 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Parallel Scaling: Aggregating Diverse Frame Subsets for VideoLLMs
Sep 09, 2025



Video Large Language Models (VideoLLMs) face a critical bottleneck: increasing the number of input frames to capture fine-grained temporal detail leads to prohibitive computational costs and performance degradation from long context lengths. We introduce Video Parallel Scaling (VPS), an inference-time method that expands a model's perceptual bandwidth without increasing its context window. VPS operates by running multiple parallel inference streams, each processing a unique, disjoint subset of the video's frames. By aggregating the output probabilities from these complementary streams, VPS integrates a richer set of visual information than is possible with a single pass. We theoretically show that this approach effectively contracts the Chinchilla scaling law by leveraging uncorrelated visual evidence, thereby improving performance without additional training. Extensive experiments across various model architectures and scales (2B-32B) on benchmarks such as Video-MME and EventHallusion demonstrate that VPS consistently and significantly improves performance. It scales more favorably than other parallel alternatives (e.g. Self-consistency) and is complementary to other decoding strategies, offering a memory-efficient and robust framework for enhancing the temporal reasoning capabilities of VideoLLMs.
Hybrid Semantic-Complementary Transmission for High-Fidelity Image Reconstruction
Jul 23, 2025Recent advances in semantic communication (SC) have introduced neural network (NN)-based transceivers that convey semantic representation (SR) of signals such as images. However, these NNs are trained over diverse image distributions and thus often fail to reconstruct fine-grained image-specific details. To overcome this limited reconstruction fidelity, we propose an extended SC framework, hybrid semantic communication (HSC), which supplements SR with complementary representation (CR) capturing residual image-specific information. The CR is constructed at the transmitter, and is combined with the actual SC outcome at the receiver to yield a high-fidelity recomposed image. While the transmission load of SR is fixed due to its NN-based structure, the load of CR can be flexibly adjusted to achieve a desirable fidelity. This controllability directly influences the final reconstruction error, for which we derive a closed-form expression and the corresponding optimal CR. Simulation results demonstrate that HSC substantially reduces MSE compared to the baseline SC without CR transmission across various channels and NN architectures.
VideoRFSplat: Direct Scene-Level Text-to-3D Gaussian Splatting Generation with Flexible Pose and Multi-View Joint Modeling
Mar 20, 2025We propose VideoRFSplat, a direct text-to-3D model leveraging a video generation model to generate realistic 3D Gaussian Splatting (3DGS) for unbounded real-world scenes. To generate diverse camera poses and unbounded spatial extent of real-world scenes, while ensuring generalization to arbitrary text prompts, previous methods fine-tune 2D generative models to jointly model camera poses and multi-view images. However, these methods suffer from instability when extending 2D generative models to joint modeling due to the modality gap, which necessitates additional models to stabilize training and inference. In this work, we propose an architecture and a sampling strategy to jointly model multi-view images and camera poses when fine-tuning a video generation model. Our core idea is a dual-stream architecture that attaches a dedicated pose generation model alongside a pre-trained video generation model via communication blocks, generating multi-view images and camera poses through separate streams. This design reduces interference between the pose and image modalities. Additionally, we propose an asynchronous sampling strategy that denoises camera poses faster than multi-view images, allowing rapidly denoised poses to condition multi-view generation, reducing mutual ambiguity and enhancing cross-modal consistency. Trained on multiple large-scale real-world datasets (RealEstate10K, MVImgNet, DL3DV-10K, ACID), VideoRFSplat outperforms existing text-to-3D direct generation methods that heavily depend on post-hoc refinement via score distillation sampling, achieving superior results without such refinement.
SteerX: Creating Any Camera-Free 3D and 4D Scenes with Geometric Steering
Mar 15, 2025



Recent progress in 3D/4D scene generation emphasizes the importance of physical alignment throughout video generation and scene reconstruction. However, existing methods improve the alignment separately at each stage, making it difficult to manage subtle misalignments arising from another stage. Here, we present SteerX, a zero-shot inference-time steering method that unifies scene reconstruction into the generation process, tilting data distributions toward better geometric alignment. To this end, we introduce two geometric reward functions for 3D/4D scene generation by using pose-free feed-forward scene reconstruction models. Through extensive experiments, we demonstrate the effectiveness of SteerX in improving 3D/4D scene generation.
Optical-Flow Guided Prompt Optimization for Coherent Video Generation
Nov 23, 2024While text-to-video diffusion models have made significant strides, many still face challenges in generating videos with temporal consistency. Within diffusion frameworks, guidance techniques have proven effective in enhancing output quality during inference; however, applying these methods to video diffusion models introduces additional complexity of handling computations across entire sequences. To address this, we propose a novel framework called MotionPrompt that guides the video generation process via optical flow. Specifically, we train a discriminator to distinguish optical flow between random pairs of frames from real videos and generated ones. Given that prompts can influence the entire video, we optimize learnable token embeddings during reverse sampling steps by using gradients from a trained discriminator applied to random frame pairs. This approach allows our method to generate visually coherent video sequences that closely reflect natural motion dynamics, without compromising the fidelity of the generated content. We demonstrate the effectiveness of our approach across various models.
Privacy-Preserving Split Learning with Vision Transformers using Patch-Wise Random and Noisy CutMix
Aug 02, 2024



In computer vision, the vision transformer (ViT) has increasingly superseded the convolutional neural network (CNN) for improved accuracy and robustness. However, ViT's large model sizes and high sample complexity make it difficult to train on resource-constrained edge devices. Split learning (SL) emerges as a viable solution, leveraging server-side resources to train ViTs while utilizing private data from distributed devices. However, SL requires additional information exchange for weight updates between the device and the server, which can be exposed to various attacks on private training data. To mitigate the risk of data breaches in classification tasks, inspired from the CutMix regularization, we propose a novel privacy-preserving SL framework that injects Gaussian noise into smashed data and mixes randomly chosen patches of smashed data across clients, coined DP-CutMixSL. Our analysis demonstrates that DP-CutMixSL is a differentially private (DP) mechanism that strengthens privacy protection against membership inference attacks during forward propagation. Through simulations, we show that DP-CutMixSL improves privacy protection against membership inference attacks, reconstruction attacks, and label inference attacks, while also improving accuracy compared to DP-SL and DP-MixSL.
CFG++: Manifold-constrained Classifier Free Guidance for Diffusion Models
Jun 12, 2024


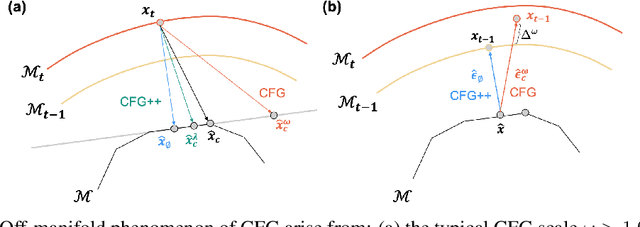
Classifier-free guidance (CFG) is a fundamental tool in modern diffusion models for text-guided generation. Although effective, CFG has notable drawbacks. For instance, DDIM with CFG lacks invertibility, complicating image editing; furthermore, high guidance scales, essential for high-quality outputs, frequently result in issues like mode collapse. Contrary to the widespread belief that these are inherent limitations of diffusion models, this paper reveals that the problems actually stem from the off-manifold phenomenon associated with CFG, rather than the diffusion models themselves. More specifically, inspired by the recent advancements of diffusion model-based inverse problem solvers (DIS), we reformulate text-guidance as an inverse problem with a text-conditioned score matching loss, and develop CFG++, a novel approach that tackles the off-manifold challenges inherent in traditional CFG. CFG++ features a surprisingly simple fix to CFG, yet it offers significant improvements, including better sample quality for text-to-image generation, invertibility, smaller guidance scales, reduced mode collapse, etc. Furthermore, CFG++ enables seamless interpolation between unconditional and conditional sampling at lower guidance scales, consistently outperforming traditional CFG at all scales. Experimental results confirm that our method significantly enhances performance in text-to-image generation, DDIM inversion, editing, and solving inverse problems, suggesting a wide-ranging impact and potential applications in various fields that utilize text guidance. Project Page: https://cfgpp-diffusion.github.io/.
Contrastive Denoising Score for Text-guided Latent Diffusion Image Editing
Nov 30, 2023



With the remarkable advent of text-to-image diffusion models, image editing methods have become more diverse and continue to evolve. A promising recent approach in this realm is Delta Denoising Score (DDS) - an image editing technique based on Score Distillation Sampling (SDS) framework that leverages the rich generative prior of text-to-image diffusion models. However, relying solely on the difference between scoring functions is insufficient for preserving specific structural elements from the original image, a crucial aspect of image editing. Inspired by the similarity and importance differences between DDS and the contrastive learning for unpaired image-to-image translation (CUT), here we present an embarrassingly simple yet very powerful modification of DDS, called Contrastive Denoising Score (CDS), for latent diffusion models (LDM). Specifically, to enforce structural correspondence between the input and output while maintaining the controllability of contents, we introduce a straightforward approach to regulate structural consistency using CUT loss within the DDS framework. To calculate this loss, instead of employing auxiliary networks, we utilize the intermediate features of LDM, in particular, those from the self-attention layers, which possesses rich spatial information. Our approach enables zero-shot image-to-image translation and neural radiance field (NeRF) editing, achieving a well-balanced interplay between maintaining the structural details and transforming content. Qualitative results and comparisons demonstrates the effectiveness of our proposed method. Project page with code is available at https://hyelinnam.github.io/CDS/.
Language-Oriented Communication with Semantic Coding and Knowledge Distillation for Text-to-Image Generation
Sep 20, 2023



By integrating recent advances in large language models (LLMs) and generative models into the emerging semantic communication (SC) paradigm, in this article we put forward to a novel framework of language-oriented semantic communication (LSC). In LSC, machines communicate using human language messages that can be interpreted and manipulated via natural language processing (NLP) techniques for SC efficiency. To demonstrate LSC's potential, we introduce three innovative algorithms: 1) semantic source coding (SSC) which compresses a text prompt into its key head words capturing the prompt's syntactic essence while maintaining their appearance order to keep the prompt's context; 2) semantic channel coding (SCC) that improves robustness against errors by substituting head words with their lenghthier synonyms; and 3) semantic knowledge distillation (SKD) that produces listener-customized prompts via in-context learning the listener's language style. In a communication task for progressive text-to-image generation, the proposed methods achieve higher perceptual similarities with fewer transmissions while enhancing robustness in noisy communication channels.
Sequential Semantic Generative Communication for Progressive Text-to-Image Generation
Sep 08, 2023This paper proposes new framework of communication system leveraging promising generation capabilities of multi-modal generative models. Regarding nowadays smart applications, successful communication can be made by conveying the perceptual meaning, which we set as text prompt. Text serves as a suitable semantic representation of image data as it has evolved to instruct an image or generate image through multi-modal techniques, by being interpreted in a manner similar to human cognition. Utilizing text can also reduce the overload compared to transmitting the intact data itself. The transmitter converts objective image to text through multi-model generation process and the receiver reconstructs the image using reverse process. Each word in the text sentence has each syntactic role, responsible for particular piece of information the text contains. For further efficiency in communication load, the transmitter sequentially sends words in priority of carrying the most information until reaches successful communication. Therefore, our primary focus is on the promising design of a communication system based on image-to-text transformation and the proposed schemes for sequentially transmitting word tokens. Our work is expected to pave a new road of utilizing state-of-the-art generative models to real communication systems