 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Media for Mental Health: Data, Methods, and Findings
Nov 11, 2025There is an increasing number of virtual communities and forums available on the web. With social media, people can freely communicate and share their thoughts, ask personal questions, and seek peer-support, especially those with conditions that are highly stigmatized, without revealing personal identity. We study the state-of-the-art research methodologies and findings on mental health challenges like depression, anxiety, suicidal thoughts, from the pervasive use of social media data. We also discuss how these novel thinking and approaches can help to raise awareness of mental health issues in an unprecedented way. Specifically, this chapter describes linguistic, visual, and emotional indicators expressed in user disclosures. The main goal of this chapter is to show how this new source of data can be tapped to improve medical practice, provide timely support, and influence government or policymakers. In the context of social media for mental health issues, this chapter categorizes social media data used, introduces different deployed machine learning, feature engineering, natural language processing, and surveys methods and outlines directions for future research.
Does Prompt Design Impact Quality of Data Imputation by LLMs?
Jun 04, 2025Generating realistic synthetic tabular data presents a critical challenge in machine learning. It adds another layer of complexity when this data contain class imbalance problems. This paper presents a novel token-aware data imputation method that leverages the in-context learning capabilities of large language models. This is achieved through the combination of a structured group-wise CSV-style prompting technique and the elimination of irrelevant contextual information in the input prompt. We test this approach with two class-imbalanced binary classification datasets and evaluate the effectiveness of imputation using classification-based evaluation metrics. The experimental results demonstrate that our approach significantly reduces the input prompt size while maintaining or improving imputation quality compared to our baseline prompt, especially for datasets that are of relatively smaller in size. The contributions of this presented work is two-fold -- 1) it sheds light on the importance of prompt design when leveraging LLMs for synthetic data generation and 2) it addresses a critical gap in LLM-based data imputation for class-imbalanced datasets with missing data by providing a practical solution within computational constraints. We hope that our work will foster further research and discussions about leveraging the incredible potential of LLMs and prompt engineering techniques for synthetic data generation.
Comfort Foods and Community Connectedness: Investigating Diet Change during COVID-19 Using YouTube Videos on Twitter
May 19, 2023



Unprecedented lockdowns at the start of the COVID-19 pandemic have drastically changed the routines of millions of people, potentially impacting important health-related behaviors. In this study, we use YouTube videos embedded in tweets about diet, exercise and fitness posted before and during COVID-19 to investigate the influence of the pandemic lockdowns on diet and nutrition. In particular, we examine the nutritional profile of the foods mentioned in the transcript, description and title of each video in terms of six macronutrients (protein, energy, fat, sodium, sugar, and saturated fat). These macronutrient values were further linked to demographics to assess if there are specific effects on those potentially having insufficient access to healthy sources of food. Interrupted time series analysis revealed a considerable shift in the aggregated macronutrient scores before and during COVID-19. In particular, whereas areas with lower incomes showed decrease in energy, fat, and saturated fat, those with higher percentage of African Americans showed an elevation in sodium. Word2Vec word similarities and odds ratio analysis suggested a shift from popular diets and lifestyle bloggers before the lockdowns to the interest in a variety of healthy foods, communal sharing of quick and easy recipes, as well as a new emphasis on comfort foods. To the best of our knowledge, this work is novel in terms of linking attention signals in tweets, content of videos, their nutrients profile, and aggregate demographics of the users. The insights made possible by this combination of resources are important for monitoring the secondary health effects of social distancing, and informing social programs designed to alleviate these effects.
Classification of Misinformation in New Articles using Natural Language Processing and a Recurrent Neural Network
Oct 24, 2022



This paper seeks to address the classification of misinformation in news articles using a Long Short Term Memory Recurrent Neural Network. Articles were taken from 2018; a year that was filled with reporters writing about President Donald Trump, Special Counsel Robert Mueller, the Fifa World Cup, and Russia. The model presented successfully classifies these articles with an accuracy score of 0.779944. We consider this to be successful because the model was trained on articles that included languages other than English as well as incomplete, or fragmented, articles.
Imperfect ImaGANation: Implications of GANs Exacerbating Biases on Facial Data Augmentation and Snapchat Selfie Lenses
Jan 26, 2020
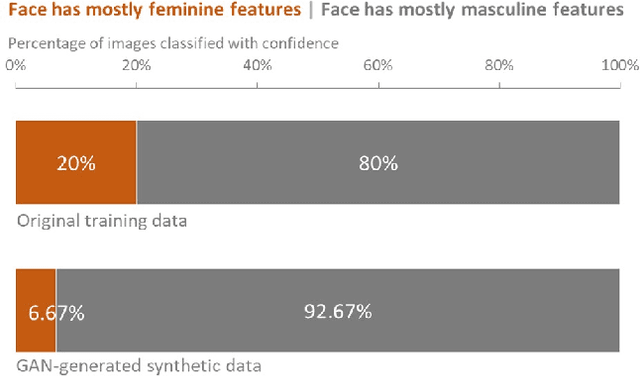
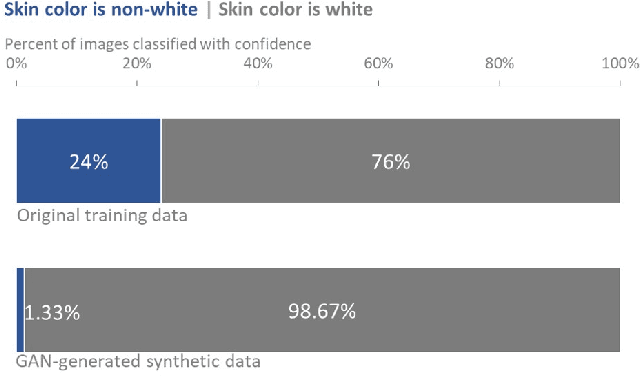
Recently, the use of synthetic data generated by GANs has become a popular method to do data augmentation for many applications. While practitioners celebrate this as an economical way to obtain synthetic data for training data-hungry machine learning models, it is not clear that they recognize the perils of such an augmentation technique when applied to an already-biased dataset. Although one expects GANs to replicate the distribution of the original data, in real-world settings with limited data and finite network capacity, GANs suffer from mode collapse. Especially when this data is coming from online social media platforms or the web which are never balanced. In this paper, we show that in settings where data exhibits bias along some axes (eg. gender, race), failure modes of Generative Adversarial Networks (GANs) exacerbate the biases in the generated data. More often than not, this bias is unavoidable; we empirically demonstrate that given input of a dataset of headshots of engineering faculty collected from 47 online university directory webpages in the United States is biased toward white males, a state-of-the-art (unconditional variant of) GAN "imagines" faces of synthetic engineering professors that have masculine facial features and white skin color (inferred using human studies and a state-of-the-art gender recognition system). We also conduct a preliminary case study to highlight how Snapchat's explosively popular "female" filter (widely accepted to use a conditional variant of GAN), ends up consistently lightening the skin tones in women of color when trying to make face images appear more feminine. Our study is meant to serve as a cautionary tale for the lay practitioners who may unknowingly increase the bias in their training data by using GAN-based augmentation techniques with web data and to showcase the dangers of using biased datasets for facial applications.
Imagining an Engineer: On GAN-Based Data Augmentation Perpetuating Biases
Nov 09, 2018


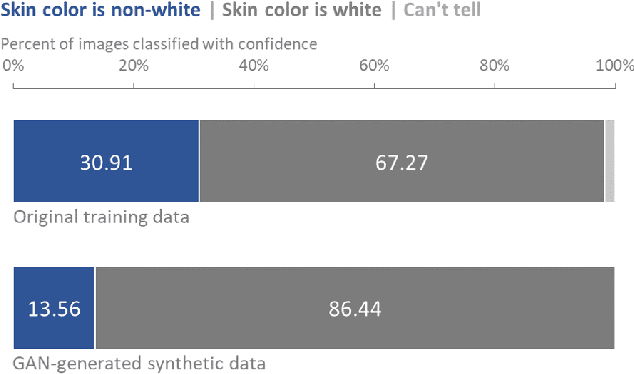
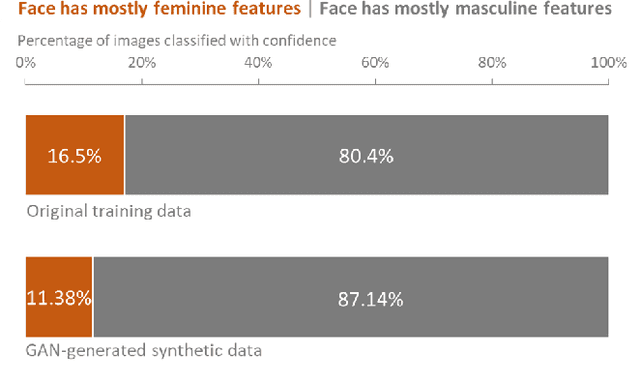
The use of synthetic data generated by Generative Adversarial Networks (GANs) has become quite a popular method to do data augmentation for many applications. While practitioners celebrate this as an economical way to get more synthetic data that can be used to train downstream classifiers, it is not clear that they recognize the inherent pitfalls of this technique. In this paper, we aim to exhort practitioners against deriving any false sense of security against data biases based on data augmentation. To drive this point home, we show that starting with a dataset consisting of head-shots of engineering researchers, GAN-based augmentation "imagines" synthetic engineers, most of whom have masculine features and white skin color (inferred from a human subject study conducted on Amazon Mechanical Turk). This demonstrates how biases inherent in the training data are reinforced, and sometimes even amplified, by GAN-based data augmentation; it should serve as a cautionary tale for the lay practitioners.
Tweeting AI: Perceptions of AI-Tweeters vs Expert AI-Tweeters
Sep 28, 2017


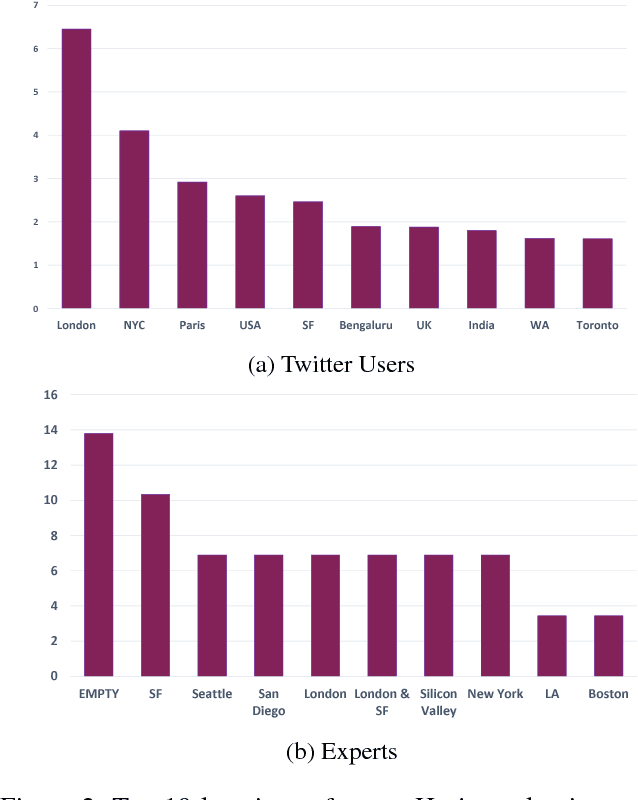
With the recent advancements in Artificial Intelligence (AI), various organizations and individuals started debating about the progress of AI as a blessing or a curse for the future of the society. This paper conducts an investigation on how the public perceives the progress of AI by utilizing the data shared on Twitter. Specifically, this paper performs a comparative analysis on the understanding of users from two categories -- general AI-Tweeters (AIT) and the expert AI-Tweeters (EAIT) who share posts about AI on Twitter. Our analysis revealed that users from both the categories express distinct emotions and interests towards AI. Users from both the categories regard AI as positive and are optimistic about the progress of AI but the experts are more negative than the general AI-Tweeters. Characterization of users manifested that `London' is the popular location of users from where they tweet about AI. Tweets posted by AIT are highly retweeted than posts made by EAIT that reveals greater diffusion of information from AIT.
Tweeting AI: Perceptions of Lay vs Expert Twitterati
Sep 25, 2017

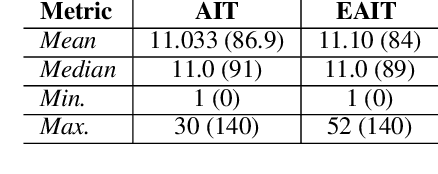
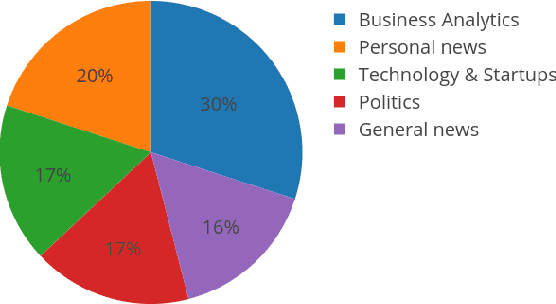
With the recent advancements in Artificial Intelligence (AI), various organizations and individuals are debating about the progress of AI as a blessing or a curse for the future of the society. This paper conducts an investigation on how the public perceives the progress of AI by utilizing the data shared on Twitter. Specifically, this paper performs a comparative analysis on the understanding of users belonging to two categories -- general AI-Tweeters (AIT) and expert AI-Tweeters (EAIT) who share posts about AI on Twitter. Our analysis revealed that users from both the categories express distinct emotions and interests towards AI. Users from both the categories regard AI as positive and are optimistic about the progress of AI but the experts are more negative than the general AI-Tweeters. Expert AI-Tweeters share relatively large percentage of tweets about their personal news compared to technical aspects of AI. However, the effects of automation on the future are of primary concern to AIT than to EAIT. When the expert category is sub-categorized, the emotion analysis revealed that students and industry professionals have more insights in their tweets about AI than academicians.