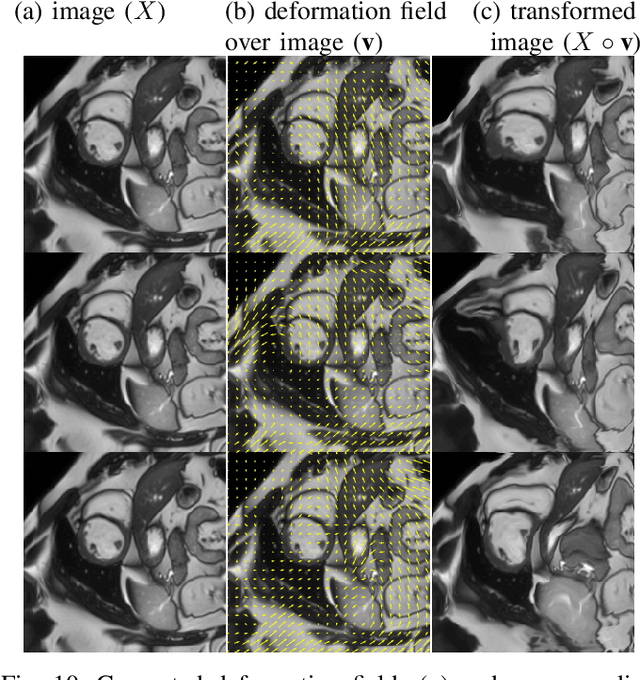
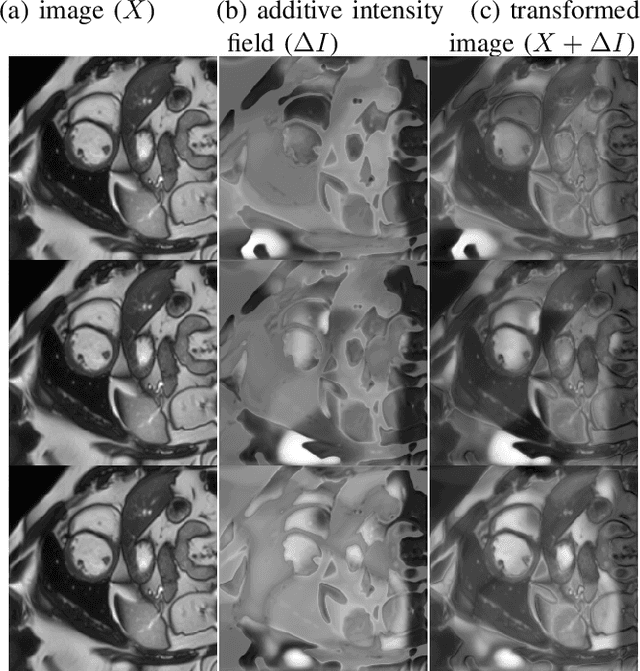
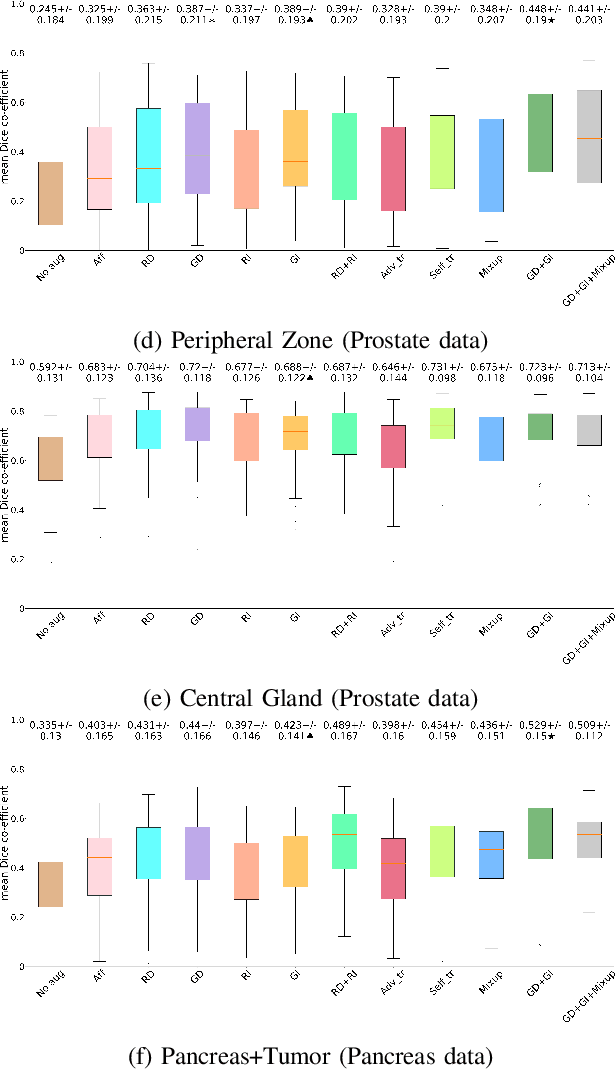
Supervised learning-based segmentation methods typically require a large number of annotated training data to generalize well at test time. In medical applications, curating such datasets is not a favourable option because acquiring a large number of annotated samples from experts is time-consuming and expensive. Consequently, numerous methods have been proposed in the literature for learning with limited annotated examples. Unfortunately, the proposed approaches in the literature have not yet yielded significant gains over random data augmentation for image segmentation, where random augmentations themselves do not yield high accuracy. In this work, we propose a novel task-driven data augmentation method for learning with limited labeled data where the synthetic data generator, is optimized for the segmentation task. The generator of the proposed method models intensity and shape variations using two sets of transformations, as additive intensity transformations and deformation fields. Both transformations are optimized using labeled as well as unlabeled examples in a semi-supervised framework. Our experiments on three medical datasets, namely cardic, prostate and pancreas, show that the proposed approach significantly outperforms standard augmentation and semi-supervised approaches for image segmentation in the limited annotation setting. The code is made publicly available at https://github.com/krishnabits001/task$\_$driven$\_$data$\_$augmentation.
Modelling the Distribution of 3D Brain MRI using a 2D Slice VAE
Jul 09, 2020



Probabilistic modelling has been an essential tool in medical image analysis, especially for analyzing brain Magnetic Resonance Images (MRI). Recent deep learning techniques for estimating high-dimensional distributions, in particular Variational Autoencoders (VAEs), opened up new avenues for probabilistic modeling. Modelling of volumetric data has remained a challenge, however, because constraints on available computation and training data make it difficult effectively leverage VAEs, which are well-developed for 2D images. We propose a method to model 3D MR brain volumes distribution by combining a 2D slice VAE with a Gaussian model that captures the relationships between slices. We do so by estimating the sample mean and covariance in the latent space of the 2D model over the slice direction. This combined model lets us sample new coherent stacks of latent variables to decode into slices of a volume. We also introduce a novel evaluation method for generated volumes that quantifies how well their segmentations match those of true brain anatomy. We demonstrate that our proposed model is competitive in generating high quality volumes at high resolutions according to both traditional metrics and our proposed evaluation.
Contrastive learning of global and local features for medical image segmentation with limited annotations
Jun 18, 2020
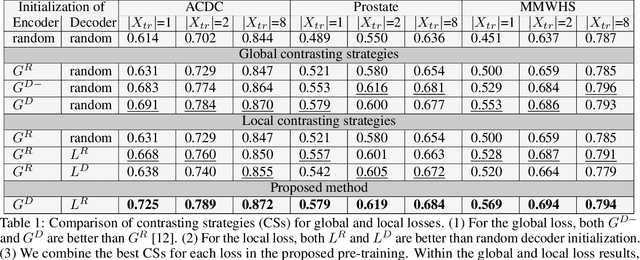

A key requirement for the success of supervised deep learning is a large labeled dataset - a condition that is difficult to meet in medical image analysis. Self-supervised learning (SSL) can help in this regard by providing a strategy to pre-train a neural network with unlabeled data, followed by fine-tuning for a downstream task with limited annotations. Contrastive learning, a particular variant of SSL, is a powerful technique for learning image-level representations. In this work, we propose strategies for extending the contrastive learning framework for segmentation of volumetric medical images in the semi-supervised setting with limited annotations, by leveraging domain-specific and problem-specific cues. Specifically, we propose (1) novel contrasting strategies that leverage structural similarity across volumetric medical images (domain-specific cue) and (2) a local version of the contrastive loss to learn distinctive representations of local regions that are useful for per-pixel segmentation (problem-specific cue). We carry out an extensive evaluation on three Magnetic Resonance Imaging (MRI) datasets. In the limited annotation setting, the proposed method yields substantial improvements compared to other self-supervision and semi-supervised learning techniques. When combined with a simple data augmentation technique, the proposed method reaches within 8% of benchmark performance using only two labeled MRI volumes for training, corresponding to only 4% (for ACDC) of the training data used to train the benchmark.
Test-Time Adaptable Neural Networks for Robust Medical Image Segmentation
Apr 10, 2020



Convolutional Neural Networks (CNNs) work very well for supervised learning problems when the training dataset is representative of the variations expected to be encountered at test time. In medical image segmentation, this premise is violated when there is a mismatch between training and test images in terms of their acquisition details, such as the scanner model or the protocol. Remarkable performance degradation of CNNs in this scenario is well documented in the literature. To address this problem, we design the segmentation CNN as a concatenation of two sub-networks: a relatively shallow image normalization CNN, followed by a deep CNN that segments the normalized image. We train both these sub-networks using a training dataset, consisting of annotated images from a particular scanner and protocol setting. Now, at test time, we adapt the image normalization sub-network for each test image, guided by an implicit prior on the predicted segmentation labels. We employ an independently trained denoising autoencoder (DAE) in order to model such an implicit prior on plausible anatomical segmentation labels. We validate the proposed idea on multi-center Magnetic Resonance imaging datasets of three anatomies: brain, heart and prostate. The proposed test-time adaptation consistently provides performance improvement, demonstrating the promise and generality of the approach. Being agnostic to the architecture of the deep CNN, the second sub-network, the proposed design can be utilized with any segmentation network to increase robustness to variations in imaging scanners and protocols.
Semi-Supervised and Task-Driven Data Augmentation
Feb 28, 2019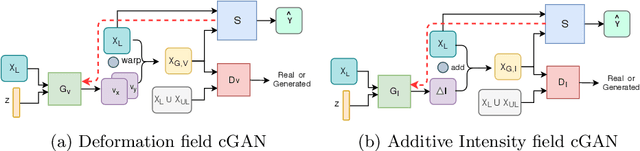
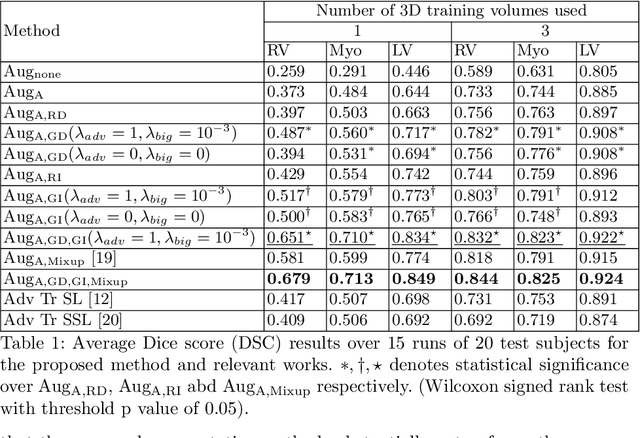
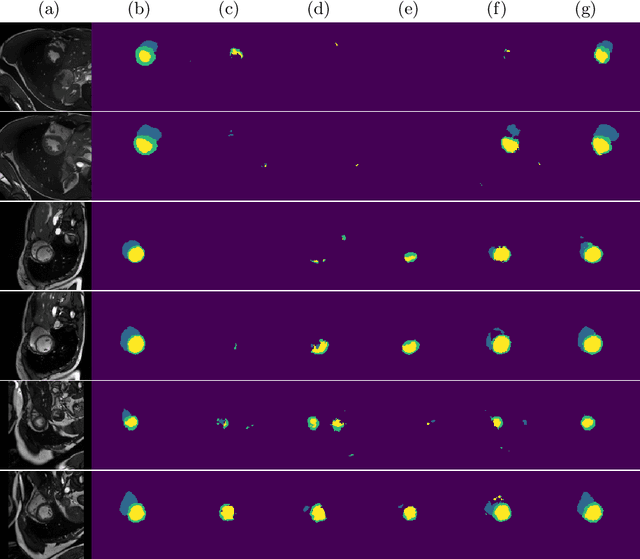
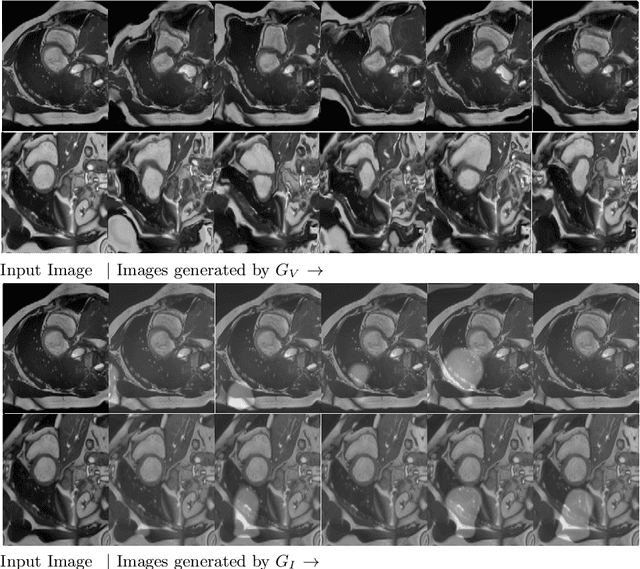
Supervised deep learning methods for segmentation require large amounts of labelled training data, without which they are prone to overfitting, not generalizing well to unseen images. In practice, obtaining a large number of annotations from clinical experts is expensive and time-consuming. One way to address scarcity of annotated examples is data augmentation using random spatial and intensity transformations. Recently, it has been proposed to use generative models to synthesize realistic training examples, complementing the random augmentation. So far, these methods have yielded limited gains over the random augmentation. However, there is potential to improve the approach by (i) explicitly modeling deformation fields (non-affine spatial transformation) and intensity transformations and (ii) leveraging unlabelled data during the generative process. With this motivation, we propose a novel task-driven data augmentation method where to synthesize new training examples, a generative network explicitly models and applies deformation fields and additive intensity masks on existing labelled data, modeling shape and intensity variations, respectively. Crucially, the generative model is optimized to be conducive to the task, in this case segmentation, and constrained to match the distribution of images observed from labelled and unlabelled samples. Furthermore, explicit modeling of deformation fields allow synthesizing segmentation masks and images in exact correspondence by simply applying the generated transformation to an input image and the corresponding annotation. Our experiments on cardiac magnetic resonance images (MRI) showed that, for the task of segmentation in small training data scenarios, the proposed method substantially outperforms conventional augmentation techniques.