 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Estimation of Fingertip Pressure on Diverse Surfaces using Easily Captured Data
Paper and Code
Jan 05, 2023


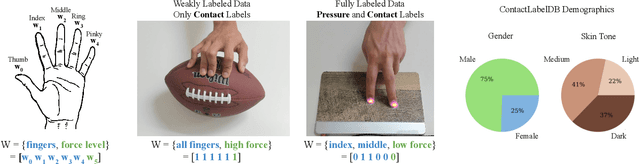
Prior research has shown that deep models can estimate the pressure applied by a hand to a surface based on a single RGB image. Training these models requires high-resolution pressure measurements that are difficult to obtain with physical sensors. Additionally, even experts cannot reliably annotate pressure from images. Thus, data collection is a critical barrier to generalization and improved performance. We present a novel approach that enables training data to be efficiently captured from unmodified surfaces with only an RGB camera and a cooperative participant. Our key insight is that people can be prompted to perform actions that correspond with categorical labels (contact labels) describing contact pressure, such as using a specific fingertip to make low-force contact. We present ContactLabelNet, which visually estimates pressure applied by fingertips. With the use of contact labels, ContactLabelNet achieves improved performance, generalizes to novel surfaces, and outperforms models from prior work.