 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Planning Abilities of Large Language Models
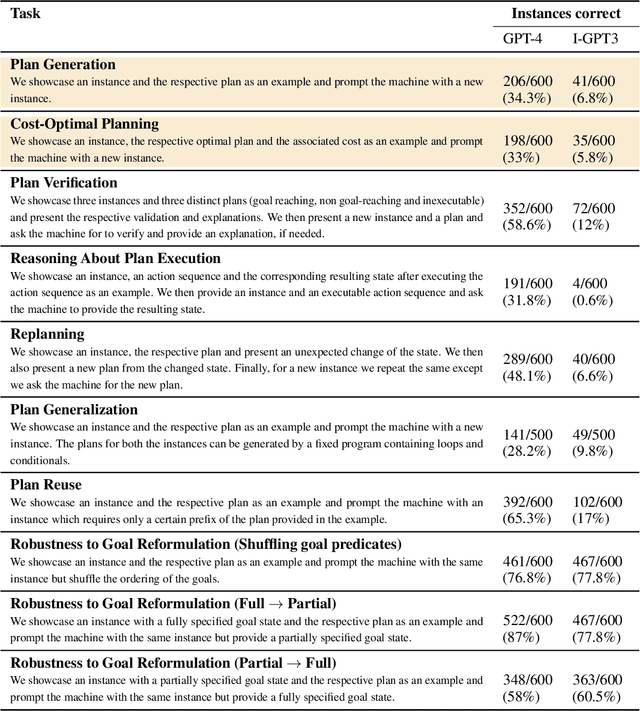
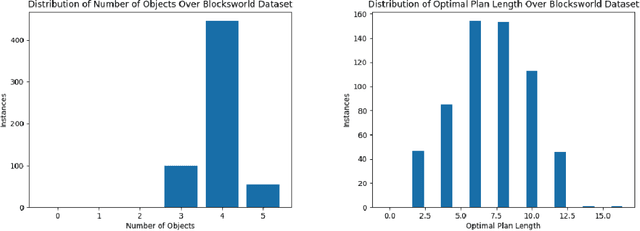
Feb 13, 2023Intrigued by the claims of emergent reasoning capabilities in LLMs trained on general web corpora, in this paper, we set out to investigate their planning capabilities. We aim to evaluate (1) how good LLMs are by themselves in generating and validating simple plans in commonsense planning tasks (of the type that humans are generally quite good at) and (2) how good LLMs are in being a source of heuristic guidance for other agents--either AI planners or human planners--in their planning tasks. To investigate these questions in a systematic rather than anecdotal manner, we start by developing a benchmark suite based on the kinds of domains employed in the International Planning Competition. On this benchmark, we evaluate LLMs in three modes: autonomous, heuristic and human-in-the-loop. Our results show that LLM's ability to autonomously generate executable plans is quite meager, averaging only about 3% success rate. The heuristic and human-in-the-loop modes show slightly more promise. In addition to these results, we also make our benchmark and evaluation tools available to support investigations by research community.
Large Language Models Still Can't Plan
Jun 21, 2022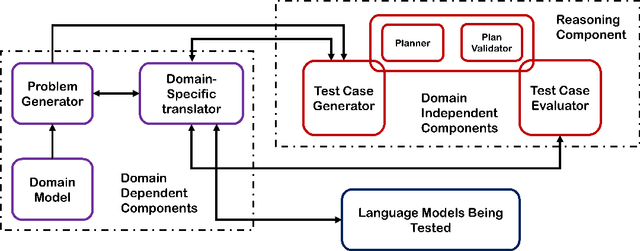

The recent advances in large language models (LLMs) have transformed the field of natural language processing (NLP). From GPT-3 to PaLM, the state-of-the-art performance on natural language tasks is being pushed forward with every new large language model. Along with natural language abilities, there has been a significant interest in understanding whether such models, trained on enormous amounts of data, exhibit reasoning capabilities. Hence there has been interest in developing benchmarks for various reasoning tasks and the preliminary results from testing LLMs over such benchmarks seem mostly positive. However, the current benchmarks are relatively simplistic and the performance over these benchmarks cannot be used as an evidence to support, many a times outlandish, claims being made about LLMs' reasoning capabilities. As of right now, these benchmarks only represent a very limited set of simple reasoning tasks and we need to look at more sophisticated reasoning problems if we are to measure the true limits of such LLM-based systems. With this motivation, we propose an extensible assessment framework to test the abilities of LLMs on a central aspect of human intelligence, which is reasoning about actions and change. We provide multiple test cases that are more involved than any of the previously established reasoning benchmarks and each test case evaluates a certain aspect of reasoning about actions and change. Initial evaluation results on the base version of GPT-3 (Davinci), showcase subpar performance on these benchmarks.
GPT3-to-plan: Extracting plans from text using GPT-3
Jun 14, 2021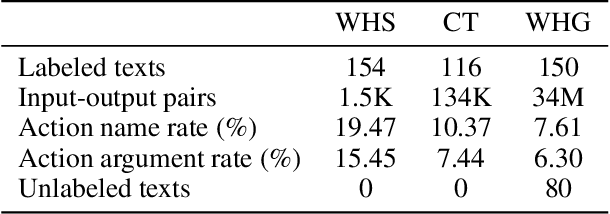
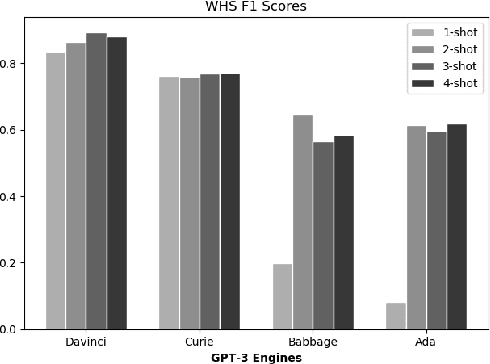

Operations in many essential industries including finance and banking are often characterized by the need to perform repetitive sequential tasks. Despite their criticality to the business, workflows are rarely fully automated or even formally specified, though there may exist a number of natural language documents describing these procedures for the employees of the company. Plan extraction methods provide us with the possibility of extracting structure plans from such natural language descriptions of the plans/workflows, which could then be leveraged by an automated system. In this paper, we investigate the utility of generalized language models in performing such extractions directly from such texts. Such models have already been shown to be quite effective in multiple translation tasks, and our initial results seem to point to their effectiveness also in the context of plan extractions. Particularly, we show that GPT-3 is able to generate plan extraction results that are comparable to many of the current state of the art plan extraction methods.
Not all Failure Modes are Created Equal: Training Deep Neural Networks for Explicable Classification
Jun 26, 2020
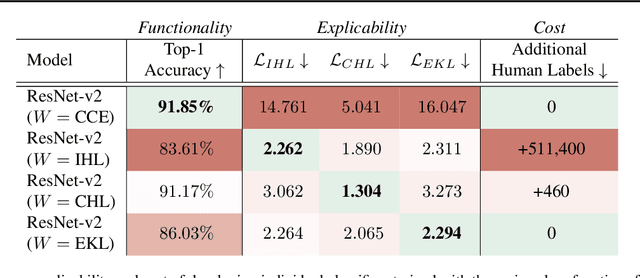


Deep Neural Networks are often brittle on image classification tasks and known to misclassify inputs. While these misclassifications may be inevitable, all failure modes cannot be considered equal. Certain misclassifications (eg. classifying the image of a dog to an airplane) can create surprise and result in the loss of human trust in the system. Even worse, certain errors (eg. a person misclassified as a primate) can have societal impacts. Thus, in this work, we aim to reduce inexplicable errors. To address this challenge, we first discuss how to obtain the class-level semantics that captures the human's expectation ($M^h$) regarding which classes are semantically close vs. ones that are far away. We show that for data-sets like CIFAR-10 and CIFAR-100, class-level semantics can be obtained by leveraging human subject studies (significantly inexpensive compared to existing works) and, whenever possible, by utilizing publicly available human-curated knowledge. Second, we propose the use of Weighted Loss Functions to penalize misclassifications by the weight of their inexplicability. Finally, we show that training (or even fine-tuning) existing classifiers with the two proposed methods lead to Deep Neural Networks that have (1) comparable top-1 accuracy, an important metric in operational contexts, (2) more explicable failure modes and (3) require significantly less cost in teams of additional human labels compared to existing work.
Imperfect ImaGANation: Implications of GANs Exacerbating Biases on Facial Data Augmentation and Snapchat Selfie Lenses
Jan 26, 2020
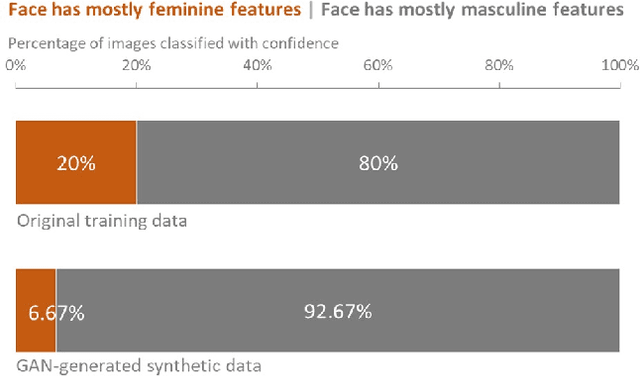
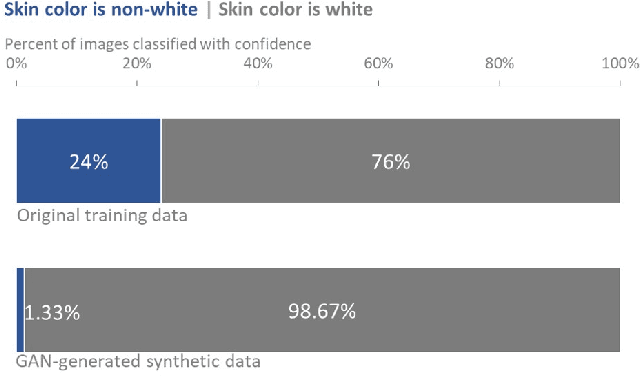
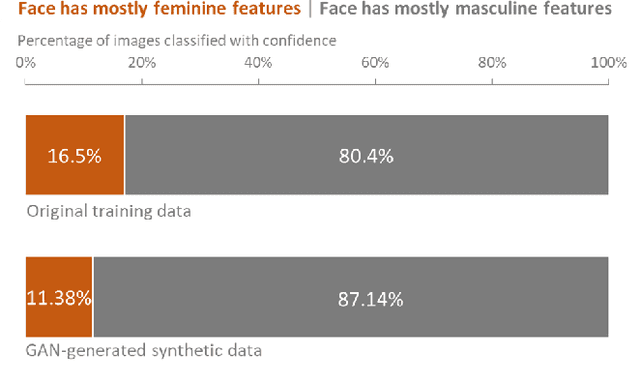
Recently, the use of synthetic data generated by GANs has become a popular method to do data augmentation for many applications. While practitioners celebrate this as an economical way to obtain synthetic data for training data-hungry machine learning models, it is not clear that they recognize the perils of such an augmentation technique when applied to an already-biased dataset. Although one expects GANs to replicate the distribution of the original data, in real-world settings with limited data and finite network capacity, GANs suffer from mode collapse. Especially when this data is coming from online social media platforms or the web which are never balanced. In this paper, we show that in settings where data exhibits bias along some axes (eg. gender, race), failure modes of Generative Adversarial Networks (GANs) exacerbate the biases in the generated data. More often than not, this bias is unavoidable; we empirically demonstrate that given input of a dataset of headshots of engineering faculty collected from 47 online university directory webpages in the United States is biased toward white males, a state-of-the-art (unconditional variant of) GAN "imagines" faces of synthetic engineering professors that have masculine facial features and white skin color (inferred using human studies and a state-of-the-art gender recognition system). We also conduct a preliminary case study to highlight how Snapchat's explosively popular "female" filter (widely accepted to use a conditional variant of GAN), ends up consistently lightening the skin tones in women of color when trying to make face images appear more feminine. Our study is meant to serve as a cautionary tale for the lay practitioners who may unknowingly increase the bias in their training data by using GAN-based augmentation techniques with web data and to showcase the dangers of using biased datasets for facial applications.
Model-Free Model Reconciliation
Mar 17, 2019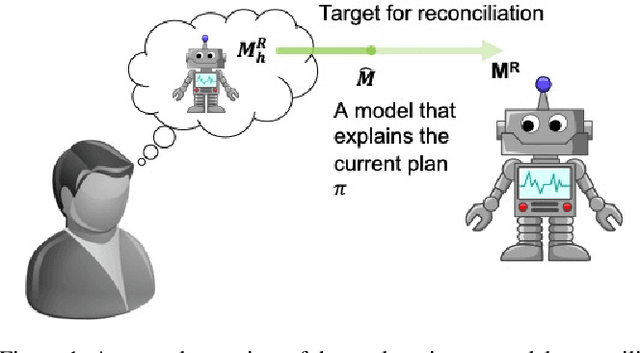
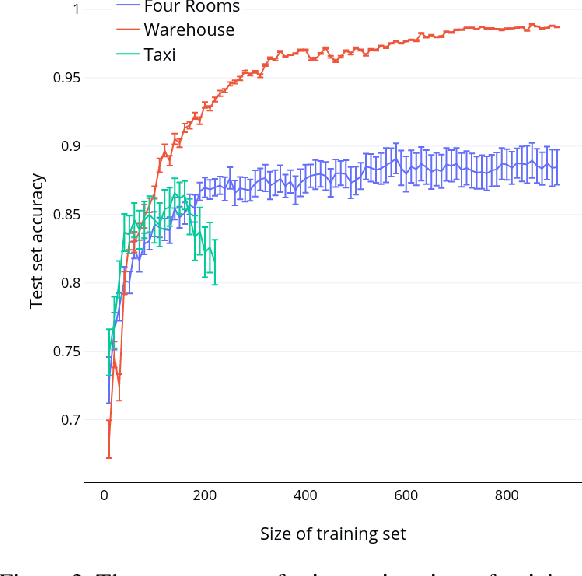
Designing agents capable of explaining complex sequential decisions remain a significant open problem in automated decision-making. Recently, there has been a lot of interest in developing approaches for generating such explanations for various decision-making paradigms. One such approach has been the idea of {\em explanation as model-reconciliation}. The framework hypothesizes that one of the common reasons for the user's confusion could be the mismatch between the user's model of the task and the one used by the system to generate the decisions. While this is a general framework, most works that have been explicitly built on this explanatory philosophy have focused on settings where the model of user's knowledge is available in a declarative form. Our goal in this paper is to adapt the model reconciliation approach to the cases where such user models are no longer explicitly provided. We present a simple and easy to learn labeling model that can help an explainer decide what information could help achieve model reconciliation between the user and the agent.