 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-adaptive Video Summarization via Quality-aware Relevance Estimation
Paper and Code
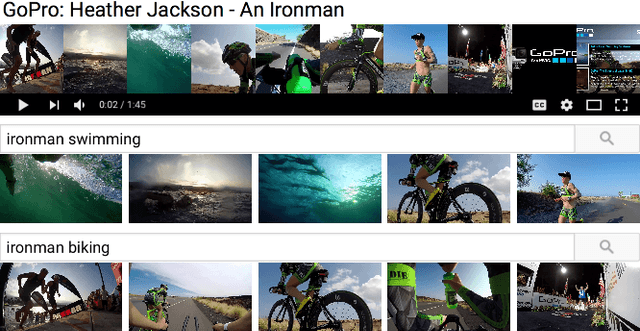
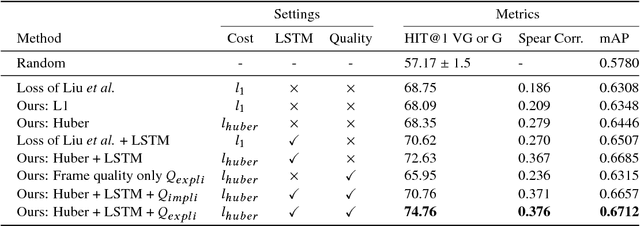
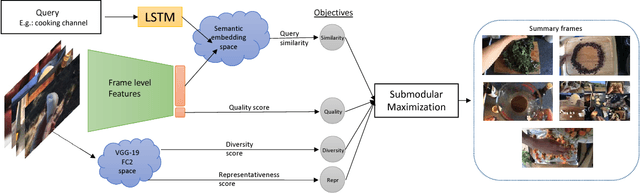
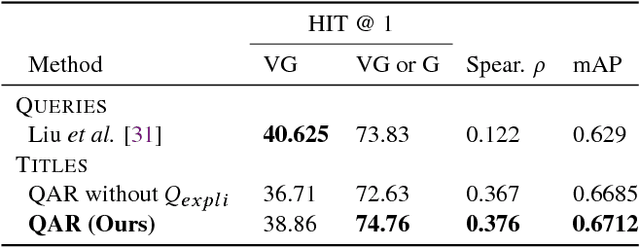
Although the problem of automatic video summarization has recently received a lot of attention, the problem of creating a video summary that also highlights elements relevant to a search query has been less studied. We address this problem by posing query-relevant summarization as a video frame subset selection problem, which lets us optimise for summaries which are simultaneously diverse, representative of the entire video, and relevant to a text query. We quantify relevance by measuring the distance between frames and queries in a common textual-visual semantic embedding space induced by a neural network. In addition, we extend the model to capture query-independent properties, such as frame quality. We compare our method against previous state of the art on textual-visual embeddings for thumbnail selection and show that our model outperforms them on relevance prediction. Furthermore, we introduce a new dataset, annotated with diversity and query-specific relevance labels. On this dataset, we train and test our complete model for video summarization and show that it outperforms standard baselines such as Maximal Marginal Relevance.