 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClusters are All You Need: Pre-Training the Tsetlin Machine with Semantic Clusters from Language Models for Interpretability
Jun 18, 2026Pre-trained language models such as BERT achieve strong text classification performance but lack transparency, limiting their use in high-stakes settings. The Tsetlin Machine (TM) offers fully interpretable, clause-based reasoning but captures little semantic information, and prior attempts to bridge the two rely on static word embeddings that miss contextual meaning. We propose a semantic pre-training framework that transfers knowledge from a pre-trained language model into a TM without using embeddings. Text samples are grouped into semantically coherent clusters with K-means or Top2Vec, and the resulting cluster-sample pairs pre-train a non-negated TM with enhanced Type I feedback. The TM thereby learns interpretable semantic keywords that are fine-tuned on downstream tasks. Across five datasets, our method substantially outperforms vanilla and embedding-based TMs and reaches performance competitive with BERT while remaining interpretable.
Trustworthy Agent Network: Trust in Agent Networks Must Be Baked In, Not Bolted On
May 18, 2026The rapid advancement of Large Language Models has given rise to autonomous LLM-based agents capable of complex reasoning and execution. As these agents transition from isolated operation to collaborative ecosystems, we witness the emergence of the Agent-to-Agent (A2A) network, a paradigm where heterogeneous agents autonomously coordinate to solve multi-step tasks. While these networks may offer better task performance compared to simply using one agent to complete the entire task, they introduce systemic vulnerabilities, such as adversarial composition, semantic misalignment, and cascading operational failures, that existing agent alignment techniques cannot address. In this vision paper, we argue that the trustworthiness of A2A networks cannot be fully guaranteed via retrofitting on existing protocols that are largely designed for individual agents. Rather, it must be architected from the very beginning of the A2A coordination framework. We present a comprehensive conceptual framework that situates trust in A2A systems through four design pillars.
Are Large Language Models Economically Viable for Industry Deployment?
Apr 21, 2026Generative AI-powered by Large Language Models (LLMs)-is increasingly deployed in industry across healthcare decision support, financial analytics, enterprise retrieval, and conversational automation, where reliability, efficiency, and cost control are critical. In such settings, models must satisfy strict constraints on energy, latency, and hardware utilization-not accuracy alone. Yet prevailing evaluation pipelines remain accuracy-centric, creating a Deployment-Evaluation Gap-the absence of operational and economic criteria in model assessment. To address this gap, we present EDGE-EVAL-a industry-oriented benchmarking framework that evaluates LLMs across their full lifecycle on legacy NVIDIA Tesla T4 GPUs. Benchmarking LLaMA and Qwen variants across three industrial tasks, we introduce five deployment metrics-Economic Break-Even (Nbreak), Intelligence-Per-Watt (IPW ), System Density (\r{ho}sys), Cold-Start Tax (Ctax), and Quantization Fidelity (Qret)-capturing profitability, energy efficiency, hardware scaling, serverless feasibility, and compression safety. Our results reveal a clear efficiency frontier-models in the <2B parameter class dominate larger baselines across economic and ecological dimensions. LLaMA-3.2-1B (INT4) achieves ROI break-even in 14 requests (median), delivers 3x higher energy-normalized intelligence than 7B models, and exceeds 6,900 tokens/s/GB under 4-bit quantization. We further uncover an efficiency anomaly-while QLoRA reduces memory footprint, it increases adaptation energy by up to 7x for small models-challenging prevailing assumptions about quantization-aware training in edge deployment.
LLM-Guided Semantic Bootstrapping for Interpretable Text Classification with Tsetlin Machines
Apr 14, 2026Pretrained language models (PLMs) like BERT provide strong semantic representations but are costly and opaque, while symbolic models such as the Tsetlin Machine (TM) offer transparency but lack semantic generalization. We propose a semantic bootstrapping framework that transfers LLM knowledge into symbolic form, combining interpretability with semantic capacity. Given a class label, an LLM generates sub-intents that guide synthetic data creation through a three-stage curriculum (seed, core, enriched), expanding semantic diversity. A Non-Negated TM (NTM) learns from these examples to extract high-confidence literals as interpretable semantic cues. Injecting these cues into real data enables a TM to align clause logic with LLM-inferred semantics. Our method requires no embeddings or runtime LLM calls, yet equips symbolic models with pretrained semantic priors. Across multiple text classification tasks, it improves interpretability and accuracy over vanilla TM, achieving performance comparable to BERT while remaining fully symbolic and efficient.
IndicFairFace: Balanced Indian Face Dataset for Auditing and Mitigating Geographical Bias in Vision-Language Models
Feb 13, 2026Vision-Language Models (VLMs) are known to inherit and amplify societal biases from their web-scale training data with Indian being particularly misrepresented. Existing fairness-aware datasets have significantly improved demographic balance across global race and gender groups, yet they continue to treat Indian as a single monolithic category. The oversimplification ignores the vast intra-national diversity across 28 states and 8 Union Territories of India and leads to representational and geographical bias. To address the limitation, we present IndicFairFace, a novel and balanced face dataset comprising 14,400 images representing geographical diversity of India. Images were sourced ethically from Wikimedia Commons and open-license web repositories and uniformly balanced across states and gender. Using IndicFairFace, we quantify intra-national geographical bias in prominent CLIP-based VLMs and reduce it using post-hoc Iterative Nullspace Projection debiasing approach. We also show that the adopted debiasing approach does not adversely impact the existing embedding space as the average drop in retrieval accuracy on benchmark datasets is less than 1.5 percent. Our work establishes IndicFairFace as the first benchmark to study geographical bias in VLMs for the Indian context.
They Said Memes Were Harmless-We Found the Ones That Hurt: Decoding Jokes, Symbols, and Cultural References
Feb 03, 2026Meme-based social abuse detection is challenging because harmful intent often relies on implicit cultural symbolism and subtle cross-modal incongruence. Prior approaches, from fusion-based methods to in-context learning with Large Vision-Language Models (LVLMs), have made progress but remain limited by three factors: i) cultural blindness (missing symbolic context), ii) boundary ambiguity (satire vs. abuse confusion), and iii) lack of interpretability (opaque model reasoning). We introduce CROSS-ALIGN+, a three-stage framework that systematically addresses these limitations: (1) Stage I mitigates cultural blindness by enriching multimodal representations with structured knowledge from ConceptNet, Wikidata, and Hatebase; (2) Stage II reduces boundary ambiguity through parameter-efficient LoRA adapters that sharpen decision boundaries; and (3) Stage III enhances interpretability by generating cascaded explanations. Extensive experiments on five benchmarks and eight LVLMs demonstrate that CROSS-ALIGN+ consistently outperforms state-of-the-art methods, achieving up to 17% relative F1 improvement while providing interpretable justifications for each decision.
Revealing the Truth with ConLLM for Detecting Multi-Modal Deepfakes
Jan 24, 2026The rapid rise of deepfake technology poses a severe threat to social and political stability by enabling hyper-realistic synthetic media capable of manipulating public perception. However, existing detection methods struggle with two core limitations: (1) modality fragmentation, which leads to poor generalization across diverse and adversarial deepfake modalities; and (2) shallow inter-modal reasoning, resulting in limited detection of fine-grained semantic inconsistencies. To address these, we propose ConLLM (Contrastive Learning with Large Language Models), a hybrid framework for robust multimodal deepfake detection. ConLLM employs a two-stage architecture: stage 1 uses Pre-Trained Models (PTMs) to extract modality-specific embeddings; stage 2 aligns these embeddings via contrastive learning to mitigate modality fragmentation, and refines them using LLM-based reasoning to address shallow inter-modal reasoning by capturing semantic inconsistencies. ConLLM demonstrates strong performance across audio, video, and audio-visual modalities. It reduces audio deepfake EER by up to 50%, improves video accuracy by up to 8%, and achieves approximately 9% accuracy gains in audio-visual tasks. Ablation studies confirm that PTM-based embeddings contribute 9%-10% consistent improvements across modalities.
Do Clinical Question Answering Systems Really Need Specialised Medical Fine Tuning?
Jan 19, 2026Clinical Question-Answering (CQA) industry systems are increasingly rely on Large Language Models (LLMs), yet their deployment is often guided by the assumption that domain-specific fine-tuning is essential. Although specialised medical LLMs such as BioBERT, BioGPT, and PubMedBERT remain popular, they face practical limitations including narrow coverage, high retraining costs, and limited adaptability. Efforts based on Supervised Fine-Tuning (SFT) have attempted to address these assumptions but continue to reinforce what we term the SPECIALISATION FALLACY-the belief that specialised medical LLMs are inherently superior for CQA. To address this assumption, we introduce MEDASSESS-X, a deployment-industry-oriented CQA framework that applies alignment at inference time rather than through SFT. MEDASSESS-X uses lightweight steering vectors to guide model activations toward medically consistent reasoning without updating model weights or requiring domain-specific retraining. This inference-time alignment layer stabilises CQA performance across both general-purpose and specialised medical LLMs, thereby resolving the SPECIALISATION FALLACY. Empirically, MEDASSESS-X delivers consistent gains across all LLM families, improving Accuracy by up to +6%, Factual Consistency by +7%, and reducing Safety Error Rate by as much as 50%.
S2D-ALIGN: Shallow-to-Deep Auxiliary Learning for Anatomically-Grounded Radiology Report Generation
Nov 14, 2025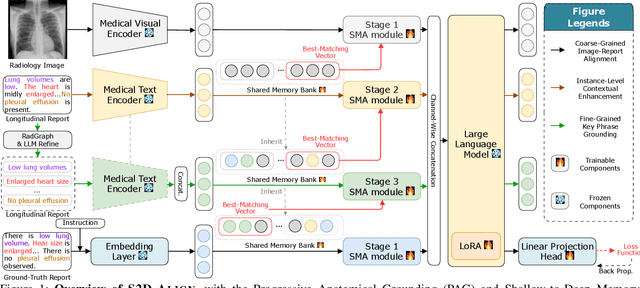
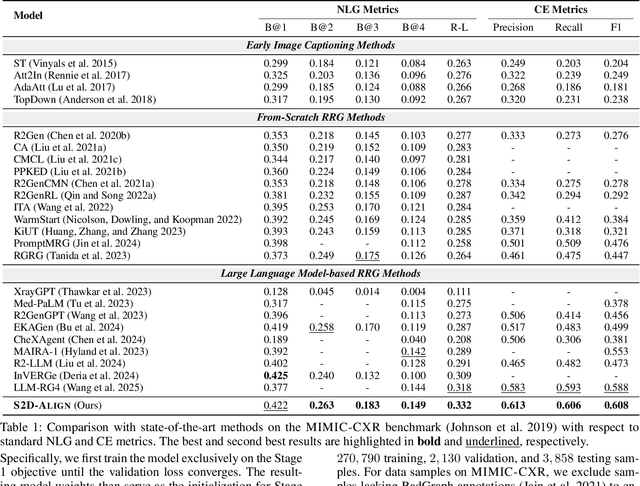
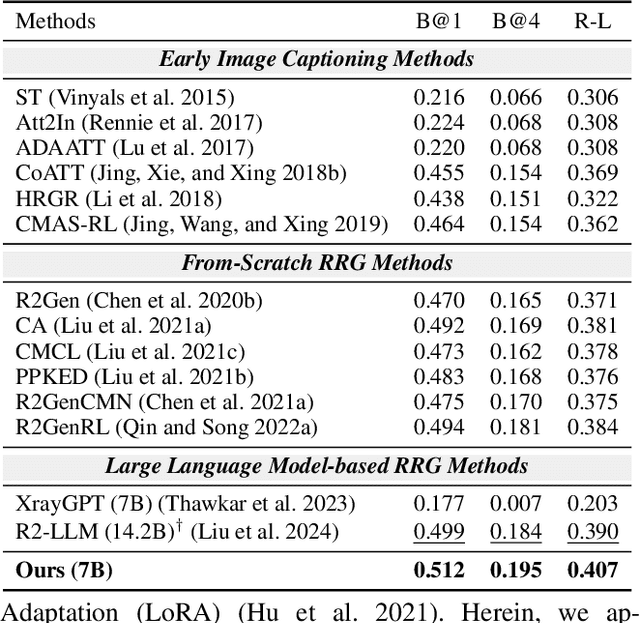
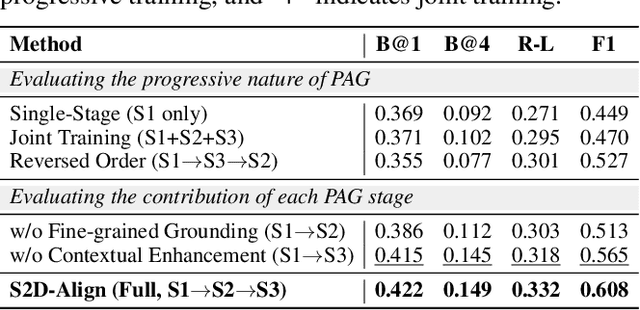
Radiology Report Generation (RRG) aims to automatically generate diagnostic reports from radiology images. To achieve this, existing methods have leveraged the powerful cross-modal generation capabilities of Multimodal Large Language Models (MLLMs), primarily focusing on optimizing cross-modal alignment between radiographs and reports through Supervised Fine-Tuning (SFT). However, by only performing instance-level alignment with the image-text pairs, the standard SFT paradigm fails to establish anatomically-grounded alignment, where the templated nature of reports often leads to sub-optimal generation quality. To address this, we propose \textsc{S2D-Align}, a novel SFT paradigm that establishes anatomically-grounded alignment by leveraging auxiliary signals of varying granularities. \textsc{S2D-Align} implements a shallow-to-deep strategy, progressively enriching the alignment process: it begins with the coarse radiograph-report pairing, then introduces reference reports for instance-level guidance, and ultimately utilizes key phrases to ground the generation in specific anatomical details. To bridge the different alignment stages, we introduce a memory-based adapter that empowers feature sharing, thereby integrating coarse and fine-grained guidance. For evaluation, we conduct experiments on the public \textsc{MIMIC-CXR} and \textsc{IU X-Ray} benchmarks, where \textsc{S2D-Align} achieves state-of-the-art performance compared to existing methods. Ablation studies validate the effectiveness of our multi-stage, auxiliary-guided approach, highlighting a promising direction for enhancing grounding capabilities in complex, multi-modal generation tasks.
FT-MDT: Extracting Decision Trees from Medical Texts via a Novel Low-rank Adaptation Method
Oct 06, 2025Knowledge of the medical decision process, which can be modeled as medical decision trees (MDTs), is critical to building clinical decision support systems. However, current MDT construction methods rely heavily on time-consuming and laborious manual annotation. To address this challenge, we propose PI-LoRA (Path-Integrated LoRA), a novel low-rank adaptation method for automatically extracting MDTs from clinical guidelines and textbooks. We integrate gradient path information to capture synergistic effects between different modules, enabling more effective and reliable rank allocation. This framework ensures that the most critical modules receive appropriate rank allocations while less important ones are pruned, resulting in a more efficient and accurate model for extracting medical decision trees from clinical texts. Extensive experiments on medical guideline datasets demonstrate that our PI-LoRA method significantly outperforms existing parameter-efficient fine-tuning approaches for the Text2MDT task, achieving better accuracy with substantially reduced model complexity. The proposed method achieves state-of-the-art results while maintaining a lightweight architecture, making it particularly suitable for clinical decision support systems where computational resources may be limited.