 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperfect ImaGANation: Implications of GANs Exacerbating Biases on Facial Data Augmentation and Snapchat Selfie Lenses
Paper and Code

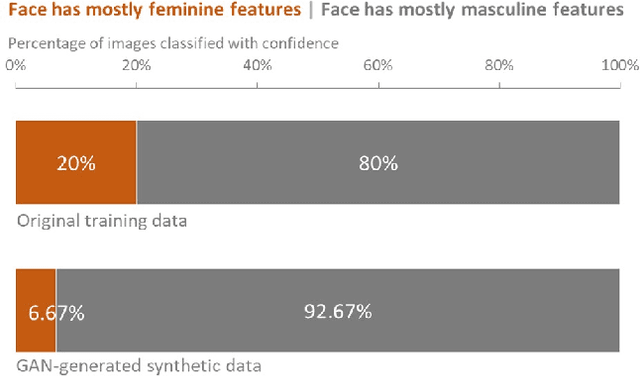
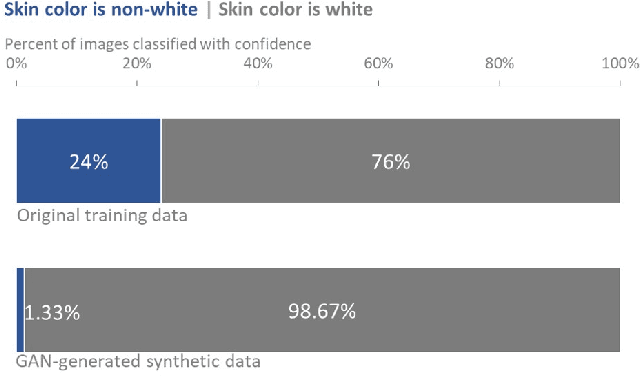
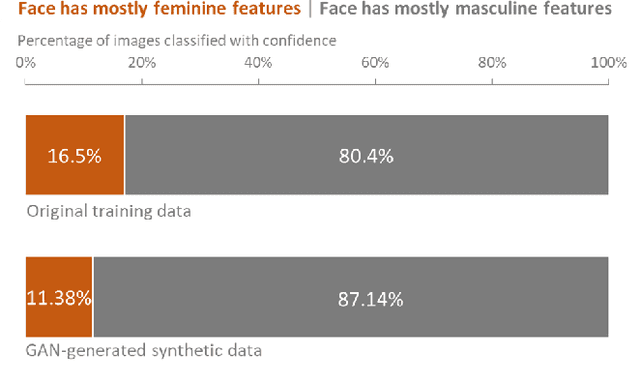
Recently, the use of synthetic data generated by GANs has become a popular method to do data augmentation for many applications. While practitioners celebrate this as an economical way to obtain synthetic data for training data-hungry machine learning models, it is not clear that they recognize the perils of such an augmentation technique when applied to an already-biased dataset. Although one expects GANs to replicate the distribution of the original data, in real-world settings with limited data and finite network capacity, GANs suffer from mode collapse. Especially when this data is coming from online social media platforms or the web which are never balanced. In this paper, we show that in settings where data exhibits bias along some axes (eg. gender, race), failure modes of Generative Adversarial Networks (GANs) exacerbate the biases in the generated data. More often than not, this bias is unavoidable; we empirically demonstrate that given input of a dataset of headshots of engineering faculty collected from 47 online university directory webpages in the United States is biased toward white males, a state-of-the-art (unconditional variant of) GAN "imagines" faces of synthetic engineering professors that have masculine facial features and white skin color (inferred using human studies and a state-of-the-art gender recognition system). We also conduct a preliminary case study to highlight how Snapchat's explosively popular "female" filter (widely accepted to use a conditional variant of GAN), ends up consistently lightening the skin tones in women of color when trying to make face images appear more feminine. Our study is meant to serve as a cautionary tale for the lay practitioners who may unknowingly increase the bias in their training data by using GAN-based augmentation techniques with web data and to showcase the dangers of using biased datasets for facial applications.