 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3BAT: Unsupervised Domain Adaptation for Multimodal Mobile Sensing with Multi-Branch Adversarial Training
Apr 26, 2024


Over the years, multimodal mobile sensing has been used extensively for inferences regarding health and well being, behavior, and context. However, a significant challenge hindering the widespread deployment of such models in real world scenarios is the issue of distribution shift. This is the phenomenon where the distribution of data in the training set differs from the distribution of data in the real world, the deployment environment. While extensively explored in computer vision and natural language processing, and while prior research in mobile sensing briefly addresses this concern, current work primarily focuses on models dealing with a single modality of data, such as audio or accelerometer readings, and consequently, there is little research on unsupervised domain adaptation when dealing with multimodal sensor data. To address this gap, we did extensive experiments with domain adversarial neural networks (DANN) showing that they can effectively handle distribution shifts in multimodal sensor data. Moreover, we proposed a novel improvement over DANN, called M3BAT, unsupervised domain adaptation for multimodal mobile sensing with multi-branch adversarial training, to account for the multimodality of sensor data during domain adaptation with multiple branches. Through extensive experiments conducted on two multimodal mobile sensing datasets, three inference tasks, and 14 source-target domain pairs, including both regression and classification, we demonstrate that our approach performs effectively on unseen domains. Compared to directly deploying a model trained in the source domain to the target domain, the model shows performance increases up to 12% AUC (area under the receiver operating characteristics curves) on classification tasks, and up to 0.13 MAE (mean absolute error) on regression tasks.
Examining European Press Coverage of the Covid-19 No-Vax Movement: An NLP Framework
Apr 29, 2023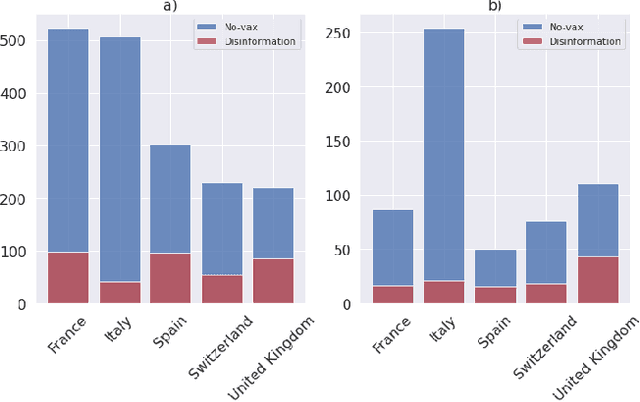
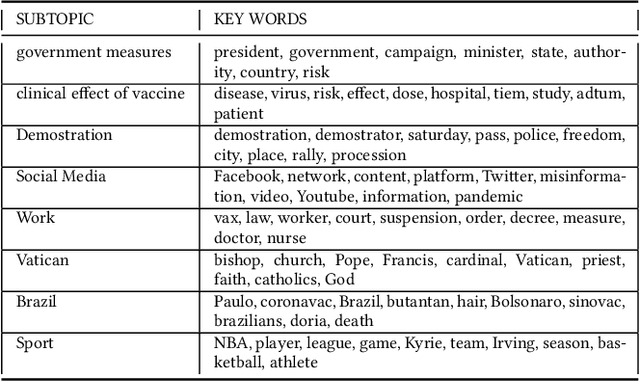

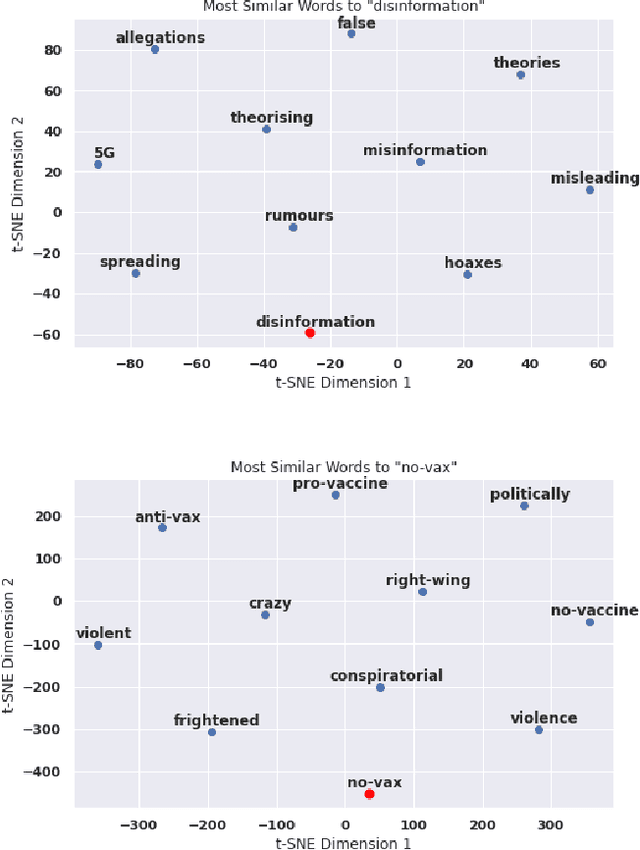
This paper examines how the European press dealt with the no-vax reactions against the Covid-19 vaccine and the dis- and misinformation associated with this movement. Using a curated dataset of 1786 articles from 19 European newspapers on the anti-vaccine movement over a period of 22 months in 2020-2021, we used Natural Language Processing techniques including topic modeling, sentiment analysis, semantic relationship with word embeddings, political analysis, named entity recognition, and semantic networks, to understand the specific role of the European traditional press in the disinformation ecosystem. The results of this multi-angle analysis demonstrate that the European well-established press actively opposed a variety of hoaxes mainly spread on social media, and was critical of the anti-vax trend, regardless of the political orientation of the newspaper. This confirms the relevance of studying the role of high-quality press in the disinformation ecosystem.
Framing the News:From Human Perception to Large Language Model Inferences
Apr 27, 2023



Identifying the frames of news is important to understand the articles' vision, intention, message to be conveyed, and which aspects of the news are emphasized. Framing is a widely studied concept in journalism, and has emerged as a new topic in computing, with the potential to automate processes and facilitate the work of journalism professionals. In this paper, we study this issue with articles related to the Covid-19 anti-vaccine movement. First, to understand the perspectives used to treat this theme, we developed a protocol for human labeling of frames for 1786 headlines of No-Vax movement articles of European newspapers from 5 countries. Headlines are key units in the written press, and worth of analysis as many people only read headlines (or use them to guide their decision for further reading.) Second, considering advances in Natural Language Processing (NLP) with large language models, we investigated two approaches for frame inference of news headlines: first with a GPT-3.5 fine-tuning approach, and second with GPT-3.5 prompt-engineering. Our work contributes to the study and analysis of the performance that these models have to facilitate journalistic tasks like classification of frames, while understanding whether the models are able to replicate human perception in the identification of these frames.
ProGAP: Progressive Graph Neural Networks with Differential Privacy Guarantees
Apr 18, 2023Graph Neural Networks (GNNs) have become a popular tool for learning on graphs, but their widespread use raises privacy concerns as graph data can contain personal or sensitive information. Differentially private GNN models have been recently proposed to preserve privacy while still allowing for effective learning over graph-structured datasets. However, achieving an ideal balance between accuracy and privacy in GNNs remains challenging due to the intrinsic structural connectivity of graphs. In this paper, we propose a new differentially private GNN called ProGAP that uses a progressive training scheme to improve such accuracy-privacy trade-offs. Combined with the aggregation perturbation technique to ensure differential privacy, ProGAP splits a GNN into a sequence of overlapping submodels that are trained progressively, expanding from the first submodel to the complete model. Specifically, each submodel is trained over the privately aggregated node embeddings learned and cached by the previous submodels, leading to an increased expressive power compared to previous approaches while limiting the incurred privacy costs. We formally prove that ProGAP ensures edge-level and node-level privacy guarantees for both training and inference stages, and evaluate its performance on benchmark graph datasets. Experimental results demonstrate that ProGAP can achieve up to 5%-10% higher accuracy than existing state-of-the-art differentially private GNNs.
Your Day in Your Pocket: Complex Activity Recognition from Smartphone Accelerometers
Jan 17, 2023



Human Activity Recognition (HAR) enables context-aware user experiences where mobile apps can alter content and interactions depending on user activities. Hence, smartphones have become valuable for HAR as they allow large, and diversified data collection. Although previous work in HAR managed to detect simple activities (i.e., sitting, walking, running) with good accuracy using inertial sensors (i.e., accelerometer), the recognition of complex daily activities remains an open problem, specially in remote work/study settings when people are more sedentary. Moreover, understanding the everyday activities of a person can support the creation of applications that aim to support their well-being. This paper investigates the recognition of complex activities exclusively using smartphone accelerometer data. We used a large smartphone sensing dataset collected from over 600 users in five countries during the pandemic and showed that deep learning-based, binary classification of eight complex activities (sleeping, eating, watching videos, online communication, attending a lecture, sports, shopping, studying) can be achieved with AUROC scores up to 0.76 with partially personalized models. This shows encouraging signs toward assessing complex activities only using phone accelerometer data in the post-pandemic world.
GAP: Differentially Private Graph Neural Networks with Aggregation Perturbation
Mar 02, 2022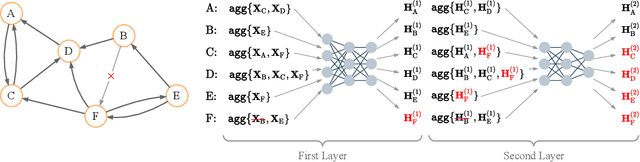

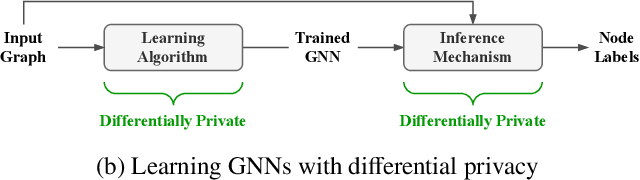

Graph Neural Networks (GNNs) are powerful models designed for graph data that learn node representation by recursively aggregating information from each node's local neighborhood. However, despite their state-of-the-art performance in predictive graph-based applications, recent studies have shown that GNNs can raise significant privacy concerns when graph data contain sensitive information. As a result, in this paper, we study the problem of learning GNNs with Differential Privacy (DP). We propose GAP, a novel differentially private GNN that safeguards the privacy of nodes and edges using aggregation perturbation, i.e., adding calibrated stochastic noise to the output of the GNN's aggregation function, which statistically obfuscates the presence of a single edge (edge-level privacy) or a single node and all its adjacent edges (node-level privacy). To circumvent the accumulation of privacy cost at every forward pass of the model, we tailor the GNN architecture to the specifics of private learning. In particular, we first precompute private aggregations by recursively applying neighborhood aggregation and perturbing the output of each aggregation step. Then, we privately train a deep neural network on the resulting perturbed aggregations for any node-wise classification task. A major advantage of GAP over previous approaches is that we guarantee edge-level and node-level DP not only for training, but also at inference time with no additional costs beyond the training's privacy budget. We theoretically analyze the formal privacy guarantees of GAP using R\'enyi DP. Empirical experiments conducted over three real-world graph datasets demonstrate that GAP achieves a favorable privacy-accuracy trade-off and significantly outperforms existing approaches.
When Differential Privacy Meets Graph Neural Networks
Jun 30, 2020
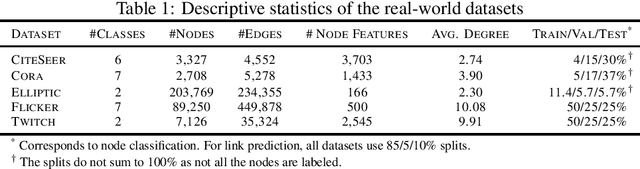

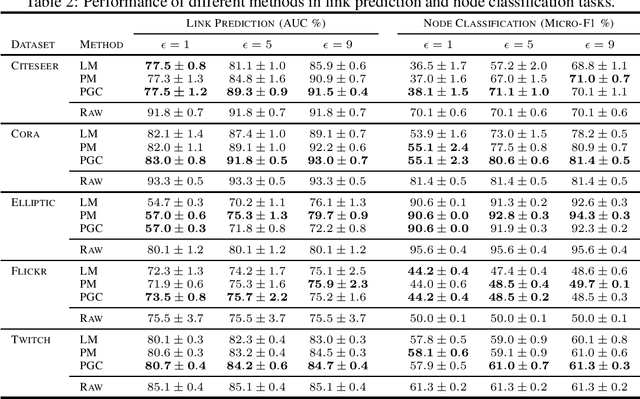
Graph Neural Networks have demonstrated superior performance in learning graph representations for several subsequent downstream inference tasks. However, learning over graph data types can raise privacy concerns when nodes represent people or human-related variables that involve personal information about individuals. Previous works have presented various techniques for privacy-preserving deep learning over non-relational data, such as image, audio, video, and text, but there is less work addressing the privacy issues involved in applying deep learning algorithms on graphs. As a result and for the first time, in this paper, we develop a privacy-preserving learning algorithm with formal privacy guarantees for Graph Convolutional Networks (GCNs) based on Local Differential Privacy (LDP) to tackle the problem of node-level privacy, where graph nodes have potentially sensitive features that need to be kept private, but they could be beneficial for learning rich node representations in a centralized learning setting. Specifically, we propose an LDP algorithm in which a central server can communicate with graph nodes to privately collect their data and estimate the graph convolution layer of a GCN. We then analyze the theoretical characteristics of the method and compare it with state-of-the-art mechanisms. Experimental results over real-world graph datasets demonstrate the effectiveness of the proposed method for both privacy-preserving node classification and link prediction tasks and verify our theoretical findings.