 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Still Can't Plan
Paper and Code
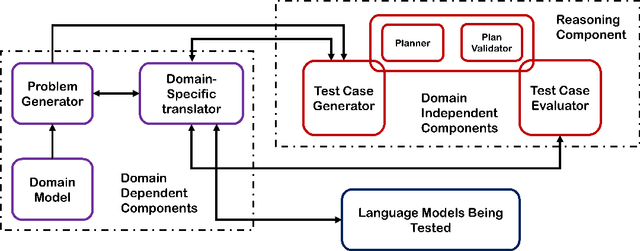
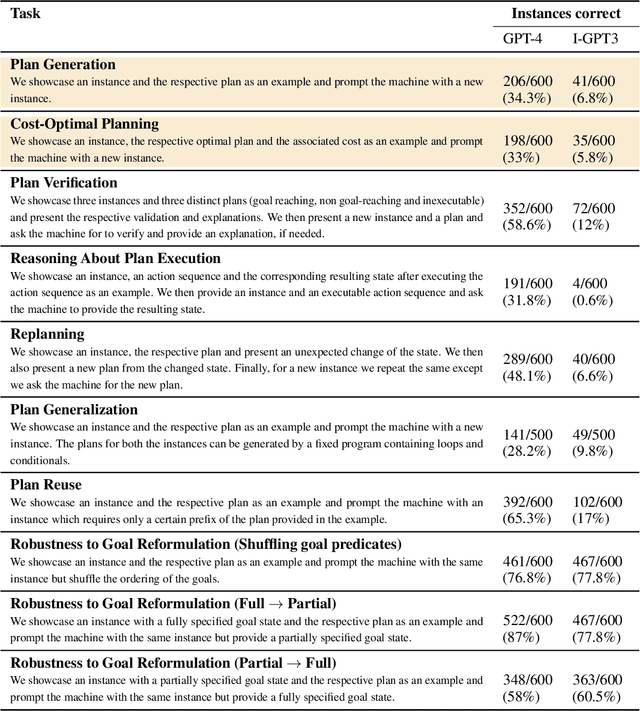
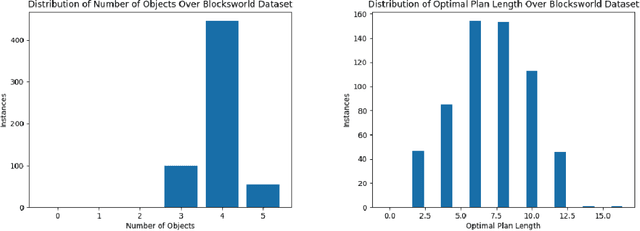

The recent advances in large language models (LLMs) have transformed the field of natural language processing (NLP). From GPT-3 to PaLM, the state-of-the-art performance on natural language tasks is being pushed forward with every new large language model. Along with natural language abilities, there has been a significant interest in understanding whether such models, trained on enormous amounts of data, exhibit reasoning capabilities. Hence there has been interest in developing benchmarks for various reasoning tasks and the preliminary results from testing LLMs over such benchmarks seem mostly positive. However, the current benchmarks are relatively simplistic and the performance over these benchmarks cannot be used as an evidence to support, many a times outlandish, claims being made about LLMs' reasoning capabilities. As of right now, these benchmarks only represent a very limited set of simple reasoning tasks and we need to look at more sophisticated reasoning problems if we are to measure the true limits of such LLM-based systems. With this motivation, we propose an extensible assessment framework to test the abilities of LLMs on a central aspect of human intelligence, which is reasoning about actions and change. We provide multiple test cases that are more involved than any of the previously established reasoning benchmarks and each test case evaluates a certain aspect of reasoning about actions and change. Initial evaluation results on the base version of GPT-3 (Davinci), showcase subpar performance on these benchmarks.