 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Opinion Dynamics Modeling with Neural Diffusion-Convection-Reaction Equation
Feb 05, 2026Advanced opinion dynamics modeling is vital for deciphering social behavior, emphasizing its role in mitigating polarization and securing cyberspace. To synergize mechanistic interpretability with data-driven flexibility, recent studies have explored the integration of Physics-Informed Neural Networks (PINNs) for opinion modeling. Despite this promise, existing methods are tailored to incomplete priors, lacking a comprehensive physical system to integrate dynamics from local, global, and endogenous levels. Moreover, penalty-based constraints adopted in existing methods struggle to deeply encode physical priors, leading to optimization pathologies and discrepancy between latent representations and physical transparency. To this end, we offer a physical view to interpret opinion dynamics via Diffusion-Convection-Reaction (DCR) system inspired by interacting particle theory. Building upon the Neural ODEs, we define the neural opinion dynamics to coordinate neural networks with physical priors, and further present the OPINN, a physics-informed neural framework for opinion dynamics modeling. Evaluated on real-world and synthetic datasets, OPINN achieves state-of-the-art performance in opinion evolution forecasting, offering a promising paradigm for the nexus of cyber, physical, and social systems.
TopoDIM: One-shot Topology Generation of Diverse Interaction Modes for Multi-Agent Systems
Jan 15, 2026Optimizing communication topology in LLM-based multi-agent system is critical for enabling collective intelligence. Existing methods mainly rely on spatio-temporal interaction paradigms, where the sequential execution of multi-round dialogues incurs high latency and computation. Motivated by the recent insights that evaluation and debate mechanisms can improve problem-solving in multi-agent systems, we propose TopoDIM, a framework for one-shot Topology generation with Diverse Interaction Modes. Designed for decentralized execution to enhance adaptability and privacy, TopoDIM enables agents to autonomously construct heterogeneous communication without iterative coordination, achieving token efficiency and improved task performance. Experiments demonstrate that TopoDIM reduces total token consumption by 46.41% while improving average performance by 1.50% over state-of-the-art methods. Moreover, the framework exhibits strong adaptability in organizing communication among heterogeneous agents. Code is available at: https://anonymous.4open.science/r/TopoDIM-8D35/
EpiLLM: Unlocking the Potential of Large Language Models in Epidemic Forecasting
May 19, 2025Advanced epidemic forecasting is critical for enabling precision containment strategies, highlighting its strategic importance for public health security. While recent advances in Large Language Models (LLMs) have demonstrated effectiveness as foundation models for domain-specific tasks, their potential for epidemic forecasting remains largely unexplored. In this paper, we introduce EpiLLM, a novel LLM-based framework tailored for spatio-temporal epidemic forecasting. Considering the key factors in real-world epidemic transmission: infection cases and human mobility, we introduce a dual-branch architecture to achieve fine-grained token-level alignment between such complex epidemic patterns and language tokens for LLM adaptation. To unleash the multi-step forecasting and generalization potential of LLM architectures, we propose an autoregressive modeling paradigm that reformulates the epidemic forecasting task into next-token prediction. To further enhance LLM perception of epidemics, we introduce spatio-temporal prompt learning techniques, which strengthen forecasting capabilities from a data-driven perspective. Extensive experiments show that EpiLLM significantly outperforms existing baselines on real-world COVID-19 datasets and exhibits scaling behavior characteristic of LLMs.
AutoCas: Autoregressive Cascade Predictor in Social Networks via Large Language Models
Feb 25, 2025Popularity prediction in information cascades plays a crucial role in social computing, with broad applications in viral marketing, misinformation control, and content recommendation. However, information propagation mechanisms, user behavior, and temporal activity patterns exhibit significant diversity, necessitating a foundational model capable of adapting to such variations. At the same time, the amount of available cascade data remains relatively limited compared to the vast datasets used for training large language models (LLMs). Recent studies have demonstrated the feasibility of leveraging LLMs for time-series prediction by exploiting commonalities across different time-series domains. Building on this insight, we introduce the Autoregressive Information Cascade Predictor (AutoCas), an LLM-enhanced model designed specifically for cascade popularity prediction. Unlike natural language sequences, cascade data is characterized by complex local topologies, diffusion contexts, and evolving dynamics, requiring specialized adaptations for effective LLM integration. To address these challenges, we first tokenize cascade data to align it with sequence modeling principles. Next, we reformulate cascade diffusion as an autoregressive modeling task to fully harness the architectural strengths of LLMs. Beyond conventional approaches, we further introduce prompt learning to enhance the synergy between LLMs and cascade prediction. Extensive experiments demonstrate that AutoCas significantly outperforms baseline models in cascade popularity prediction while exhibiting scaling behavior inherited from LLMs. Code is available at this repository: https://anonymous.4open.science/r/AutoCas-85C6
Adapting Large Language Models for Time Series Modeling via a Novel Parameter-efficient Adaptation Method
Feb 19, 2025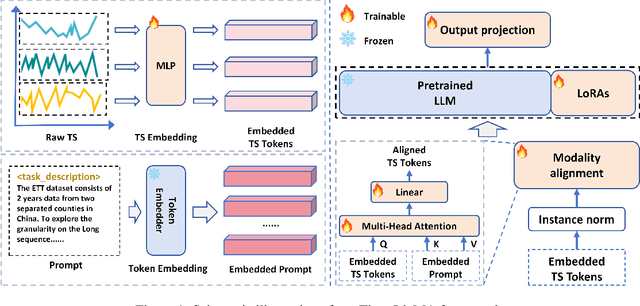
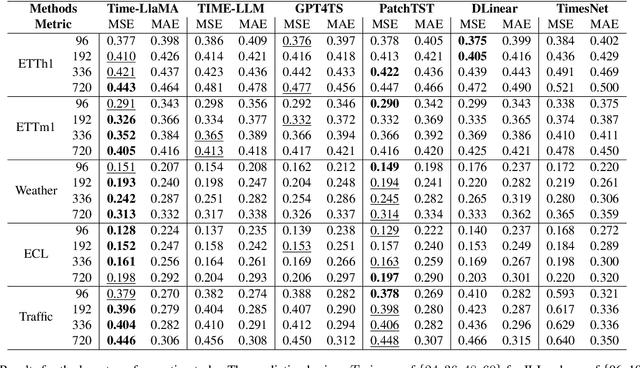
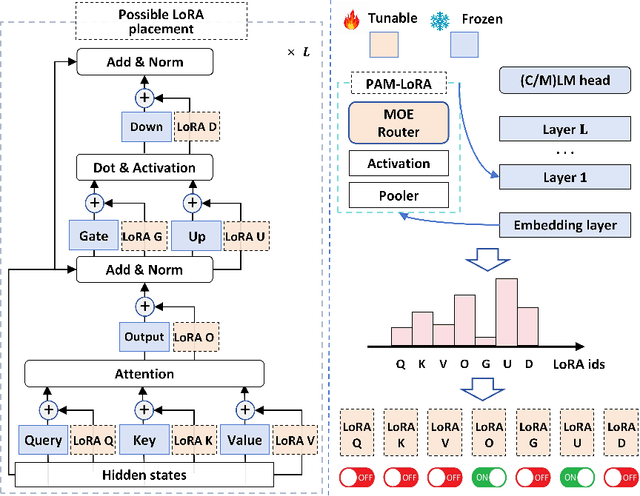
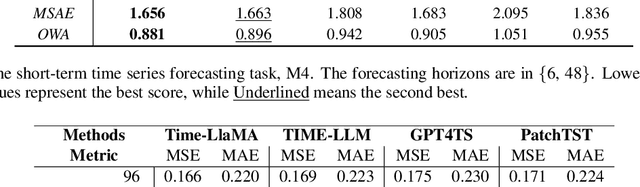
Time series modeling holds significant importance in many real-world applications and has been extensively studied. While pre-trained foundation models have made impressive strides in the fields of natural language processing (NLP) and computer vision (CV), their development in time series domains has been constrained by data sparsity. A series of recent studies have demonstrated that large language models (LLMs) possess robust pattern recognition and reasoning abilities over complex sequences of tokens. However, the current literature have yet striked a high-quality balance between (a) effectively aligning the time series and natural language modalities, and (b) keeping the inference efficiency. To address the above issues, we now propose the Time-LlaMA framework. Time-LlaMA first converts the time series input into token embeddings through a linear tokenization mechanism. Second, the time series token embeddings are aligned with the text prompts. Third, to further adapt the LLM backbone for time series modeling, we have developed a dynamic low-rank adaptation technique (D-LoRA). D-LoRA dynamically chooses the most suitable LoRA modules at each layer of the Transformer backbone for each time series input, enhancing the model's predictive capabilities. Our experimental results on an extensive collection of challenging real-world time series tasks confirm that our proposed method achieves the state-of-the-art (SOTA) performance.
Learning Novel Transformer Architecture for Time-series Forecasting
Feb 19, 2025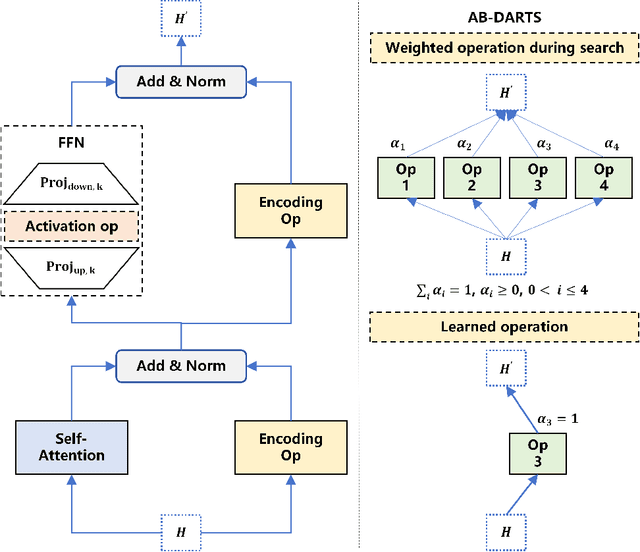

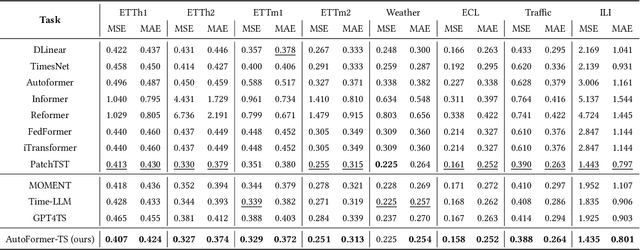
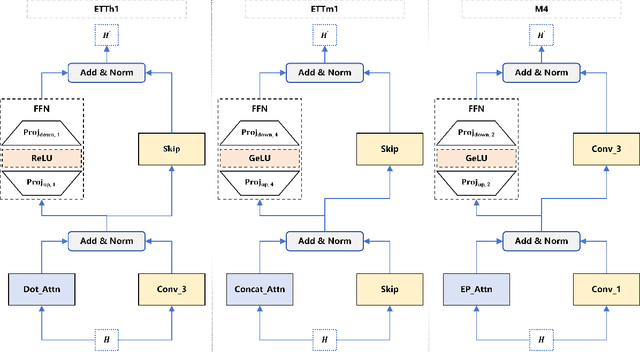
Despite the success of Transformer-based models in the time-series prediction (TSP) tasks, the existing Transformer architecture still face limitations and the literature lacks comprehensive explorations into alternative architectures. To address these challenges, we propose AutoFormer-TS, a novel framework that leverages a comprehensive search space for Transformer architectures tailored to TSP tasks. Our framework introduces a differentiable neural architecture search (DNAS) method, AB-DARTS, which improves upon existing DNAS approaches by enhancing the identification of optimal operations within the architecture. AutoFormer-TS systematically explores alternative attention mechanisms, activation functions, and encoding operations, moving beyond the traditional Transformer design. Extensive experiments demonstrate that AutoFormer-TS consistently outperforms state-of-the-art baselines across various TSP benchmarks, achieving superior forecasting accuracy while maintaining reasonable training efficiency.