 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing the Truth with ConLLM for Detecting Multi-Modal Deepfakes
Jan 24, 2026The rapid rise of deepfake technology poses a severe threat to social and political stability by enabling hyper-realistic synthetic media capable of manipulating public perception. However, existing detection methods struggle with two core limitations: (1) modality fragmentation, which leads to poor generalization across diverse and adversarial deepfake modalities; and (2) shallow inter-modal reasoning, resulting in limited detection of fine-grained semantic inconsistencies. To address these, we propose ConLLM (Contrastive Learning with Large Language Models), a hybrid framework for robust multimodal deepfake detection. ConLLM employs a two-stage architecture: stage 1 uses Pre-Trained Models (PTMs) to extract modality-specific embeddings; stage 2 aligns these embeddings via contrastive learning to mitigate modality fragmentation, and refines them using LLM-based reasoning to address shallow inter-modal reasoning by capturing semantic inconsistencies. ConLLM demonstrates strong performance across audio, video, and audio-visual modalities. It reduces audio deepfake EER by up to 50%, improves video accuracy by up to 8%, and achieves approximately 9% accuracy gains in audio-visual tasks. Ablation studies confirm that PTM-based embeddings contribute 9%-10% consistent improvements across modalities.
Imperfect ImaGANation: Implications of GANs Exacerbating Biases on Facial Data Augmentation and Snapchat Selfie Lenses
Jan 26, 2020
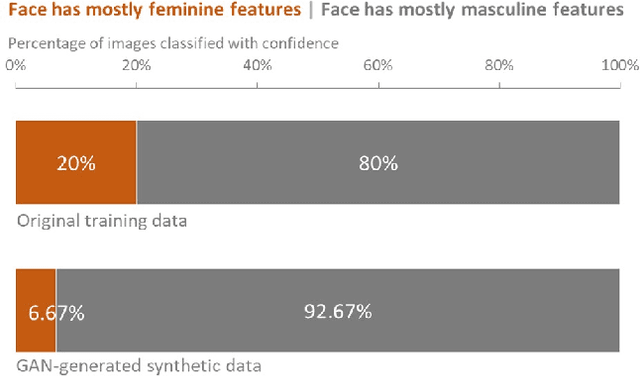
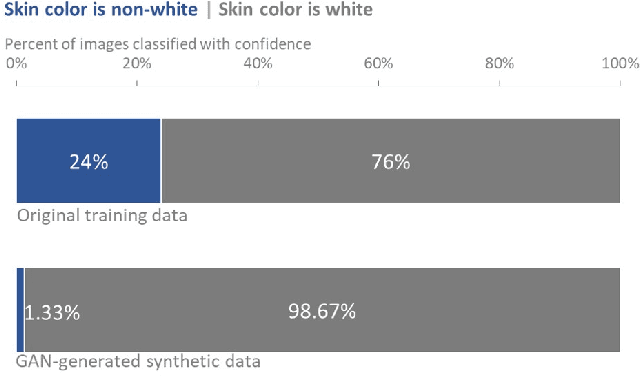
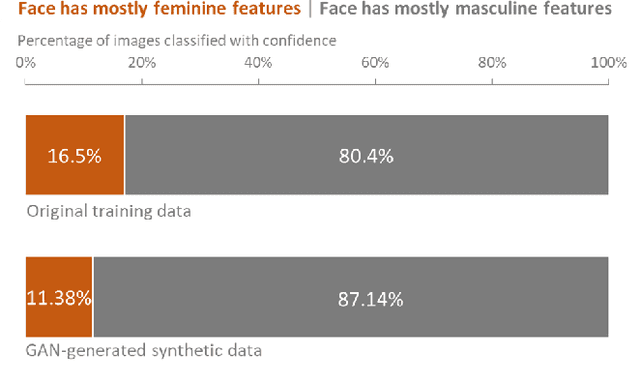
Recently, the use of synthetic data generated by GANs has become a popular method to do data augmentation for many applications. While practitioners celebrate this as an economical way to obtain synthetic data for training data-hungry machine learning models, it is not clear that they recognize the perils of such an augmentation technique when applied to an already-biased dataset. Although one expects GANs to replicate the distribution of the original data, in real-world settings with limited data and finite network capacity, GANs suffer from mode collapse. Especially when this data is coming from online social media platforms or the web which are never balanced. In this paper, we show that in settings where data exhibits bias along some axes (eg. gender, race), failure modes of Generative Adversarial Networks (GANs) exacerbate the biases in the generated data. More often than not, this bias is unavoidable; we empirically demonstrate that given input of a dataset of headshots of engineering faculty collected from 47 online university directory webpages in the United States is biased toward white males, a state-of-the-art (unconditional variant of) GAN "imagines" faces of synthetic engineering professors that have masculine facial features and white skin color (inferred using human studies and a state-of-the-art gender recognition system). We also conduct a preliminary case study to highlight how Snapchat's explosively popular "female" filter (widely accepted to use a conditional variant of GAN), ends up consistently lightening the skin tones in women of color when trying to make face images appear more feminine. Our study is meant to serve as a cautionary tale for the lay practitioners who may unknowingly increase the bias in their training data by using GAN-based augmentation techniques with web data and to showcase the dangers of using biased datasets for facial applications.
Imagining an Engineer: On GAN-Based Data Augmentation Perpetuating Biases
Nov 09, 2018


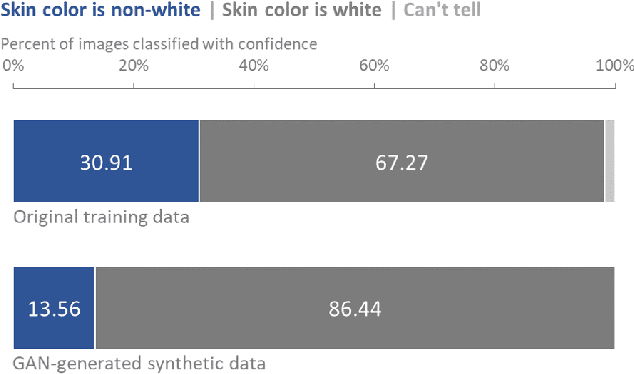
The use of synthetic data generated by Generative Adversarial Networks (GANs) has become quite a popular method to do data augmentation for many applications. While practitioners celebrate this as an economical way to get more synthetic data that can be used to train downstream classifiers, it is not clear that they recognize the inherent pitfalls of this technique. In this paper, we aim to exhort practitioners against deriving any false sense of security against data biases based on data augmentation. To drive this point home, we show that starting with a dataset consisting of head-shots of engineering researchers, GAN-based augmentation "imagines" synthetic engineers, most of whom have masculine features and white skin color (inferred from a human subject study conducted on Amazon Mechanical Turk). This demonstrates how biases inherent in the training data are reinforced, and sometimes even amplified, by GAN-based data augmentation; it should serve as a cautionary tale for the lay practitioners.